
【論文瞬読】BoostStep:LLMの数学力を"ステップ"で底上げする新手法

こんにちは!株式会社AI Nestです。大規模言語モデル(LLM)は様々なタスクで人間に近い、あるいは人間を超える性能を示すようになってきました。しかし、数学的推論は依然として大きな課題の一つとして残されています。特に複雑な数学問題では、人間のような step-by-step の論理的思考が必要とされますが、これをLLMで実現することは容易ではありません。
今回は、LLMの数学的推論能力を効果的に向上させる新手法「BoostStep」をご紹介します。この手法は、人間が数学を学ぶときのように、具体例を参考にしながら一歩一歩確実に解を導いていく、という考え方に基づいています。
タイトル:BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning
URL:https://arxiv.org/abs/2501.03226
所属:Shanghai AI Laboratory, Shanghai Jiao Tong University, The Chinese University of Hong Kong
著者:Beichen Zhang, Yuhong Liu, Xiaoyi Dong, et al.
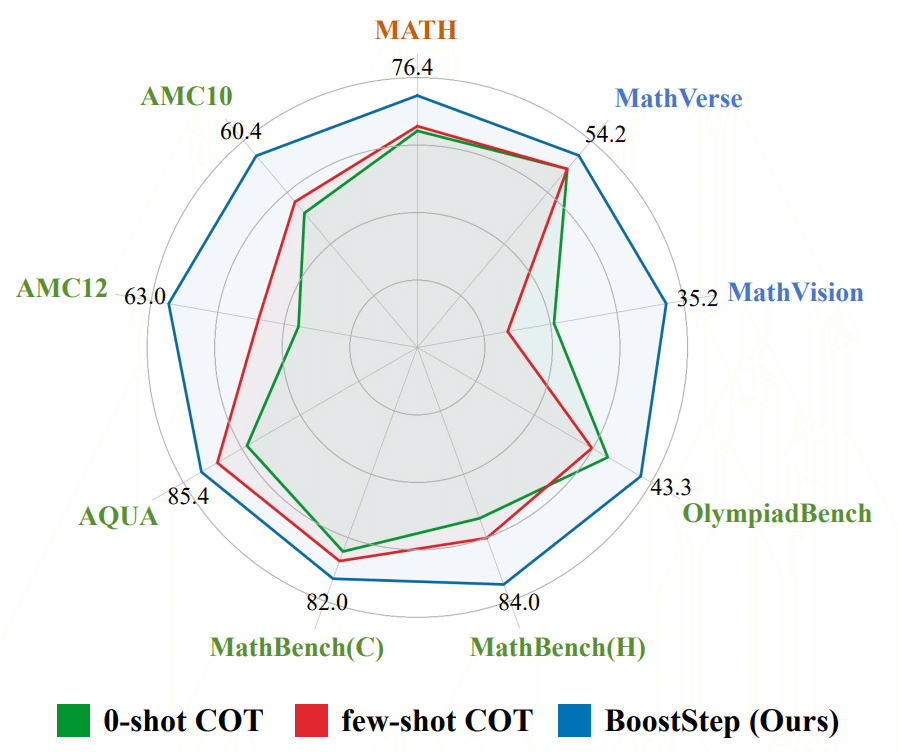
図1が示すように、BoostStepは様々な数学的ベンチマークにおいて既存手法を上回る性能を達成しています。特に、AMC12やAMC10といった高度な数学コンテストの問題でも着実な改善を見せています。
LLMの数学的推論における課題
LLMの数学的推論能力を詳しく分析すると、興味深い特徴が見えてきます。LLMの推論プロセスには大きく分けて2つの要素があります:
問題を小さなステップに分解する能力(divide)
複雑な問題を、より単純な部分問題に分割する能力です。例えば、面積を求める問題を「図形を基本要素に分解」→「各要素の面積を計算」→「結果を合算」といったステップに分けることができます。各ステップでの正確な推論能力(conquer)
分割された各ステップで、正しい数式や定理を適用し、計算を行う能力です。
研究チームの詳細な分析によると、最新のLLMは問題の分解自体は人間に近いレベルで実行できているものの、各ステップでの具体的な推論で誤りを犯すことが多いことが分かっています。例えば、三角関数の公式を間違えて適用したり、計算の途中で符号を取り違えたりといったミスが発生します。
さらに、従来の手法では、問題全体に対して参考例を提示する方法(問題レベルのin-context learning)が一般的でした。しかし、この方法には以下のような問題がありました:
提示された例題が、現在直面している具体的なステップとは関係のない情報を多く含んでいる
不適切な例が逆に推論を妨げる可能性がある
問題全体の類似性が低い場合、有効な例を見つけることが困難
BoostStepの革新的アプローチ
BoostStepは、これらの課題に対して「ステップレベルでの例示学習」という新しいアプローチを提案します。この手法の核となる考え方は、「各ステップで必要な推論に最適化された例を動的に提供する」というものです。

