
【論文瞬読】AIの推論能力を劇的に向上させる魔法の呪文『CoRe』とは?

みなさん、こんにちは!株式会社AI Nestです。今日は、大規模言語モデル(LLM)の世界に革命を起こしかねない、超興味深い研究を紹介します。その名も「CoRe(コア)」!ChatGPTやGPT-4のような最新のAI技術をさらに進化させる可能性を秘めたこの手法、一緒に詳しく見ていきましょう。
タイトル:Unleashing Multi-Hop Reasoning Potential in Large Language Models through Repetition of Misordered Context
URL:https://arxiv.org/abs/2410.07103
所属:Department of Electrical and Computer Engineering, Seoul National University, Interdisciplinary Program in Artificial Intelligence, Seoul National University
著者:Sangwon Yu, Ik-hwan Kim, Jongyoon Song, Saehyung Lee, Junsung Park, Sungroh Yoon
LLMの秘められた課題、ついに明らかに
皆さんは、ChatGPTなどのAIが複雑な質問に答える時、どんな仕組みで考えているか想像したことありますか?実は、AIも人間と同じように、複数の情報を順番に組み合わせて答えを導き出しているんです。これを「多段階推論」と呼びます。

例えば、「エッフェル塔を設計した人物が生まれた国の首都は?」という質問に答えるとき、AIは以下のような段階を踏んで推論します:
エッフェル塔の設計者を特定(ギュスターヴ・エッフェル)
その人物の出身国を調べる(フランス)
フランスの首都を答える(パリ)
ところが!この多段階推論、実はある大きな問題を抱えていたんです。それが今回の研究で明らかになった「順序が乱れた文脈問題」。簡単に言うと、AIに与える情報の順番によって、答えの正確さが大きく変わってしまうという問題なんです。

具体的には、AIに提供する文書の順序が最適でない場合、正しい答えにたどり着けないことがあるんです。これは特に、複数の文書から情報を組み合わせる必要がある複雑な質問で顕著に現れます。
CoRe、その驚きの正体
そこで登場したのが、今回のヒーロー「CoRe」(Context Repetition)です。
CoReの仕組みは驚くほどシンプル。AIに与える情報を、そのまま繰り返すだけ。でも、この単純な方法が、なんと劇的な効果を発揮するんです!
具体的には:
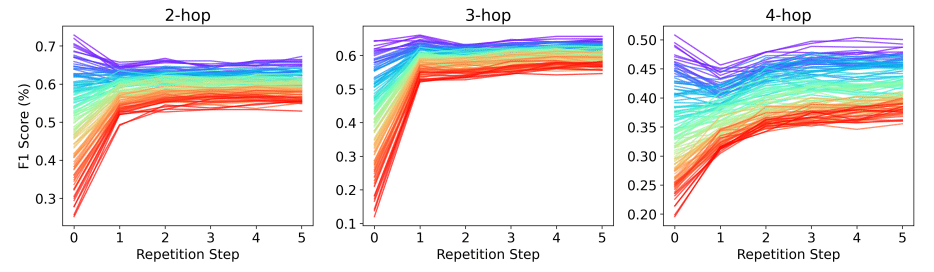
多段階QAタスクでF1スコアが最大30%ポイント向上
合成タスクで正確性が最大70%ポイント改善
まさに、目からウロコが落ちる結果ですよね。
なぜCoReはこんなに効くの?
CoReが効果を発揮する理由は、AIに「考え直す機会」を与えているから。情報を繰り返すことで、AIは異なる視点から問題を見直し、より適切な推論経路を見つけ出せるんです。
これを人間に例えると、難しい問題を解く時に、問題文を何度も読み直すようなものです。最初は気づかなかった重要な情報や、情報同士のつながりが見えてくることってありますよね。CoReは、AIにもそんな「あ、そうか!」moment を提供しているんです。


さらに、CoReは「lost-in-the-middle」問題(長い文章の真ん中にある重要情報を見逃してしまう問題)の解決にも一役買っています。これって、まさに一石二鳥ですよね!
CoReの具体的な適用例
CoReの威力をより具体的に理解するために、実際の適用例を見てみましょう。
例えば、次のような複雑な質問を考えてみてください:
「ハリー・ポッターシリーズの作者が生まれた年に起こった重要な科学的発見は?」
この質問に答えるために、AIは以下のような情報を必要とします:
ハリー・ポッターシリーズの作者(J.K.ローリング)
J.K.ローリングの生年(1965年)
1965年に起こった重要な科学的発見
従来のLLMでは、これらの情報が最適な順序で提供されないと、正しい答えにたどり着くのが難しかったのです。しかし、CoReを適用することで、AIはこれらの情報を何度も「読み返す」機会を得て、より確実に正解にたどり着けるようになりました。
CoReの可能性は無限大!?
研究チームは、CoReを検索拡張生成タスクに応用する実験も行いました。結果は?もちろん、大成功!Chain-of-Thought(CoT)推論と組み合わせることで、さらなる性能向上を実現しています。
CoTは、AIに「考える過程」を言語化させる手法です。これとCoReを組み合わせることで、AIはより人間らしい、段階的で論理的な思考プロセスを展開できるようになりました。

例えば、先ほどのハリー・ポッターの質問に対して、AIは次のように答えるかもしれません:
まず、ハリー・ポッターシリーズの作者はJ.K.ローリングです。
J.K.ローリングは1965年生まれです。
1965年の重要な科学的発見を調べると...(ここで情報を検索)
1965年には、宇宙背景放射の発見が確認されました。これは、ビッグバン理論を支持する重要な証拠となりました。
このように、CoReとCoTの組み合わせは、AIの推論能力を飛躍的に向上させる可能性を秘めているのです。
CoReの課題と今後の展望
もちろん、CoReにも課題はあります。最も大きな問題は、文脈を繰り返すことによる計算コストの増大です。情報量が増えれば増えるほど、処理に時間がかかってしまいます。
また、ノイズの多い情報環境でのCoReの効果についても、さらなる研究が必要です。不要な情報が多い中で、本当に重要な情報をどのように見分けるか。これは人間にとっても難しい課題ですよね。


それでも、CoReが示した可能性は計り知れません。今後は、以下のような方向性で研究が進むことが期待されます:
効率的な反復方法の開発:必要な情報だけを効果的に繰り返す技術
ノイズ除去技術との組み合わせ:重要情報を的確に抽出し、それを繰り返す手法
マルチモーダルAIへの適用:テキストだけでなく、画像や音声情報にもCoReを応用する試み
まとめ:CoReが開く、AIの新時代
CoReの登場は、LLMの多段階推論に新たな地平を切り開く可能性を秘めています。シンプルながら強力なこの手法は、今後のAI開発に大きな影響を与えるかもしれません。
私たちの日常生活でも、CoReの恩恵を受ける日が来るかもしれません。例えば:
より正確で詳細な検索結果
複雑な質問にも的確に答えるAIアシスタント
多様な情報を統合して新しい知見を生み出す研究支援システム
AIの「考える力」を大きく前進させる、この革新的な手法。今後の発展が本当に楽しみですね!