
【論文瞬読】無限の可能性を秘めたTransformerFAM: 脳科学と言語モデルの融合

みなさん、こんにちは!株式会社AI Nestです。
今回は、自然言語処理の分野で大きな注目を集めている論文、「TransformerFAM: Feedback attention is working memory」を紹介します。この論文は、Transformerの長い文脈を処理する能力を向上させる新しいメカニズム、Feedback Attention Memory (FAM)を提案しています。
タイトル:TransformerFAM: Feedback attention is working memory
URL:https://arxiv.org/abs/2404.09173
著者:Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, Pedro Moreno Mengibar
Transformerの課題とFAMの提案
Transformerは、自然言語処理のタスクで大きな成功を収めてきました。しかし、文脈の長さに対して二次の計算量を要するという問題があります。これは、Transformerが長い文脈を扱う際の大きな障壁となっています。具体的には、文脈の長さがLのとき、計算量はO(L^2)になってしまうんです。これでは、長い文書や対話を処理するのが難しくなってしまいます。

そこで登場するのが、FAMです!FAMは、Transformerのレイヤー間にフィードバックループを導入することで、ワーキングメモリの機能を実現します。ワーキングメモリとは、一時的に情報を保持し、処理するための記憶システムのことです。人間の脳でも、ワーキングメモリは重要な役割を果たしています。FAMは、このワーキングメモリの機能をTransformerに組み込むことで、長い文脈を効率的に処理できるようにしているんです。
FAMを導入することで、Transformerが無限に長い文脈を扱えるようになり、計算量もO(L)に抑えられます。つまり、文脈の長さに対して線形の計算量で済むようになるんです。これは、Transformerの応用範囲を大きく広げる可能性を秘めています。
脳科学の知見を取り入れたFAM
FAMの提案では、脳科学の知見も取り入れられています。特に、注意機構とワーキングメモリの関連性に着目しています。脳科学の研究では、注意機構がワーキングメモリの制御に重要な役割を果たしていることが示唆されているんです。

論文の著者たちは、この知見をTransformerに応用することで、FAMを考案しました。Transformerの注意機構を利用して、ワーキングメモリの機能を実現しようというアイデアです。理論的背景から実装、実験的検証まで一貫しており、FAMの有効性が示されています。
特に印象的だったのは、PassKey retrievalタスクにおけるFAMの性能です。このタスクでは、長い文脈の中に埋め込まれたパスキーを見つけ出すことが求められます。FAMは、Block Sliding Window Attention (BSWA)やRecurrent Memory Transformer (RMT)、AutoCompressorsといった他の手法を上回る性能を示しました。長い文脈の中から重要な情報を取り出す能力が、FAMによって大きく向上したことが分かります。
FAMの実装と実験結果
論文では、FAMの実装方法も詳しく説明されています。TransformerのMulti-Head Attentionを拡張し、フィードバックループを組み込むことでFAMを実現しているんです。
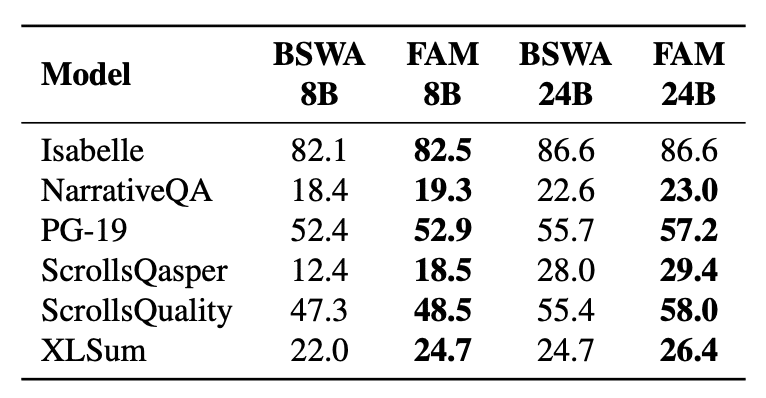
また、FAMの有効性を検証するために、さまざまな実験が行われました。長い文脈を扱うタスクとして、PG-19、Isabelle、NarrativeQA、ScrollsQasper、ScrollsQuality、XLSumなどが使用されました。これらのタスクにおいて、FAMはTransformerのベースラインを上回る性能を示しました。


特に、ScrollsQasperやNarrativeQAといった質問応答タスクでの性能向上が顕著でした。これらのタスクでは、長い文脈から質問に関連する情報を抽出する必要があります。FAMは、長い文脈の中から重要な情報を効率的に取り出すことができるため、これらのタスクで高い性能を発揮したのだと考えられます。
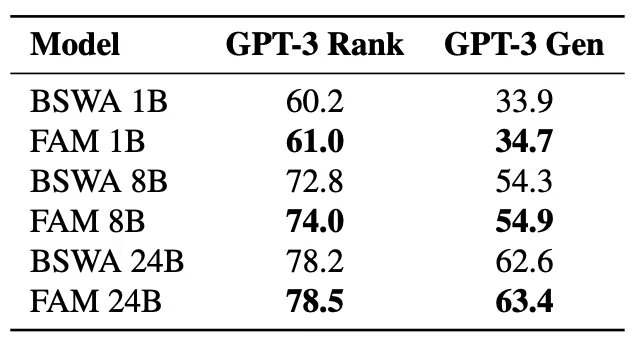
さらに、GPT-3のタスクでもFAMの性能が評価されました。FAMを導入することで、GPT-3タスクにおいてもわずかながら性能の向上が見られたんです。これは、FAMが文脈の表現を効率化し、入力の活性化における重複を減らすことで、潜在空間の利用を最適化しているためだと考えられます。
FAMの今後の展望と課題
FAMは、Transformerの長い文脈処理能力を向上させる画期的なアプローチですが、まだ課題もあります。
まず、FAMの学習に使用するデータの問題があります。現状では、理想的な学習データが入手できていないため、Flanのデータセットで代用しています。しかし、FAMの性能を最大限に引き出すには、より長い連続した文脈を含むデータが必要だと考えられます。今後は、FAMの学習に特化したデータの収集が求められるでしょう。
また、FAMの最適な長さや、より洗練させるための改良の方向性についても、さらなる検討が必要です。FAMの長さが性能に与える影響や、他の手法との組み合わせによる性能向上の可能性など、探求すべき課題は多岐にわたります。
しかし、FAMのポテンシャルは大きいと言えます。今後は、FAMを他の言語モデルに応用することで、さらなる性能向上が期待できます。また、脳科学の知見を言語モデルの研究に取り入れることの重要性も、FAMを通じて再認識させられました。
まとめ
TransformerFAMは、Transformerの長い文脈処理能力を向上させる新しいアプローチを提示した重要な研究です。脳科学の知見を取り入れ、注意機構とワーキングメモリの関連性に着目したFAMは、言語モデルの発展に大きく寄与すると期待されます。
FAMは、長い文脈から重要な情報を効率的に取り出すことができるため、質問応答やテキスト要約など、さまざまなタスクでの応用が期待されます。また、他の言語モデルとの組み合わせによる性能向上の可能性も、非常に興味深いですね。
FAMのようなメカニズムが、今後の言語モデルの発展にどのような影響を与えていくのか、非常に楽しみです。みなさんも、ぜひこの論文を読んでみてください。Transformerの限界とその克服に向けた新しいアイデアについて、理解を深めることができるはずです。私たちも、常にアンテナを張って、最新の研究動向をキャッチしていきたいですね。