図3に示すように、一見まったく異なる問題でも、個々の解法ステップには共通点が存在します。例えば、最小公倍数を求める問題と、整除性を判定する問題では、「素因数分解を行う」という共通のステップが含まれることがあります。BoostStepはこの特徴を活用し、各推論ステップに最適な例を提供します。
First-try戦略の詳細
BoostStepの特徴的な機能の一つが「first-try戦略」です。この戦略は以下のような流れで実行されます:
モデルに次のステップの推論を試みさせる
これにより、モデルが現在どのような推論を行おうとしているのかを把握します。試行内容に基づいて、適切な例を検索
最初の試行から、現在のステップで必要とされている推論パターンを特定し、データベースから最適な例を検索します。例を参考に、より正確な推論を実施
検索された例を参考にしながら、最終的な推論を行います。

Figure 4は、この戦略が実際にどのように機能するかを示しています。この例では、最初の試行で三角関数の公式を誤って適用していましたが、適切な例の提示により正しい公式の使用に修正されています。
例題データベースの構築
BoostStepのもう一つの重要な要素が、適切な粒度で構築された例題データベースです。従来の多くの数学問題データセットは、問題文と解答、あるいは問題文と詳細な解説という形式でした。しかし、BoostStepでは、各解説を意味のある最小単位のステップに分解し、それぞれのステップに適切なタグ付けを行っています。
この際、単純な文法的な区切り(例:ピリオドでの分割)ではなく、推論の意味的なまとまりを考慮した分割を行っています。これにより、より自然な形での例示が可能になっています。
実験結果と評価
BoostStepの効果は、複数の側面から確認されています:
基本性能の向上
GPT-4oで3.6%の改善
Qwen2.5-Math-72Bで2.0%の改善
一見小さな改善に見えるかもしれませんが、これらは既に高い性能を持つモデルでの改善であり、また、数学的推論という難しいタスクでの改善であることを考えると、非常に意義のある結果と言えます。
MCTSとの統合による相乗効果
Monte Carlo Tree Search(MCTS)は、複数の推論パスを探索することで最適な解答を見つけ出す手法です。BoostStepはこのMCTSと組み合わせることで、さらなる性能向上を達成しています:
MCTSとの組み合わせで7.5%の性能向上
推論パスの生成精度の向上
各ステップの評価精度の改善
汎用性の高さ
特に注目すべき点は、例題との類似性が低い問題でも性能向上が見られることです。例えば、数式と図形を組み合わせた問題(MathVision)でも、着実な改善が確認されています。これは、ステップレベルでの例示が、問題全体の類似性に依存せずに機能することを示しています。
まとめと今後の展望
BoostStepは、LLMの数学的推論能力を向上させる効果的な手法として注目されます。特に以下の点が重要です:
ステップレベルでの細かい制御による精度向上
既存手法(MCTS等)との優れた相性
問題の類似性への依存度の低さ
今後の発展としては、以下のような方向性が期待されます:
より多様な数学問題への適用
現在のベンチマークをさらに拡張し、より幅広い数学分野での有効性を検証することが考えられます。他の推論タスクへの応用
数学的推論で実証された手法を、論理的推論や科学的推論など、他の分野に応用していく可能性があります。例題データベースの拡充
より多様で質の高い例題を収集し、データベースを充実させることで、さらなる性能向上が期待できます。
BoostStepは、LLMに「人間らしい」step-by-step の推論を可能にする重要な一歩と言えるでしょう。今後の発展が大いに期待される研究分野です。