
【論文瞬読】実践者向け!LLM量子化の完全ガイド:精度99%維持のトレードオフ戦略

こんにちは!株式会社AI Nestです。今回は、大規模言語モデル(LLM)の実用化において避けて通れない「量子化」について、最新の研究成果を基に詳しく解説していきます。特に、精度とパフォーマンスのトレードオフに焦点を当て、実践的な導入戦略までご紹介します。
タイトル:"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
URL:https://arxiv.org/abs/2411.02355
所属:Neural Magic, Institute of Science and Technology Austria
著者:Eldar Kurtic, Alexandre Marques, Shubhra Pandit, Mark Kurtz, Dan Alistarh
なぜ今、量子化が重要なのか?
最近、ChatGPTやLlama、Claude等のLLMが話題を集めていますが、これらのモデルを実運用する際には大きな課題があります。デプロイメントコストの高さや、大規模なGPUクラスタの必要性など、多くの組織が導入に二の足を踏んでいる状況です。
そんな中、量子化技術は、モデルの性能を維持しながらこれらの課題を解決する可能性を秘めています。しかし、「どの量子化手法を選ぶべきか」「精度への影響はどの程度か」という疑問に、明確な答えを示した研究は限られていました。
量子化の基礎知識:初心者向け解説
量子化(Quantization)とは、モデルの重みやアクティベーションのビット幅を削減する技術です。通常、LLMは32ビット浮動小数点数(FP32)で計算を行いますが、これを例えば8ビットや4ビットに削減することで、メモリ使用量と計算量を大幅に削減できます。
主な量子化形式として、W8A8(重みとアクティベーションともに8ビット)やW4A16(重みを4ビット、アクティベーションを16ビット)があります。さらに、これらは浮動小数点(FP)と整数(INT)の2つの精度タイプに分かれます。
最新研究で判明!驚きの結果
これまでの「常識」が覆される結果が得られました。特に注目すべきは、INT8量子化の精度に関する発見です。

FP8量子化(W8A8-FP)の驚くべき性能
最も印象的なのは、FP8量子化の結果です。すべてのモデルサイズで99%以上の精度を維持し、特に大規模モデル(405B)では99.9%という驚異的な精度維持を達成しました。これは、適切な実装さえ行えば、ほぼ完全に元のモデルの性能を保持できることを意味します。
INT8量子化の再評価
これまで「大幅な精度低下を引き起こす」と考えられていたINT8量子化ですが、適切な調整を行うことで、精度低下をわずか1-3%に抑えられることが判明しました。この発見は、特にコスト効率を重視する実務者にとって朗報と言えるでしょう。
テキスト生成品質への影響

実際のテキスト生成においても、量子化モデルは元のモデルと遜色ない性能を示しました。特に大規模モデルでは、ROUGE-1スコアで0.74、BERTScoreで0.94という高いスコアを記録。これは、生成されるテキストの質が実用レベルで維持されていることを示しています。
実践的ガイドライン:状況別おすすめ設定
デプロイメントシナリオに応じた選択
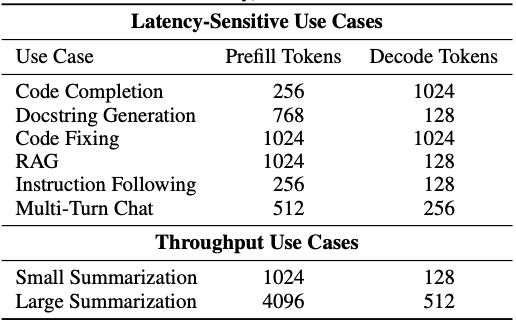
同期デプロイメント(1リクエスト/1処理)の場合は、W4A16が最適です。コード補完やチャットボット、リアルタイム翻訳などのユースケースで、最も低いレイテンシを実現できます。

一方、非同期デプロイメントでは、モデルサイズとハードウェアに応じて選択を分ける必要があります。大規模モデルではW8A8が、中小規模モデルではW4A16が効果的です。

コスト削減効果
最も印象的なのは、コスト面での効果です。8B/70Bモデルで1.5-3倍、405Bモデルでは5-8倍ものコスト削減を達成できます。特に大規模モデルでは、必要なGPU数を75%削減できるケースもあり、初期投資の大幅な抑制が可能です。
実装のベストプラクティス
実装時は、以下の3点に特に注意を払う必要があります:
ハイパーパラメータの適切な調整
ハードウェアに応じた最適化
継続的なモニタリング体制の構築
特にキャリブレーションデータの選択は重要で、高品質なデータセットを用いることで、量子化後の精度を大きく向上させることができます。
今後の展望
量子化技術は、まだ発展途上です。2-3ビットへのさらなる低ビット化や、タスクに応じた動的な量子化手法の開発が進められています。また、マルチモーダルモデルへの応用も期待されている分野です。
しかし、長期的な影響や標準化といった課題も残されています。特にモデル更新時の影響や、評価指標の統一は、今後の研究で解決が期待される重要なテーマです。
まとめ
量子化技術は、LLMの実用化において極めて重要な役割を果たしています。適切な手法を選択し、丁寧な実装を行うことで、大幅なコスト削減と実用的な性能の両立が可能です。
ぜひ、みなさんも自身のプロジェクトで量子化技術の導入を検討してみてください!