
【論文瞬読】LLaVA-o1: 視覚言語モデルに「人間らしい」段階的思考をもたらす革新的アプローチ

こんにちは!株式会社AI Nestです。今回は、視覚言語モデル(VLM)の世界に新しい風を吹き込む注目の研究、「LLaVA-o1」についてご紹介します。AIが画像を「見て」「考え」「答える」—その過程をより人間らしく、より論理的にする試みです。
タイトル:LLaVA-o1: Let Vision Language Models Reason Step-by-Step
URL:https://arxiv.org/abs/2411.10440
所属:School of Electronic and Computer Engineering, Peking University、Institute for Interdisciplinary Information Sciences, Tsinghua University、Peng Cheng Laboratory、AI for Science (AI4S)-Preferred Program, Peking University Shenzhen Graduate School、Alibaba DAMO Academy、Computer Science and Engineering, Lehigh University
著者:Guowei Xu, Peng Jin, Li Hao, Yibing Song, Lichao Sun, Li Yuan
🌟 なぜ今このモデルが注目されているのか
様々なVLMモデルが登場する中、LLaVA-o1は特筆すべき成果を上げています。以下の図1は、様々なモデルとの性能比較を示しています。

私たちが普段何かを考えるとき、いきなり答えを出すわけではありませんよね。問題を整理し、情報を集め、じっくり考えて、最後に結論を導き出す—。これまでのAIモデルは、この「考える過程」があまりにも機械的でした。
LLaVA-o1は、この課題に真正面から取り組んだモデルです。特筆すべきは、わずか10万件のデータセットで、より大規模なモデルを凌ぐ性能を実現したこと。コスト効率の面でも画期的なブレークスルーと言えるでしょう。
💡 技術的なブレークスルー:4段階思考プロセス
LLaVA-o1の革新的な点は、その思考プロセスにあります。以下の図3は、モデルの処理フローを示しています。
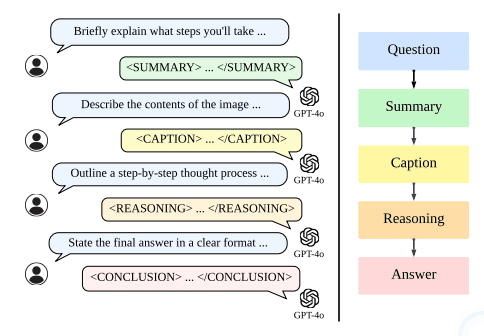
1. Summary Stage(要約段階)
まず問題を整理します。「何が求められているのか」「どうアプローチするか」を明確にします。人間で言えば、「よし、この問題はこうやって解こう」という作戦を立てる段階です。
2. Caption Stage(キャプション段階)
画像が含まれる場合、その視覚情報を言語化します。単なる物体認識ではなく、問題に関連する要素を的確に抽出します。例えば、数学の問題なら図形の特徴や寸法などを言語化します。
3. Reasoning Stage(推論段階)
ここが最も重要なパート。論理的な推論を段階的に行います。数式を使う場合は計算過程を、論理的な問題は思考の流れを、明確に示していきます。
4. Conclusion Stage(結論段階)
最終的な答えを導き出します。ここでのポイントは、前段階までの推論に基づいた妥当な結論を導くこと。
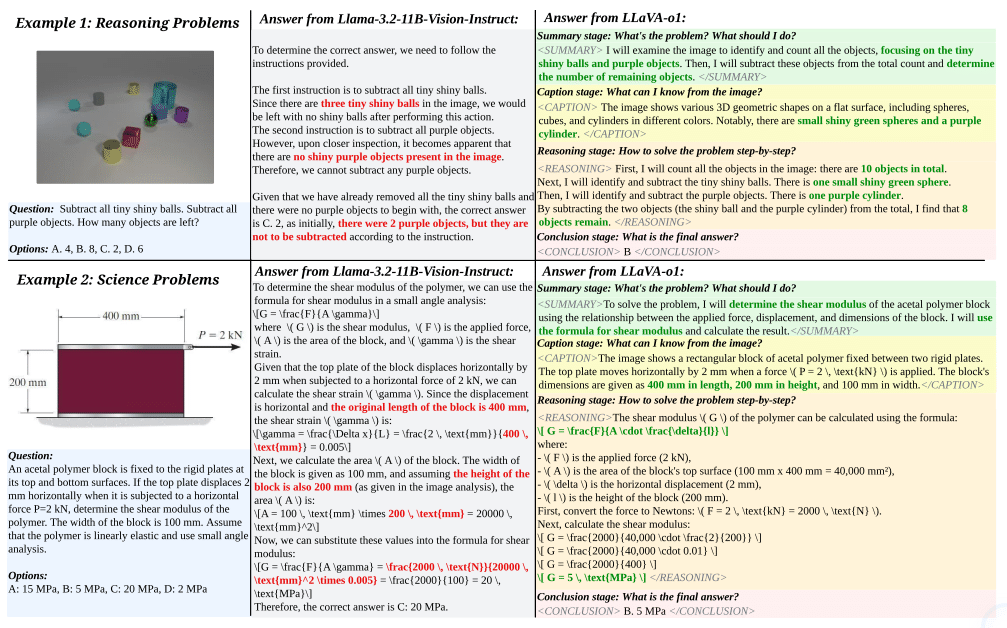
実際の推論例を見てみましょう。以下の図2は、ベースモデルとLLaVA-o1の推論過程の比較です。
🔧 技術的な工夫:Stage-levelビームサーチ
LLaVA-o1は、独自のStage-levelビームサーチを採用しています。図4は、従来手法との違いを示しています。
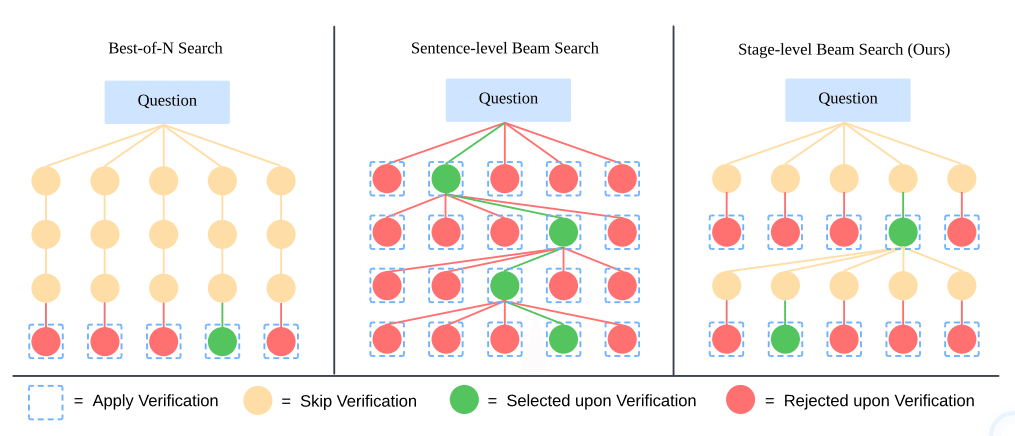
従来のビームサーチと異なり、各思考段階でベストな選択肢を探索します。これにより:
推論の早い段階でのエラー検出が可能に
より確実な推論パスの選択
計算リソースの効率的な活用
が実現されています。
📊 驚きの実験結果
以下の表7は、最新のVLMsとの詳細な性能比較を示しています。

