
【論文瞬読】LightRAG:グラフ構造が切り拓く次世代の情報検索と生成の世界

こんにちは!株式会社AI Nestです。今回は、最新の自然言語処理技術「LightRAG」について、詳しくご紹介します。この革新的な手法が、私たちの情報アクセスをどのように変革するのか、一緒に見ていきましょう!
タイトル:LightRAG: Simple and Fast Retrieval-Augmented Generation
URL:https://arxiv.org/abs/2410.05779
所属:Beijing University of Posts and Telecommunications、University of Hong Kong
著者:Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang
1. RAGって何?LightRAGって何がすごいの?
まずは基本から。RAG(Retrieval-Augmented Generation)という言葉を聞いたことがありますか?これは、大規模言語モデル(LLM)が外部の知識源から関連情報を取り出し、より正確で文脈に即した回答を生成する技術のことです。
でも、従来の RAG には課題がありました。複雑な関係性を持つ情報をうまく扱えなかったり、新しい情報にすぐに対応できなかったり...。そこで登場したのが「LightRAG」なんです!
LightRAGの特徴を簡単に言うと:
グラフ構造を使って情報をスマートに整理
具体的な情報と抽象的な概念を上手に組み合わせて検索
新しい情報をサクッと取り込める
つまり、より賢く、より速く、より柔軟に情報を扱えるようになるんです。すごくないですか?

2. LightRAGの中身:グラフと二段階検索の魔法
さて、LightRAGがどうやってこの魔法を実現しているのか、もう少し詳しく見ていきましょう。上の図1は、LightRAGの全体的なアーキテクチャを示しています。左から右へ、どのように情報が処理されていくのか、順を追って説明していきます。
2.1 グラフベースのテキストインデックス作成
LightRAGは、文書から実体(人、場所、概念など)と、それらの関係を抽出します。これらを使って、知識グラフを構築するんです。
例えば、「山田太郎は東京大学で人工知能を研究している」という文から、以下のような情報を抽出します:
実体:山田太郎(人物)、東京大学(組織)、人工知能(概念)
関係:山田太郎 - 研究している - 人工知能、山田太郎 - 所属 - 東京大学
こうして作られた知識グラフは、複雑な情報の関係性を効率的に表現できるんです。図1の左側部分がこのプロセスに相当します。
2.2 二段階検索パラダイム
LightRAGの検索は、低レベルと高レベルの二段階で行われます。これは図1の中央部分に示されています。
低レベル検索:具体的な実体や関係を探します。
例:「山田太郎」や「東京大学」といった特定の名前や概念。高レベル検索:より抽象的なトピックや主題を探します。
例:「日本の AI 研究の最前線」といった大きなテーマ。
この二段階アプローチにより、具体的な事実と大局的な文脈の両方を捉えた、バランスの取れた情報検索が可能になるんです。
3. LightRAGのパフォーマンス:数字で見る圧倒的な強さ
論文では、LightRAGを既存の RAG システムと比較しています。結果は...圧倒的!特に大規模で複雑なデータセットで、その真価を発揮しました。
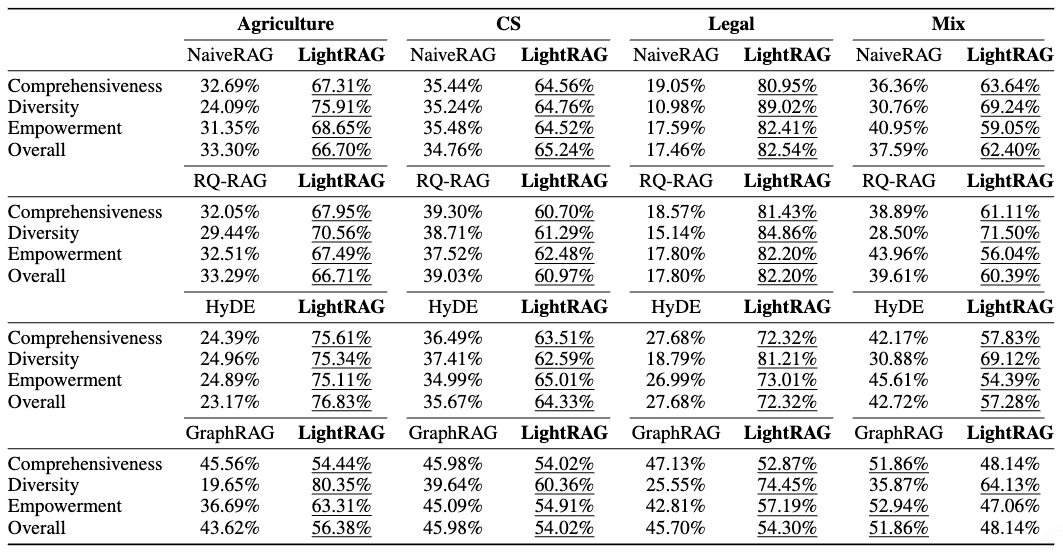
上の表1は、LightRAGと他のベースラインモデルとの詳細な性能比較を示しています。特に注目すべきは、法律関連の大規模データセット(Legal)での結果です:
包括性:NaiveRAGの19.05%に対し、LightRAGは80.95%
多様性:NaiveRAGの10.98%に対し、LightRAGは89.02%
エンパワーメント:NaiveRAGの17.59%に対し、LightRAGは82.41%
つまり、LightRAGは従来の手法を圧倒的に上回る性能を示したんです。特に情報の多様性において、その差は歴然としていますね。
4. LightRAGの実用性:速さと適応力がすごい!
LightRAGのすごいところは、性能だけじゃありません。実用面でも大きなアドバンテージがあるんです。
4.1 驚異的な検索速度
従来の手法(GraphRAG)と比較すると、LightRAGの検索プロセスは圧倒的に効率的です。

