
【論文瞬読】大規模言語モデルの能力の起源に迫る:暗記と汎化のバランスがカギ

こんにちは、株式会社AI Nestです。今回は、先日読んだ興味深い論文について紹介したいと思います。
タイトル:Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
URL:https://arxiv.org/abs/2407.14985
著者:Antonis Antoniades, Xinyi Wang, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, William Yang Wang
この論文は、大規模言語モデル(LLMs)の能力がどのようにしてプリトレーニングデータから生まれるのかを解明しようとする研究です。LLMsは、GPT-3やBERTなどに代表される、大量のテキストデータで事前学習されたTransformerベースの自然言語処理モデルです。これらのモデルは、様々なタスクで驚くべきパフォーマンスを示していますが、その能力の起源についてはまだ十分に理解されていません。
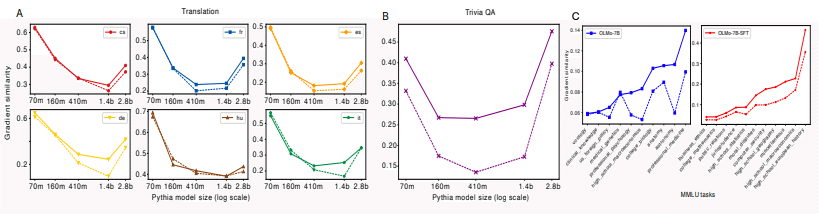
著者らは、LLMsの「暗記」と「汎化」のバランスに着目し、タスク関連のn-gramペアの出現頻度とパフォーマンスの関係を定量的に分析しています。ここで、「暗記」とは、LMが学習データを丸暗記することを指し、「汎化」とは、学習データにない新しいケースに対応できる能力を指します。また、n-gramとは、長さnの連続した単語列のことで、言語モデルや情報検索でよく使われる概念です。
研究の概要
著者らは、Translation、Factual QA、Reasoningの3種類のタスクにおいて、PythiaとOLMoという2つのオープンソースLMファミリーを使用して実験を行いました。

Translation: WMT-09データセットを使用。ヨーロッパ言語から英語への翻訳タスク。
Factual QA: TriviaQAデータセットを使用。トリビア式の質問応答タスク。
Reasoning: MMLUベンチマークを使用。57種類の推論タスク。
彼らは、タスクデータからタスク関連のn-gramペアをマイニングし、プリトレーニングコーパスでそれらの出現回数を検索することで、プリトレーニングデータとLMの推論結果の関係を詳細に分析しました。具体的には、タスクの入力と出力からそれぞれn-gramを抽出し、埋め込みモデルを使って意味的に似ているn-gramのペアを選択します。そして、それらのペアがプリトレーニングコーパス内でどの程度出現するかを調べ、タスクパフォーマンスとの関係を分析するのです。
主要な知見
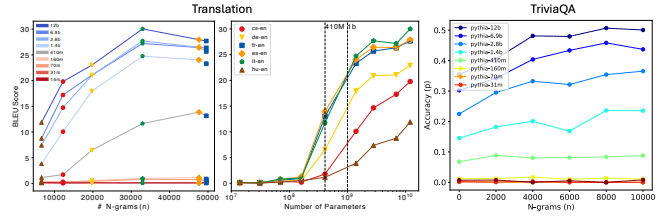
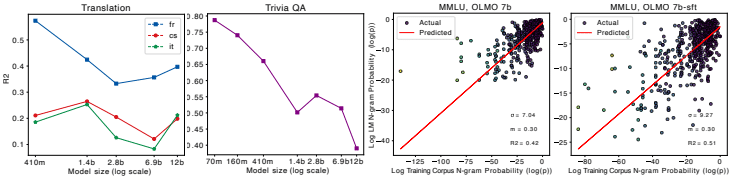
モデルサイズが大きくなるほど、タスク関連のデータがより重要になり、パフォーマンスが向上する一方で、暗記が減少し、汎化が強まる。
これは、小さなモデルはデータを丸暗記する傾向があるのに対し、大きなモデルは学習データを元に新しい内容を生成できるようになることを示唆しています。
Emergent abilities (新たに出現する能力) は、タスク関連のプリトレーニングデータとモデルサイズのミスマッチから生じる可能性がある。
つまり、十分なタスク関連データがあっても、モデルサイズが小さすぎると能力が発現しないということです。
小さなLMsは暗記する傾向があり、大きなLMsは汎化する傾向がある。
これは、1つ目の知見とも関連していますが、モデルサイズによって暗記と汎化のバランスが変化することを示しています。
Instruction tuning (命令調整) はLMがプリトレーニングデータをよりよく活用するのに役立つ。
Instruction tuningを行ったモデルは、プリトレーニングデータへの依存度が高くなり、難しいタスクでもより良いパフォーマンスを発揮できるようになります。

今後の課題と展望
本研究は、LLMsの能力の起源を理解するために重要な一歩を踏み出していますが、まだ課題も残されています。
最新のオープンソースLLMsやプリトレーニングコーパスを用いた大規模な分析が必要。
本研究で使用されたPythiaやPileは若干古くなっており、最新のモデルやデータを使った分析が求められます。
タスク関連のn-gramペアのフィルタリング方法の改善。
より洗練された方法を用いることで、分析の質を向上できる可能性があります。
LLMsの解釈性、公平性、プライバシーなどの問題への応用。
この研究の知見を活かすことで、より倫理的で信頼できるAIシステムの開発に貢献できるかもしれません。
著者らが提案した方法論は、今後のLLM研究に広く応用できる可能性を秘めています。さらなる研究の発展により、LLMsの能力の起源についてより深い理解が得られることが期待されます。
感想
私自身、LLMsの「暗記」と「汎化」のバランスに関する知見は非常に興味深いと感じました。モデルサイズとプリトレーニングデータの関係を定量的に分析した点は、新しいアプローチだと思います。特に、emergent abilitiesがデータとモデルサイズのミスマッチから生じるという指摘は、示唆に富んでいます。
また、この研究はLLMsの解釈性や公平性、プライバシーなどの問題にも光を当てており、AIの倫理的な利用を考える上でも重要だと感じました。LLMsが学習データをどの程度暗記しているかを理解することは、プライバシー保護の観点からも欠かせません。
今後、この研究を発展させることで、LLMsの能力の起源についてさらに深い理解が得られるのではないでしょうか。同時に、得られた知見を活かして、より信頼できるAIシステムの開発につなげていくことが重要だと思いました。