
【論文瞬読】言語モデルがミスから学ぶ:LEAPが切り開く少量学習の新時代

こんにちは、みなさん!株式会社AI Nestです。
今日は、言語モデルの少量学習に関する興味深い研究を紹介したいと思います。その研究とは、「Learning Principles (LEAP): In-Context Principle Learning from Mistakes」という論文で提案されている新しいアプローチです。
タイトル:In-Context Principle Learning from Mistakes
URL:https://arxiv.org/abs/2402.05403
著者:Tianjun Zhang, Aman Madaan, Luyu Gao, Steven Zheng, Swaroop Mishra, Yiming Yang, Niket Tandon, Uri Alon
LEAPってなに?
LEAPは、言語モデル(LLM)が少量の例から、より多くのことを学習できるようにするための手法です。具体的には、以下のようなステップを踏みます:
与えられた少量の例に対して意図的にミスを生成
そのミスから低レベルの原理を生成
低レベルの原理から高レベルの原理を生成
生成された原理を用いて未知の例に対して推論を行う
つまり、LEAPは言語モデルに自分のミスを内省させることで、将来同様のミスを避けるための原理を学習させるのです。これは、人間の学習プロセスに似ていますよね。

上記の図はLEAPの全体的なプロセスを視覚的に説明しています。上部にChain-of-Thoughtの手法が示されており、下部にLEAPの手法が示されています。これにより、LEAPがどのようにミスから原理を学習するのかを理解しやすくなっています。
従来の少量学習では、言語モデルは正しい入出力ペアからのみ学習していました。しかし、LEAPでは、与えられた少量の例からより多くのことを学習することを目指しています。これにより、言語モデルは限られたデータからより豊富な知識を獲得することができるのです。
どんな原理を学習するの?
LEAPでは、低レベルの原理と高レベルの原理の2種類の原理を学習します。
低レベルの原理は、個々のミスに対して生成される原理です。例えば、「問題文をよく読んで、必要な情報を見落とさないようにする」といった原理が生成されます。これらの原理は、特定のタスクやドメインに依存する傾向があります。
一方、高レベルの原理は、低レベルの原理をまとめて、より一般的な原理を生成したものです。例えば、「問題文を注意深く読み、文脈を理解することが重要である」といった原理が生成されます。これらの原理は、様々なタスクやドメインに適用可能な、より汎用的な知識を表しています。

上記の図は、LEAPによって学習された原理の具体例を示しています。各原理のキーアイデアがハイライトされており、LEAPがどのような原理を学習するのかを理解するのに役立ちます。
LEAPでは、これらの原理を学習することで、言語モデルが未知の問題に対してもより適切な推論を行えるようになるのです。
実験結果は?
研究チームは、DROP、HotpotQA、GSM8K、MATH、Big-Bench Hardなど、様々な推論タスクでLEAPの有効性を検証しました。その結果、GPT-3.5-turbo、GPT-4、GPT-4-turbo、Gemini Proなど、複数の強力な言語モデルに対して、LEAPが少量学習よりも優れた性能を示すことが明らかになりました。
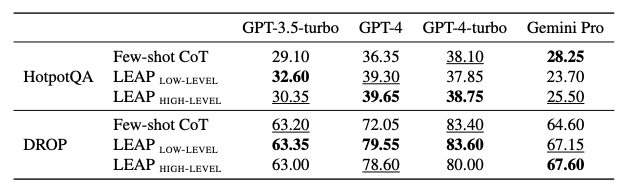
上の表は、GPT-3.5-turbo、GPT-4、GPT-4-turbo、Gemini Proの4つのモデルにおける、HotpotQAとDROPというテキスト推論ベンチマークの精度を示しています。Few-shot CoT、LEAP LOW-LEVEL、LEAP HIGH-LEVELの3つのアプローチが比較されており、LEAPの有効性が示されています。
例えば、DROPというデータセットでは、GPT-4を使用した場合、LEAPは少量学習と比べて7.5%の性能向上を達成しました。また、HotpotQAというデータセットでは、GPT-4を使用した場合、LEAPは少量学習と比べて3.3%の性能向上を達成しました。
特筆すべきは、LEAPが少量学習と全く同じ数のラベル付き例しか必要としないという点です。追加のデータを必要とせずに、既存の言語モデルの性能を向上させることができるのは大きなメリットだと言えるでしょう。
議論点は?
LEAPは非常に有望なアプローチですが、いくつかの議論点もあります。
一つは、オープンソースのモデルに対する適用可能性です。研究チームによると、Llama-2-chat-70Bのようなオープンソースのモデルに対してLEAPを適用しても、性能の改善は見られなかったそうです。これは、オープンソースのモデルがプロプライエタリなモデルほど強力な指示に従う能力や内省能力を持っていないためだと考えられています。
もう一つは、LEAPの低レベルと高レベルのどちらを使うべきかという点です。研究チームによると、これはタスクの推論の複雑さ、ベンチマーク内の質問の多様性、LLMが生成できた原理の質に依存するそうです。つまり、タスクやデータセットに応じて、適切な方を選ぶ必要があるということですね。
まとめ
LEAPは、言語モデルがミスから学ぶことで、少量学習の性能を向上させる画期的なアプローチです。実験結果からもその有効性が示されており、今後のさらなる発展に期待が持てます。
ただし、オープンソースのモデルへの適用可能性や、LEAPの低レベルと高レベルの使い分けなど、いくつかの課題もあります。これらの問題が解決されれば、LEAPはより広く適用可能な手法になるでしょう。
言語モデルの研究に興味があるみなさんには、ぜひこの論文をチェックしてみてください!LEAPのアイデアを取り入れることで、言語モデルの性能をさらに向上させることができるかもしれません。