
【論文瞬読】データサイエンスの新時代到来?最新ベンチマーク「DSBench」が示す衝撃の結果

こんにちは!株式会社AI Nestです。今回は、データサイエンス界隈で話題沸騰中の最新ベンチマーク「DSBench」について、深掘りしていきます。AIモデルはどこまで進化した?現実世界のデータサイエンスタスクに太刀打ちできるのか?ワクワクしながら、一緒に見ていきましょう!
タイトル:DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?
URL:https://arxiv.org/abs/2409.07703
所属:University of Texas at Dallas、Tencent AI Lab, Seattle、University of Southern California
著者:Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, Dong Yu
1. DSBenchって何?革新的ベンチマークの全貌
まずは、DSBenchの基本情報をおさらいしましょう。
正式名称:Data Science Benchmark(DSBench)
開発者:Vanderbilt University(ビルダービルト大学)
目的:現実世界のデータサイエンスタスクをより正確に反映するベンチマークの提供
DSBenchの特徴は、なんといってもその「リアルさ」です。従来のベンチマークが「おとなしい」データセットを使っていたのに対し、DSBenchは現実世界の荒波に揉まれたデータを使用しています。具体的には以下の2種類のタスクで構成されています:
データ分析タスク:466問
データモデリングタスク:74問
これらのタスクは、ModelOffとKaggleという有名なデータサイエンス競技プラットフォームから集められました。つまり、プロのデータサイエンティストたちが実際に挑戦したタスクなんです。かなりハードコアですね!

上の図は、DSBenchの全体的なワークフローを示しています。テキスト、画像、Excelファイルなどの多様な入力データから、どのようにしてAIエージェントが結果を導き出すのか、その過程が一目で分かりますね。
2. なぜDSBenchが必要なの?既存ベンチマークの限界
「え?今までのベンチマークじゃダメだったの?」そう思った方もいるかもしれません。実は、既存のベンチマークにはいくつかの問題がありました。

