
【論文瞬読】Mambaが変える言語モデルの未来:トランスフォーマーからの知識転移革命

みなさん、こんにちは!株式会社AI Nest です。今日は、言語モデルの世界に革命を起こしそうな超興味深い研究について紹介します。「The Mamba in the Llama: Distilling and Accelerating Hybrid Models」という論文を読んで、正直ワクワクが止まりません!AIの未来が、ここから大きく変わるかもしれないんです。
タイトル:The Mamba in the Llama: Distilling and Accelerating Hybrid Models
URL:https://arxiv.org/abs/2408.15237
所属:Cornell University, University of Geneva, Together AI, Princeton University
著者:Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao
何がすごいの?
まず、この研究のすごいところを簡単に説明しましょう:
トランスフォーマーモデル(例:GPT系)の知識を、Mambaという超効率的なモデルにtransferできる!
性能はほぼ同じなのに、推論速度が大幅アップ!
長い文章を扱う時に特に効果を発揮する!
既存のモデルの知識を活用しつつ、新しいアーキテクチャの利点を最大限に引き出している!
技術的なポイント:深掘り編
ここからは少し技術的な話になりますが、興味深いポイントがたくさんあるんです。AIやディープラーニングに詳しい方は特に注目してください!

オレンジ色の重みは、トランスフォーマーから初期化される
(Q、K、Vの線形射影は、それぞれC、B、Xの線形射影を使って初期化される)
個々の注目ヘッドをMambaヘッドに置き換え、
MLPブロックを凍結させながらMambaブロックを微調整する
形状は主に同じにしてある
緑色の重みが追加されている
学習された A と∆のパラメータには新しいパラメータが導入されている
Mambaの秘密:線形RNNの魅力
Mambaは線形RNN(Recurrent Neural Network)の一種です。でも、普通のRNNとは一味違います。特徴的なのは:
選択的状態空間: 入力に応じて動的に状態を更新できる。これにより、長期依存関係をより効果的に捉えられます。
線形時間複雑性: シーケンスの長さに対して線形の計算量。つまり、長い文章でも効率的に処理できるんです。
ハードウェアフレンドリー: GPUなどの現代的なハードウェアで高速に動作するように設計されています。
蒸留のプロセス:詳細編
研究チームの提案する蒸留プロセスは、実はかなり洗練されています。
進行的蒸留: まず、トランスフォーマーの半分の層をMambaに置き換え、そこから徐々にMamba層の割合を増やしていきます。これにより、段階的に知識を転移できるんです。
教師あり微調整: 通常の言語モデリングタスクだけでなく、指示に従うタスクでも微調整を行います。これにより、チャットボットのような応用にも対応できるようになります。
指向性選好最適化: これは最新の技術で、モデルの出力を人間の選好に合わせて最適化します。具体的には、Direct Preference Optimization (DPO) という手法を使っているそうです。

推論の高速化:推論的デコーディングの魔法
さらに面白いのが、推論高速化のためのアルゴリズムです。


マルチステップカーネル: 複数のトークンを一度に生成し、検証します。これにより、1トークンずつ生成するよりも高速に処理できます。
キャッシュ戦略: RNNの状態を効率的にキャッシュし、必要に応じて再計算します。これにより、メモリ使用量を抑えつつ、高速な推論が可能になります。
ハードウェア最適化: GPUの特性を考慮したアルゴリズム設計により、理論上の速度向上を実際のハードウェアで実現しています。
なぜこれがすごいのか?

効率性の革命: 長い文章を処理する時、従来のモデルはメモリを大量に使って遅くなりがちでした。Mambaはこの問題を解決し、長文処理の新たな地平を開く可能性があります。
知識の継承と革新: ゼロから学習し直すのではなく、既存モデルの知識を活用しつつ、新しいアーキテクチャの利点を取り入れています。これは、人間の「学び方」にも通じる、効率的な知識獲得の方法と言えるでしょう。
実用性の飛躍的向上: 性能を落とさずに効率化できるということは、実世界のアプリケーションにおいて革命的な変化をもたらす可能性があります。例えば:
モバイルデバイスでのリアルタイム翻訳
長文ドキュメントの即時要約
より自然で文脈を理解したチャットボット
環境負荷の軽減: 効率的なモデルは、計算リソースとエネルギー消費の削減につながります。これは、AI技術の持続可能性という観点からも非常に重要です。
実験結果:数字で見る革新性
論文では、様々なベンチマークで評価を行っています。特に印象的だったのは:
MT-Benchでのスコア: Llama-3 8Bの蒸留モデルが7.35を達成。元のモデル(8.00)に迫る性能です。
AlpacaEvalでの結果: 蒸留モデルが29.61%のwin rateを達成。これは元のモデルを上回る成績です。
推論速度: 純粋なMambaモデルで、最大2.6倍の高速化を実現。
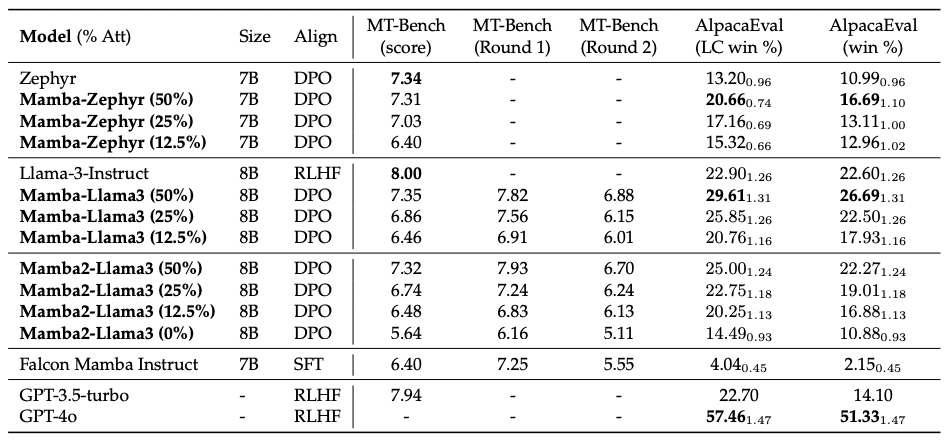


これらの数字は、提案手法の有効性を如実に示しています。
個人的な感想と未来への展望
正直、この研究を読んでテンションが上がりました!AIの世界って日進月歩ですが、この研究は特に画期的だと感じます。
特に注目したいのは、既存の知識を新しいアーキテクチャに移す方法です。これって、人間の学習にも応用できる考え方かもしれません。「効率的に学ぶ」ということの本質を、AIの研究から学べるかもしれないんですよね。

また、この技術が成熟すれば、私たちの日常生活にもすぐに影響を与えそうです。例えば:
スマートフォンでより高度な言語処理が可能に
ウェアラブルデバイスでのリアルタイム翻訳
大量のドキュメントを瞬時に分析するビジネスツール
より自然で文脈を理解した家庭用AIアシスタント
さらに、この研究のアプローチは言語モデル以外のAI分野にも応用できる可能性があります。画像認識や音声処理など、他の分野でも同様の効率化が実現できるかもしれませんね!