実験結果で特に注目したいのは:
ベースモデルから8.9%の性能向上
Gemini-1.5-proやGPT-4o-miniといった非公開モデルをも上回る性能
より大規模なオープンソースモデルとの比較でも優位性を示す結果
💭 今後の展望と課題
このアプローチは、AIの「思考過程」をより人間が理解しやすい形で実現した点で、大きな一歩と言えます。今後の発展が期待される部分として:
期待される発展
外部検証機構との連携による精度向上
強化学習の導入による推論プロセスの最適化
より複雑なマルチモーダルタスクへの応用
残された課題
計算リソースとの最適なバランス
より柔軟な思考構造の実現
特殊なケースへの対応能力の向上
🎯 実務での活用に向けて
このモデルの登場は、様々な実用シーンでの活用が期待できます:
教育支援:問題解決過程の詳細な説明
医療診断支援:診断根拠の段階的な提示
技術文書作成:論理的な文書構造の自動生成
まとめ
LLaVA-o1は、AIの「思考プロセス」をより人間に近づけた画期的なモデルです。単に正解を出すだけでなく、「どう考えたか」を明確に示せる点が、今後のAI開発の重要な指針となるでしょう。
技術の進歩は日々めざましいものがありますが、このモデルの示した方向性—より論理的で説明可能なAIの実現—は、間違いなく正しい道筋だと感じています。