上の図2は、LightRAGとGraphRAGの効率性を比較しています。驚くべき差が見られます:
GraphRAG:610,000 トークンを処理し、数百回の API 呼び出しが必要
LightRAG:100 トークン未満で処索し、API 呼び出しはたった 1 回!
この差、想像つきますか? LightRAGなら、ほぼリアルタイムで回答が得られるんです!
4.2 新しい情報にもサクッと対応
LightRAGのもう一つの強みは、新しい情報への適応力です。図2の右側部分がこれを示しています。
従来の手法では、新しい情報を追加するたびに、全体の構造を作り直す必要がありました。これは膨大な計算コストがかかる作業です。
一方、LightRAGは新しい情報を既存の知識グラフに効率的に統合できます。つまり、常に最新の情報を反映した回答が得られるんです。しかも、その更新プロセスが驚くほど軽量なんです!
5. LightRAGの未来:これからの展望と課題
LightRAGは確かに革新的ですが、まだ発展の余地があります。今後の研究で取り組むべき課題としては:
さらなる大規模データでの検証
多言語対応の強化
プライバシーとセキュリティの考慮
説明可能性の向上
これらの課題を克服することで、LightRAGはより幅広い分野で活用される可能性を秘めています。
6. まとめ:LightRAGが拓く情報アクセスの新時代
LightRAGは、単なる技術の進歩を超えて、私たちの情報との関わり方を根本から変える可能性を秘めています。
より正確で包括的な情報検索
複雑な質問への的確な回答
常に最新の知識を反映した応答
これらが実現すれば、教育、研究、ビジネスなど、あらゆる分野で革命が起きるかもしれません。

上の図3は、実際の検索と生成のプロセスを具体的な例で示しています。この例からも、LightRAGがいかに効率的かつ効果的に情報を処理できるかがわかりますね。
LightRAGは、まさに次世代の情報検索と生成の世界を切り拓く、画期的な技術と言えるでしょう。今後の発展が本当に楽しみですね!