
【論文瞬読】大規模言語モデルのプロンプト圧縮に革新をもたらす新手法 LLMLingua-2

こんにちは!株式会社AI Nestです。
近年、GPT-3やGPT-4に代表される大規模言語モデル(LLM)が自然言語処理の分野で大きな注目を集めています。LLMは膨大な言語データから学習することで、質問応答や要約、翻訳など、様々なタスクで高い性能を発揮します。しかし、その一方で、LLMへの入力として与えるプロンプトが長大になると、推論の高速化や低コスト化が課題となります。
そこで登場するのが、プロンプト圧縮という技術です。プロンプトの長さを短くすることで、LLMの推論を効率化しようというアプローチですね。今回は、プロンプト圧縮の新しい手法として注目を集めている「LLMLingua-2」を紹介します。
タイトル:LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
URL:https://arxiv.org/abs/2403.12968
所属:Tsinghua University, Microsoft Corporation
著者:Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Dongmei Zhang
プロンプト圧縮の従来手法とその問題点
プロンプト圧縮の従来手法としては、情報エントロピーに基づいて単語の重要度を推定し、重要度の低い単語を削除するというアプローチが主流でした。しかし、この方法には以下のような問題点があります。
情報エントロピーはプロンプト圧縮の目的と合致していない
単方向の文脈情報しか考慮できないため、圧縮に必要な重要な情報を見落とす可能性がある
つまり、従来手法では、プロンプト圧縮に最適化されていない指標を用いていたため、圧縮後のプロンプトの質が十分に保証されていなかったのです。
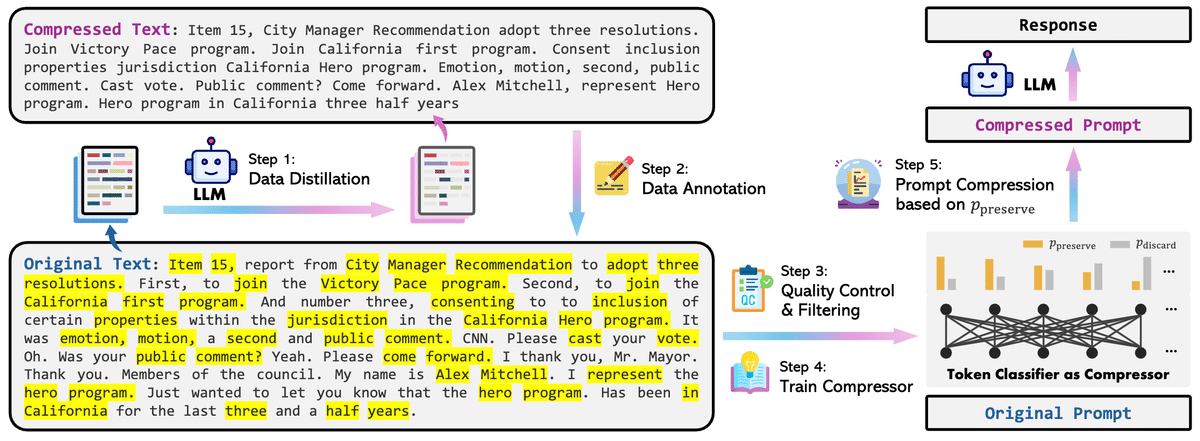
LLMLingua-2:GPT-4のナレッジを活用した革新的なアプローチ
そこで登場するのが、LLMLingua-2という新しいプロンプト圧縮手法です。LLMLingua-2の革新的な点は、GPT-4のような強力なLLMから、重要な情報を損なわずにテキストを圧縮するナレッジを蒸留している点にあります。
具体的には、以下のようなステップで圧縮モデルを構築します。
GPT-4を用いてテキストを圧縮し、圧縮前後のペアからなるデータセットを構築
圧縮テキストから元のテキストを復元するタスクを通じて、各単語にpreserve(残す)またはdiscard(捨てる)のラベルを付与
ラベル付きデータセットを用いて、Transformerエンコーダベースの単語分類器を学習
学習済み分類器を用いて各単語のpreserve確率を推定し、所望の圧縮率を達成するようにトップN個の単語を選択
この一連のプロセスにより、LLMLingua-2は双方向の文脈情報を考慮しながら、プロンプト圧縮に最適化された単語の重要度を学習することができるのです。
実験結果:高い汎化性能と低レイテンシーを実現
LLMLingua-2の有効性を検証するために、著者らは複数のベンチマークデータセットを用いて評価を行いました。
まず、MeetingBankデータセットにおける各手法の性能を比較した結果が以下の表です。

LLMLingua-2は、質問応答(QA)とサマリーの両タスクにおいて、従来手法を大きく上回る性能を達成しています。特に、LLMLingua-2-smallというBERTベースの小さなモデルでさえ、オリジナルのプロンプトに匹敵する性能を示しているのが印象的ですね。

次に、他ドメインのデータセット(LongBench、ZeroSCROLLS)での評価結果を見てみましょう。
ここでも、LLMLingua-2は従来手法を上回る性能を達成しており、モデルに依存しない高い汎化性能を示しています。また、LLMLingua-2はプロンプト圧縮の処理速度も非常に高速で、エンドツーエンドのレイテンシーを1.6倍から2.9倍に短縮できることが報告されています。
これらの結果は、LLMLingua-2がプロンプト圧縮の汎用的な解決策となり得ることを示唆しています。
まとめと今後の展望
LLMLingua-2は、GPT-4のナレッジを活用することで、プロンプト圧縮における新しい可能性を切り開いた革新的な手法だと言えます。双方向の文脈情報を考慮しながら、プロンプト圧縮に最適化された単語の重要度を学習できる点が大きな強みですね。
ただし、現状ではMeetingBankのみで学習しているため、他ドメインでの性能にはまだ改善の余地がありそうです。今後は、より大規模かつ多様なデータセットを活用することで、さらなる性能向上が期待できるでしょう。
また、プロンプト圧縮以外にも、モデルのアーキテクチャやハードウェアの最適化など、LLMの推論を高速化・低コスト化するための様々なアプローチがあります。これらの技術と組み合わせることで、LLMの実用性がさらに高まっていくことを期待したいですね。
LLMの発展に伴い、プロンプト圧縮のような周辺技術も重要性を増しています。LLMLingua-2のような革新的な手法が登場することで、LLMのさらなる普及と実用化が加速していくことでしょう。今後の展開に目が離せません。