この表は、DSBenchと他のベンチマークを比較したものです。DSBenchの特徴がよく分かりますね。具体的には以下のような問題がありました:
単純化しすぎ:実際のデータサイエンス業務と比べて、あまりにも理想的な環境でのテストになっていた
短い指示:現実では長文の説明や背景情報が与えられることが多いのに、テストでは短い指示のみ
単一モダリティ:テキストデータだけでなく、画像やテーブルデータなど、多様なデータ形式を扱う必要がある
コード補完に偏重:システム全体のエンドツーエンドの評価ができていなかった
特定環境への依存:特定のPythonパッケージなど、限られた環境でのみテストが行われていた
DSBenchは、これらの問題を解決するために生まれたのです。現実世界の複雑さを反映した、まさに「本気の」ベンチマークと言えるでしょう。
3. DSBenchの衝撃的な結果:AIモデルの現在地
さて、ここからが本題です。最新のAIモデルたちは、DSBenchのタスクをどれだけ解決できたのでしょうか?結果は...衝撃的でした。
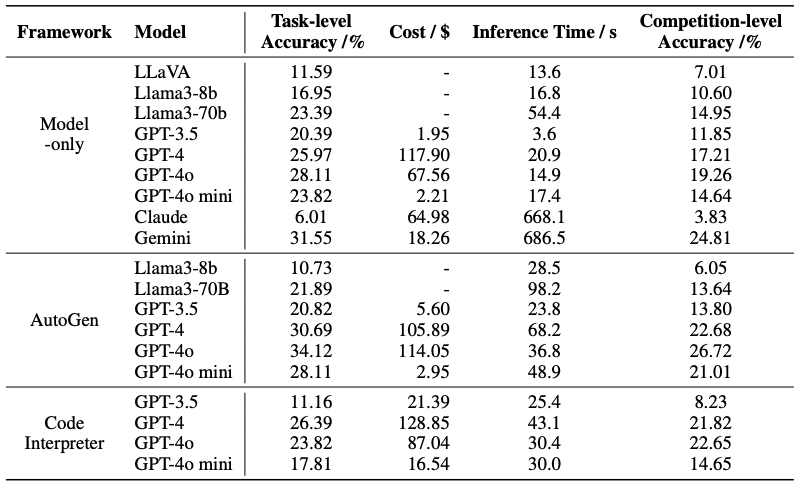
この表は、様々なAIモデルのDSBenchでの性能を比較したものです。驚くべきことに:
最高性能のエージェント(AutoGen with GPT-4o):データ分析タスクの**34.12%**しか解決できず
相対的性能ギャップ(RPG):34.74%(データモデリングタスクにおいて)
つまり、最新のAIモデルでも、現実世界のデータサイエンスタスクの3分の1程度しか解決できていないんです。「えっ、そんなに低いの?」と思われた方も多いのではないでしょうか。
これは、現在のAI技術と実際のデータサイエンス業務の要求との間に、まだまだ大きなギャップがあることを示しています。GPT-4やClaude 3などの大規模言語モデル(LLM)が話題を集める中、この結果は私たちに冷静な視点を与えてくれます。
4. DSBenchが明らかにした課題:AIエージェントの進化に向けて
DSBenchの結果は、単にAIモデルの限界を示しただけではありません。今後のAIエージェント開発に向けた、具体的な課題も浮き彫りにしています。
長文理解力の向上:現実の業務では長い背景説明や複雑な指示が与えられることが多い
マルチモーダル処理の強化:テキスト、画像、テーブルデータなど、多様なデータ形式を統合的に扱う能力が必要
エンドツーエンドの問題解決力:部分的なタスクだけでなく、全体のワークフローを理解し実行する能力
柔軟な環境適応力:特定のツールや環境に依存せず、様々な状況で機能する汎用性
実世界の不確実性への対応:ノイズや欠損値、予期せぬデータ形式の変更などに対するロバスト性

この図は、入力の長さがAIモデルの性能にどのように影響するかを示しています。入力が長くなるほど性能が低下する傾向が見られ、長文理解力の向上が大きな課題であることが分かります。
これらの課題に取り組むことで、より実用的で知的な自律型データサイエンスエージェントの開発が進むことが期待されます。
5. DSBenchの限界と今後の展望
DSBenchは画期的なベンチマークですが、もちろん完璧ではありません。いくつかの限界も指摘されています:
データモデリングタスクの数(74問)が、データ分析タスク(466問)と比べて少ない
データモデリングタスクの源がKaggleの競技のみ
特定の地域や産業に偏りがある可能性
これらの点を改善することで、さらに精度の高いベンチマークになる可能性があります。また、AIモデルの進化に合わせて、定期的にタスクをアップデートしていく必要もあるでしょう。
6. まとめ:DSBenchが切り開く、データサイエンスAIの未来
DSBenchは、私たちにデータサイエンスAIの現在地を明確に示してくれました。最新のAIモデルでさえ、現実世界のタスクの3分の1程度しか解決できていない...この事実は、衝撃的でありながらも、大きな可能性を感じさせます。

この図は、異なるAIモデルがDSBenchの各チャレンジでどのようなパフォーマンスを示したかを視覚的に表現しています。モデル間で性能にばらつきがあり、改善の余地が大きいことが分かります。
なぜなら、これは「伸びしろ」があるということです。DSBenchが明らかにした課題に取り組むことで、AIエージェントはさらに進化し、より実用的なレベルに到達する可能性があります。
今後のAI研究の方向性を示し、より実践的なデータサイエンスAIの開発を促進する...そんなDSBenchの登場は、データサイエンス界にとって大きな一歩と言えるでしょう。
みなさんは、どう思いますか?AIがデータサイエンティストの仕事を奪う日は来るのでしょうか?それとも、人間とAIの協業がさらに進化するのでしょうか?