
【論文瞬読】LLMの信頼性を高める:誤作出(Hallucination)対策の実践ガイド

皆さん、こんにちは!株式会社AI Nestです。今回は、LLMの大きな課題である誤作出(Hallucination)対策について、最新の研究成果をベースに実践的なアプローチをご紹介していきます。ChatGPTやBardなどのLLMが日常的に使用される現在、その出力の信頼性向上は私たちエンジニアにとって避けて通れない課題となっています。
タイトル:Investigating the Role of Prompting and External Tools in Hallucination Rates of Large Language Models
URL:https://arxiv.org/pdf/2410.19385
所属:Stellenbosch University, Stellenbosch, Western Cape, South Africa
著者:Liam Barkley, Brink van der Merwe
📊 LLMを取り巻く現状と課題
LLMの普及は驚異的なスピードで進んでいます。ChatGPTは約1億8,550万人のユーザーを抱え、WhatsAppも2024年4月からLLMベースのチャットボットを導入するなど、私たちの日常生活に着実に浸透しつつあります。

しかし、この急速な普及に伴い、誤作出(Hallucination)の問題が顕在化してきています。誤作出は大きく「事実性の誤り」と「忠実性の誤り」に分類されます。事実性の誤りには、事実との矛盾や根拠のない事実の創作が含まれます。一方、忠実性の誤りには、指示との不一致やコンテキストとの矛盾、論理的整合性の欠如などが該当します。
🔍 研究から見えてきた重要な発見
プロンプト戦略の効果検証
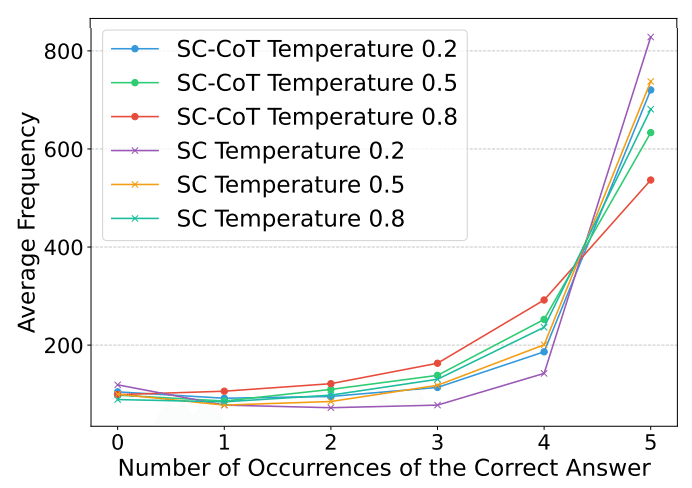
数学的推論タスク(GSM8K)での検証では、興味深い結果が得られました。最も高い正解率を示したのは、Self-Consistency(SC)手法で、温度パラメータ0.8の設定時に84.89%を記録しました。これは、より複雑なTree-of-Thoughts(75.91%)やChain-of-Thought(71.08%)を上回る結果でした。
特に注目すべきは温度パラメータの影響です。低温(0.2)設定では出力は安定するものの創造性が制限され、高温(0.8)設定では多様な解答が得られる一方で不安定さが増すという特徴が明らかになりました。
知識ベース問題への対応
TriviaQAを用いた検証では、Chat Protect(CP)手法が興味深い結果を示しました。温度0.8の設定で82.49%という高い正解率を達成しました。ただし、これは回答率が57.1%に留まる代償を伴うものでした。一方、DuckDuckGo Augmentation(DDGA)は67.47%の正解率を維持しながら、100%の回答率を実現しています。

💡 実装戦略とベストプラクティス
実践的な実装に向けて、タスクの性質に応じた適切な戦略選択が重要です。数学や論理的推論が必要なタスクにはSC手法が効果的で、特に温度0.8での運用が推奨されます。知識検索を要するタスクではCP手法とDDGAの組み合わせが有効で、温度は0.5程度が適切とされています。


リスクレベルに応じた実装も重要な検討ポイントです。高リスクな用途では、複数の検証メカニズムを組み合わせた総合的なアプローチが必要です。一方、リスクが比較的低い用途では、基本的なプロンプトエンジニアリングで十分な場合も多いでしょう。
🔬 実験から得られた具体的な示唆
本研究では8Bパラメータのモデルを用いた検証が行われ、外部ツール統合に関する重要な知見が得られました。特に注目すべきは、ツール統合時の複雑性増加が新たな誤作出を引き起こす可能性があるという点です。

コスト効率の観点からは、各手法のAPIコール数を考慮する必要があります。SC手法とCP手法は基本プロンプトの5倍、MAD手法は3.5倍のコールを必要とします。実装時にはこれらのコストとパフォーマンスのバランスを慎重に検討する必要があります。
🚀 実装に向けたアプローチ
実装のプロセスは、評価、戦略選択、実装、最適化の4段階で進めることを推奨します。まず現状の誤作出率を測定し、リスクレベルと要件を明確化します。次に、タスク特性とコスト制約を考慮しながら適切な手法を選定します。実装フェースではプロトタイプ開発とA/Bテストを行い、最後に継続的なモニタリングとパラメータ調整を行います。
🔮 今後の展望
今後の研究の方向性として、より大規模なモデルでの検証や新しい注意機構の開発、マルチモーダル対応などが期待されます。また、誤作出の定量的測定手法や業界標準の確立も重要な課題となるでしょう。
ハイブリッド手法の開発や自己修正メカニズムの実装、外部知識との効率的な統合など、新しいアプローチの可能性も広がっています。これからも目が離せませんね!