
【論文瞬読】ChatPhishDetector: 大規模言語モデルでフィッシングサイトを撃退!

こんにちは!株式会社AI Nestです。今回は、フィッシング詐欺対策に革新をもたらす最新の研究について紹介します。フィッシングサイトの検出に、あのChatGPTで話題の大規模言語モデル(LLMs)を活用するという斬新なアイデアなんです。詳しく見ていきましょう!
タイトル:Detecting Phishing Sites Using ChatGPT
URL:https://arxiv.org/abs/2306.05816
所属:NTT Security Japan (KK) Tokyo, Japan
著者:Takashi Koide, Naoki Fukushi, Hiroki Nakano, Daiki Chiba
フィッシングサイトの脅威
インターネットを利用する上で、私たちはフィッシング詐欺の脅威に常にさらされています。巧妙に偽装されたウェブサイトに個人情報を入力してしまったり、マルウェアに感染したりする危険性があるんですよね。
実際、フィッシングサイトは、FacebookやMicrosoft、Amazonなど、私たちになじみ深いブランドを狙っています。論文で示された上位30ブランドを見てみましょう。

皆さんもよく使うサービスがランクインしているのではないでしょうか。でも、そのフィッシングサイトを見抜くのは、実は結構大変なんです。
既存の検出手法の限界
従来のフィッシングサイト検出手法では、ブランドロゴの画像比較や、正規サイトとの類似性判定などが行われてきました。でも、これらの手法では、独自のロゴを使ったり、正規サイトとは異なるデザインのフィッシングサイトを見逃してしまう可能性があるんです。
hatPhishDetector の登場
そこで登場するのが、「ChatPhishDetector」!大規模言語モデル(LLMs)の驚異的な文脈理解能力を活かして、フィッシングサイトを見抜こうというアイデアです。URLやHTMLのテキスト情報だけでなく、ウェブサイトのスクリーンショット画像からも情報を抽出してLLMsに入力するんですよ。
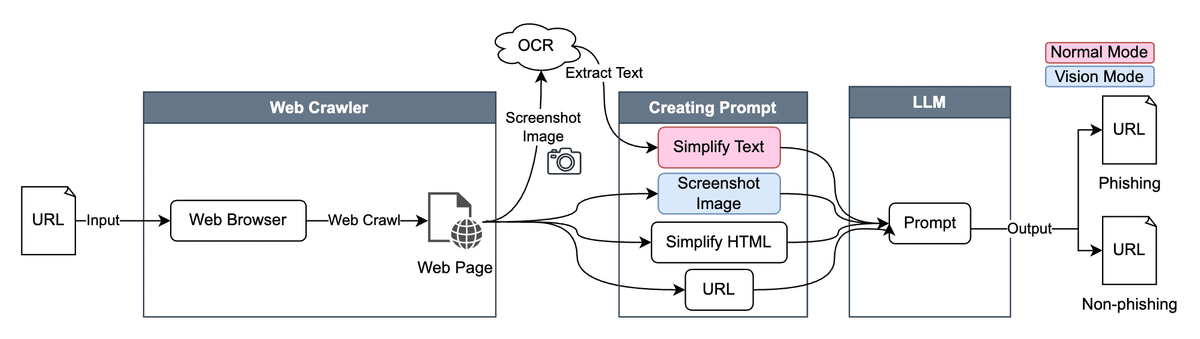
ChatPhishDetectorは、ウェブクローリングによって収集したサイトの情報をもとに、LLMsへの入力用のプロンプトを生成します。そのプロンプトをLLMsに与えることで、そのサイトがフィッシングサイトかどうかを判定するんです。画期的ですよね!
実験結果が示す高い性能
ChatPhishDetectorの性能を評価するために、さまざまなLLMsや既存手法との比較実験が行われました。

この表は、各手法の性能指標を比較したものです。GPT-4Vを用いたChatPhishDetectorが、98.7%の適合率と99.6%の再現率を達成しているのがわかりますね。これは、フィッシングサイトを見逃さず、正規サイトを誤検出しないという、理想的な性能に限りなく近いということなんです。

各手法のフィッシング判定性能をROC曲線で比較したのがこのグラフです。グラフの左上に近いほど、優れた性能を示していますが、GPT-4Vを用いたChatPhishDetectorが他の手法を大きく上回っているのが一目瞭然ですね。
LLMsがフィッシングサイトを見抜く理由
じゃあ、なぜLLMsはフィッシングサイトを高い精度で検出できるのでしょうか?実験結果の詳細な分析から、以下の3つの能力が重要だということがわかりました。
ドメイン名の正当性を評価する能力
ソーシャルエンジニアリング技術を識別する能力
複数の要因を総合的に判断する能力
LLMsは、これらの能力を駆使して、巧妙に偽装されたフィッシングサイトを見抜くことができるんです。
課題と今後の展望
もちろん、ChatPhishDetectorにも課題はあります。LLMsの出力が確率的であることや、プロンプトインジェクション攻撃への脆弱性、トレーニングデータの時期による制約などです。でも、これらの課題を克服しながら、実際のフィッシング対策に活用していくことが期待されています。
おわりに
今回紹介した「ChatPhishDetector」は、サイバーセキュリティ分野に新しい風を吹き込む研究だと言えるでしょう。LLMsの持つ高い文脈理解能力を活用することで、これまで見逃されがちだったフィッシングサイトを高い精度で検出できるようになるかもしれません。
ただし、LLMsを悪用したフィッシング攻撃の可能性にも注意が必要です。技術の進歩は諸刃の剣ですからね。私たちユーザーも、フィッシング詐欺に対する意識を高く持ちつつ、新しい技術の恩恵を受けていきたいものです。