
【論文瞬読】強化学習で進化する言語モデルの推論能力:DeepSeek-R1の挑戦

はじめに
こんにちは!株式会社AI Nestです。
大規模言語モデル(LLM)の進化が続く中、推論能力の向上は重要な課題として注目されています。今回は、強化学習を活用して推論能力を大幅に向上させた研究をご紹介します。
タイトル:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL:https://arxiv.org/abs/2501.12948
所属:DeepSeek-AI
著者:DeepSeek-AI Team
革新的なアプローチ:教師なし強化学習
従来のLLMは、教師あり学習データに大きく依存していましたが、本研究では強化学習(RL)のみを用いた画期的なアプローチを実現しました。
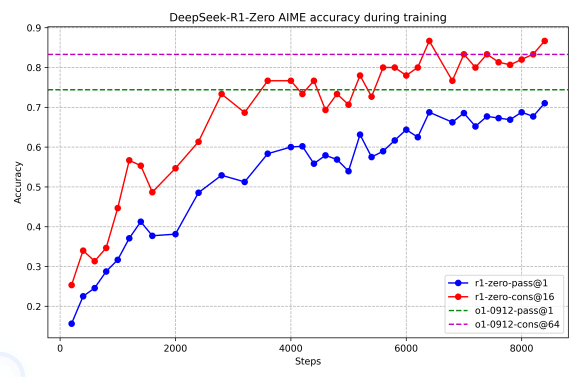
DeepSeek-R1-Zeroの特徴
教師データなしで強化学習を直接適用
数学やコーディング課題での高い性能
長時間の思考プロセスを自然に獲得
進化したDeepSeek-R1
DeepSeek-R1-Zeroの成功を踏まえ、さらなる改良を加えたDeepSeek-R1では:
コールドスタートデータの活用
多段階訓練パイプライン
人間の選好に基づく調整
という改良により、より実用的なモデルへと進化しました。
驚異的なベンチマーク結果

特筆すべき結果:
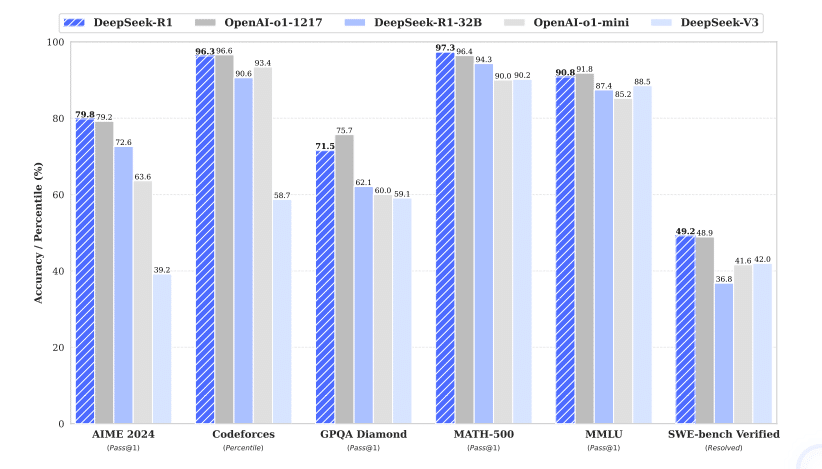
AIME 2024: 79.8% (OpenAI-o1-1217と同等)
MATH-500: 97.3% (最高性能)
Codeforces: 96.3パーセンタイル (人間のトップ級)
小規模モデルへの知識蒸留
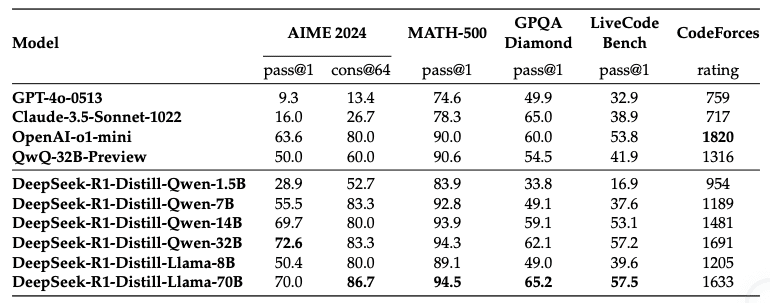
研究チームは、大規模モデルの能力を小規模モデルに効率的に転移する手法も開発しました:
1.5BパラメータモデルでもGPT-4を上回る数学性能
32Bモデルでo1-miniに匹敵する総合性能
今後の展望と課題
依然として以下の課題が残されています:
言語混合の問題
プロンプト感度の高さ
ソフトウェアエンジニアリングタスクでの改善余地
しかし、教師なし強化学習による推論能力の向上という新たな可能性を示した意義は大きいと言えるでしょう。
まとめ
本研究は、強化学習のみで言語モデルの推論能力を向上させられることを実証し、より効率的なAI開発への新たな道を示しました。今後の発展が非常に楽しみな研究分野と言えるでしょう。