
【論文瞬読】LLMsの推論性能と入力テキストの長さの関係:新たな評価手法FLenQAが明らかにする課題と展望

こんにちは!株式会社AI Nestです。
今日は、自然言語処理の分野で注目を集めている大規模言語モデル(Large Language Models: LLMs)に関する興味深い研究を紹介したいと思います。この記事では、LLMsの推論性能と入力テキストの長さの関係について探っていきます。
タイトル:Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
URL:https://arxiv.org/abs/2402.14848
所属:University of Arizona, Technical University of Cluj-Napoca
著者:Bar-Ilan University, Allen Institute for AI
大規模言語モデル(LLMs)とは?
まず、LLMsについて簡単に説明しましょう。LLMsは、大量のテキストデータを用いて訓練された言語モデルで、GPT-4やGPT-3.5などが有名です。これらのモデルは、長い文章を理解して、質問に答えたり、文章を生成したりできます。LLMsは、自然言語処理の分野で大きな進歩をもたらしていますが、まだ多くの課題があります。
入力テキストの長さとLLMsの推論性能の関係
LLMsの推論性能と入力テキストの長さの関係を調べた研究が、「Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models」です。この論文では、研究者たちが入力テキストの長さが推論性能に与える影響を深く掘り下げています。
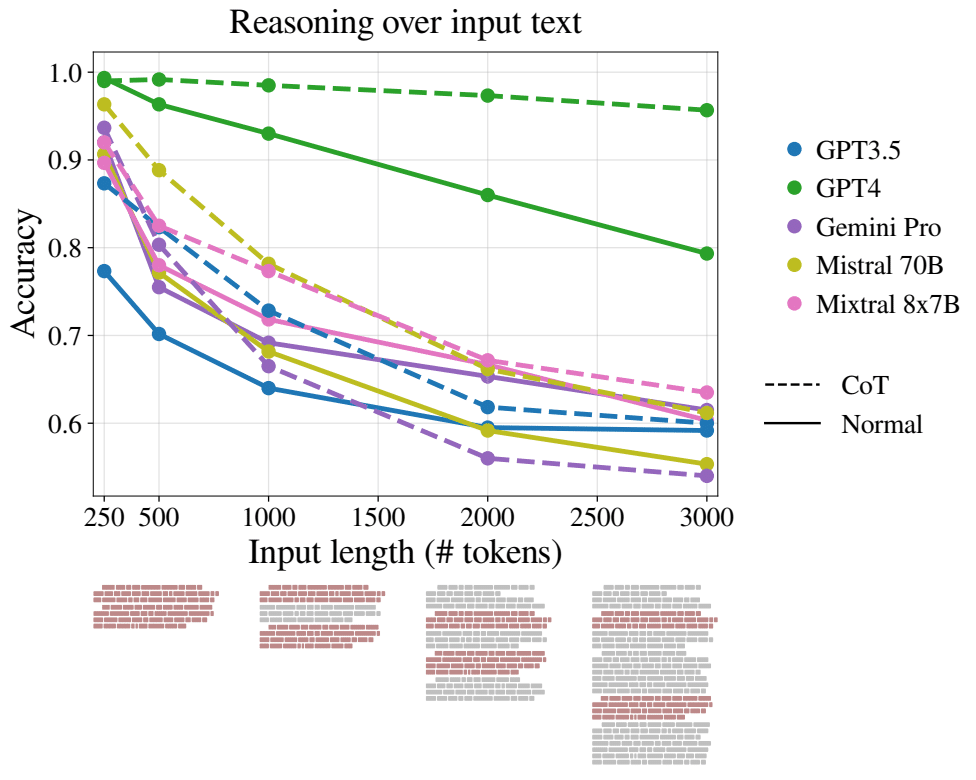

彼らは、この問題を調べるために、FLenQA(Flexible LENgth Question Answering dataset)という新しいデータセットを作成しました。このデータセットは、入力テキストの長さを変化させながら、LLMsの推論性能を評価するために設計されています。
実験結果と考察
研究者たちは、FLenQAデータセットを使って、GPT-4、GPT-3.5、Gemini-Pro、Mistral 70B、Mixtral 8x7Bの5つのLLMsを評価しました。その結果、いくつかの重要な発見がありました。
1.LLMsの推論性能は、モデルの最大入力長よりもはるかに短い入力長で大幅に低下する。
2.関連情報の位置や無関係なテキストの種類に関係なく、入力長が長くなるほど性能が低下する傾向がある。


3.長い入力に対する次の単語予測の性能と推論タスクの性能に相関はない。

4.Chain-of-Thought(CoT)プロンプティングを使っても、入力長に起因する性能低下を軽減できない。


5. 入力長が長くなると、LLMsには特定の失敗モードが見られる。
これらの結果は、LLMsの性能評価において重要な問題を提起しています。モデルの最大入力長が長くなっても、実際の推論タスクでは入力長が性能に大きく影響することが明らかになりました。また、次の単語予測の性能と推論性能が必ずしも相関しないことも興味深い発見です。
今後の研究の方向性
ただし、この研究にはいくつかの限界もあります。評価に使用したタスクの種類が限定的であるため、より複雑な推論タスクでの性能については未検証です。また、性能低下の原因についても十分に説明できていません。
今後は、これらの点を含めたさらなる研究が必要だと思います。入力長の影響を考慮した評価方法の確立と、性能低下の原因究明が進むことで、LLMsの性能をより正確に評価し、改善していくことができるでしょう。
まとめ
この論文は、LLMsの性能評価における新しい視点を提供しており、今後のLLM開発と評価に重要な示唆を与えるものです。入力テキストの長さがLLMsの推論性能に与える影響を明らかにし、現在の評価方法の限界を指摘しました。
これからも、LLMsの研究動向から目が離せません。新しい発見や進歩があれば、またこのブログで紹介していきたいと思います。それでは、次の記事でお会いしましょう!