
【論文瞬読】次世代AI評価の最前線:HLEで見るLLMの現状と課題

こんにちは!株式会社AI Nestです。
近年、急速に進化する大規模言語モデル(LLM)の能力を正確に評価するためのベンチマークが、研究者や実務家の間で大きな関心を集めています。しかし、従来のベンチマークでは、最新モデルがほぼ完璧なスコアを叩き出すため、真に求められる「実力のギャップ」を捉えることが難しくなっています。そこで登場したのが、「HUMANITY’S LAST EXAM(HLE)」です。HLEは、従来の評価手法の限界を克服し、LLMの深層的な理解力や推論力を厳しく試すために設計された新たなベンチマークです。
タイトル: Humanity’s Last Exam
URL: https://arxiv.org/abs/2501.14249
所属: Center for AI Safety, Scale AI
著者: Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, 他多数
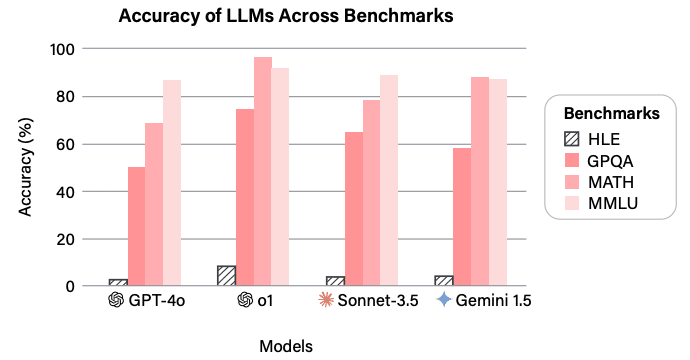
従来モデルの飽和状態とHLEの挑戦的な性質を視覚的に表現しています
図1に示されている通り、従来の評価基準では90%以上の正答率が一般的ですが、HLEに挑戦する先端モデルは依然として低いスコアに留まっています。これは、HLEがいかに厳密で挑戦的な設問で構成されているかを物語っています。
HUMANITY’S LAST EXAMの概要
HLEは、専門家によって厳選された2,700問の問題から構成されており、数学、物理、化学、文学、歴史など、100以上の学問分野を網羅しています。各問題は、単に知識の暗記ではなく、深い推論と高度な理解を要求する内容となっており、解答の正確性が厳格に求められています。また、テキストのみならず、画像を組み合わせたマルチモーダルな問題も含まれているため、従来の一面的な評価では捉えられなかった側面にも光を当てています。

どれほど幅広い知識領域をカバーしているかを視覚的に確認できます
さらに、HLEは以下の点で革新的です:
厳格な問題作成プロセス:専門家が直接問題を作成し、70,000回以上のLLMテストを経て、約13,000問が審査段階に進められました。その後、さらに多段階の人間レビューを通じて問題の品質と難易度が保証されています。
自動採点システム:設問には明確な正解が存在し、回答は自動採点システムによって正確に評価されるため、客観的な評価が可能です。
技術的詳細と評価結果
HLEの評価実験では、最新のLLMが非常に低い正答率と高いキャリブレーションエラーを示しており、以下のような重要な知見が得られました。
まず、正答率についてですが、多くの最先端モデルで10%以下にとどまっており、これは従来のベンチマークと比べて大きなギャップを生み出しています。モデルは、問題の難解さに対応できず、推論過程における曖昧さや誤解釈が影響していると考えられます。
また、キャリブレーションエラーの面では、モデルが自信を持って誤った回答を出す傾向が顕著です。つまり、出力される信頼度と実際の正答率の間に大きな乖離があり、これはLLMの内部の意思決定プロセスにおける不確実性を反映しています。

問題の提出から専門家による多段階レビュー、
最終承認までの流れを明瞭に表現しています
さらに、モデルが推論過程で消費するトークン数(計算リソース)も詳細に分析されました。推論を伴うモデルは、より多くのトークンを生成しており、計算コストが大幅に増加することが確認されています。これは、単に正答率だけでなく、効率性という観点からも今後の改良の余地があることを示唆しています。
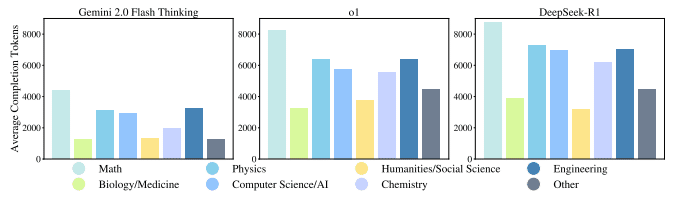
計算資源の消費に関する重要な情報を提供しています
今後の展望と影響
HLEは、LLMの評価方法に革新をもたらすとともに、以下のような幅広い影響を与えると期待されています。
研究へのインパクト:
HLEのような高難度のベンチマークは、LLM研究の新たな目標を設定し、モデルの弱点を明らかにするための重要な指標となります。研究者は、これをもとにモデルの改良や新たなアーキテクチャの開発を進めるでしょう。政策・安全性の観点:
AIの能力と限界を正確に把握することは、倫理的・安全性の観点からも極めて重要です。HLEは、政策立案者がAIのリスク評価を行う際の客観的なデータとしても活用される可能性があります。実務応用への示唆:
高難度なベンチマークは、実際の応用においてLLMがどこまで信頼できるかを評価するための基準となります。例えば、医療や法務といった専門領域では、誤った推論が重大な影響を及ぼすため、HLEの評価結果が実用上の指針となるでしょう。
まとめ
HUMANITY’S LAST EXAMは、従来のベンチマークが抱える「飽和状態」の問題に挑戦し、LLMの実力を真に測るための新たな評価基準として注目されています。専門家による厳格な問題作成と多段階のレビューシステムにより、HLEはLLMが未だ到達していない領域を浮き彫りにしています。
今後、HLEを通じて得られる知見は、AI研究の方向性を定めるだけでなく、実社会におけるAIの安全性や信頼性の確保にも大きな影響を与えるでしょう。