
【論文瞬読】LongRAG: 超長文脈時代のRetrieval Augmented Generationの新たな可能性

こんにちは、株式会社AI Nestです。今回は、自然言語処理の分野で注目を集めているRetrieval Augmented Generation(RAG)に関する新しい論文を紹介します。題して「LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs」。RAGの課題を見事に解決した画期的なフレームワークが提案されています。
タイトル:LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
URL:https://arxiv.org/abs/2406.15319v1
所属:University of Waterloo
著者:Ziyan Jiang, Xueguang Ma, Wenhu Chen
RAGとは?
RAGをご存知ない方もいるかもしれません。簡単に言うと、RAGは言語モデルの生成性能を向上させるために、外部のコーパスから関連情報を検索して利用する手法のことです。例えば、質問応答システムに応用すると、質問に関連する情報を大規模なコーパスから検索し、その情報を基に回答を生成することができます。これにより、言語モデル自体が持っている知識だけでなく、外部の知識も活用できるようになるのです。
従来のRAGの問題点
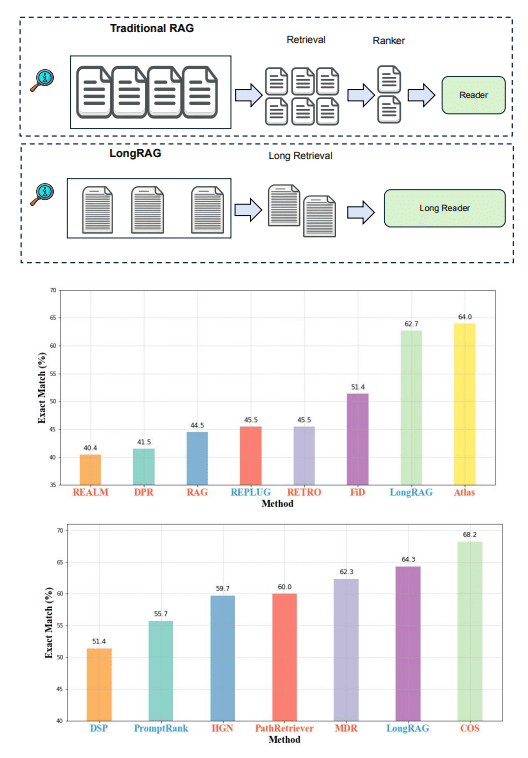
しかし、従来のRAGには大きな問題がありました。それは、retriever(検索役)とreader(読解役)の負担のバランスが悪いこと。Retrieverは巨大なコーパスから該当の短い文を探すという重労働なのに、readerは検索結果から答えを抽出するだけの簡単なタスク。Retrieverは膨大な数の候補から目的の情報を見つけ出さないといけないので、retrieverの性能がシステム全体のボトルネックになっていたのです。
LongRAGの革新的アプローチ
そこで登場したのがLongRAGです!LongRAGの肝は、retrieval unitを従来の30倍にまで長くしたこと。具体的には、1つのretrieval unitが平均4,000単語にもなります。これにより、コーパスのサイズが22分の1まで圧縮されるので、retrieverの負担が大幅に減ります。また、長文脈に特化したretrieverを使うことで、少ない検索回数で高いrecallを実現。つまり、少ない労力で必要な情報を見つけ出せるようになったのです。

そして、readerには超長文脈(30,000単語!)を処理できる大規模言語モデル(Large Language Model: LLM)を使用します。これだけの長さの文脈を処理できるLLMは、つい最近まで存在しませんでした。しかし、GPTシリーズに代表されるLLMの登場により、超長文脈の処理が可能になったのです。LongRAGは、この最新テクノロジーを巧みに活用することで、retrieverとreaderのバランスを取ることに成功しました。
驚くべき評価結果
この革新的なアイデアの結果は、驚くべきものでした。自然言語処理のベンチマークデータセットであるNatural QuestionsとHotpotQAで評価したところ、retrieverのrecallは大幅に向上。Natural Questionsでは、わずか4つのretrieval unitを使うだけで86%のrecallを達成しました。HotpotQAでも同様に、8つのretrieval unitで84%のrecallを記録しています。


さらに驚くべきは、readerの性能です。LongRAGのreaderは、教師あり学習の最新手法に匹敵する性能を示しました。Natural Questionsでは62.7%、HotpotQAでは64.3%の精度を達成しています。これは、RAGフレームワークにおけるretrieverとreaderのバランスの重要性を如実に示す結果だと言えるでしょう。


今後の展望と課題
LongRAGは、RAGの新たな可能性を切り開いた画期的な論文だと言えます。retrieval unitを長くすることで、retrieverの負担を減らし、readerにその分の負担を移すことができるというアイデアは非常にエレガントです。超長文脈を扱えるLLMの登場により、このような発想が可能になったとも言えるでしょう。


とはいえ、課題がないわけではありません。論文中でも議論されているように、長文脈の埋め込みモデルの精度向上、retrieval unitのグループ化手法の汎用化など、まだまだ発展の余地はありそうです。また、readerに用いるLLMについても、長文脈への対応だけでなく、位置バイアスの影響を受けにくいモデルが求められます。
結論
自然言語処理の分野は日進月歩で進化しています。LongRAGはその一例にすぎませんが、retrieverとreaderのバランスという新しい視点は、他の様々なタスクにも応用可能な重要なコンセプトだと感じました。今後のさらなる発展に期待したいと思います!