
【論文瞬読】MMMU-Pro:AIの真の理解力を暴く新世代ベンチマーク - マルチモーダルAIの実力と限界が明らかに

こんにちは、皆さん!株式会社AI Nestです。
今日は、マルチモーダルAI評価の世界に革命を起こしているMMMU-Proについて、深掘りしてお話しします。最新のAI技術がどこまで進化したのか、そして何がまだ課題なのか、一緒に探っていきましょう!
タイトル:MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
URL:https://arxiv.org/abs/2409.02813
所属:MMMU Team
著者:Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, Graham Neubig
参考URL:https://mmmu-benchmark.github.io/#leaderboard
MMMU-Proとは? - AIの"真の理解力"を測る新基準
MMMU-Pro(Massive Multi-discipline Multimodal Understanding - Pro)は、既存のMMMUベンチマークを大幅にアップグレードした次世代の評価ツールです。簡単に言えば、AIが本当に「見て」「理解して」「考える」ことができるのかを、より厳密に、そして現実世界に近い形でチェックできるようになったんです。

でも、なぜこんな新しいベンチマークが必要だったのでしょうか?
従来のベンチマークの限界 - "抜け道"だらけだった?

これまでのベンチマークには、いくつかの問題がありました:
テキストだけで答えられる問題が混在:画像を見なくても解ける問題があったんです。
選択肢が少なすぎ:4択だと、AIが運良く当てることも。
真の統合的理解の評価が不十分:テキストと画像を本当に"理解"しているのか、それとも単なるパターンマッチングなのか、判断が難しかったんです。
MMMU-Proは、これらの問題にまっすぐ挑戦しています。AIの"ズル"や"当て推量"を許さない、厳しくも公平な評価システムなんです。
MMMU-Proの3つの革新的アプローチ
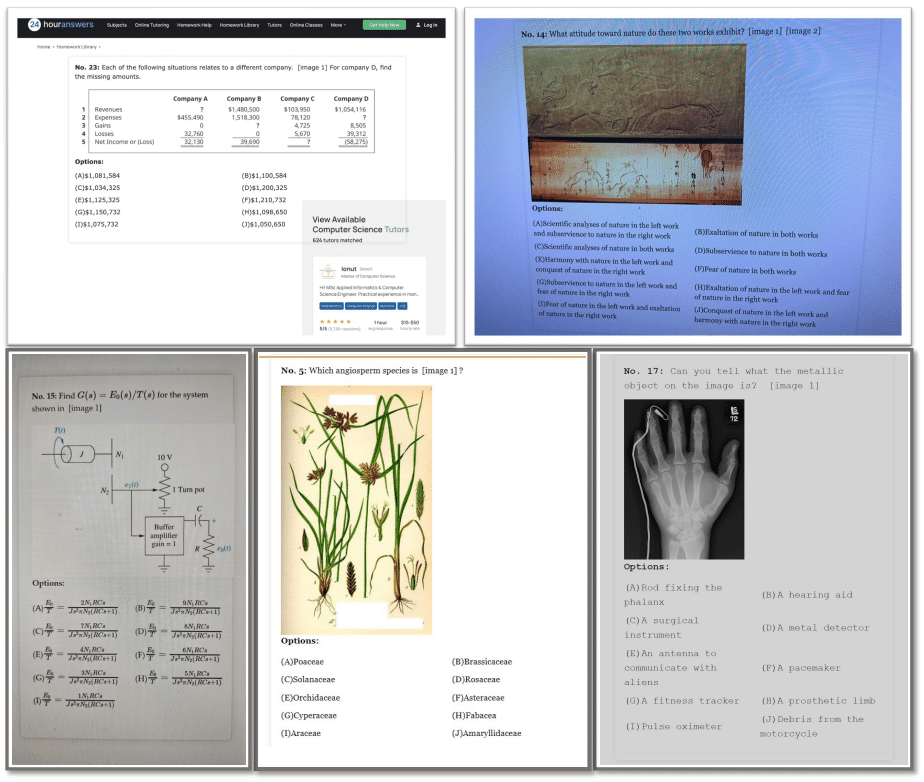
MMMU-Proには、3つの画期的な特徴があります:
厳選された問題セット:
テキストのみのAIでは太刀打ちできない問題だけを慎重に選びました。具体的には、Llama3-70B-Instruct、Qwen2-72B-Instruct、Yi-1.5-34B-Chat、Mixtral-8×22B-Instructなどの強力な言語モデルを使って、テキストだけで解ける問題を徹底的に除外しています。選択肢の大幅増加:
4つだった選択肢を最大10個に増やしました。これにより、AIが単純な確率で正解を当てることがほぼ不可能になりました。同時に、人間の専門家がGPT-4oの助けを借りて選択肢を慎重に作成し、質の高さも担保しています。「ビジョンのみ」モードの導入:
質問をスクリーンショットや写真に埋め込む新しい評価方式を導入しました。これは、人間が日常的に行っているような、画像内のテキストと視覚情報を同時に処理する能力を試すものです。背景、フォントスタイル、フォントサイズを変えて撮影することで、現実世界の多様な状況をシミュレートしています。

衝撃の結果 - 最新鋭AIも苦戦
結果は、多くの研究者の予想を覆すものでした。最新鋭のAIモデルたちも、MMMU-Proの前では苦戦を強いられたのです。
GPT-4o(0513):従来のMMMUで69.1%だった正答率が、MMMU-Proでは51.9%に低下。
Claude 3.5 Sonnet:68.3%から51.5%へ。
Gemini 1.5 Pro(0801):65.8%から46.9%へ。

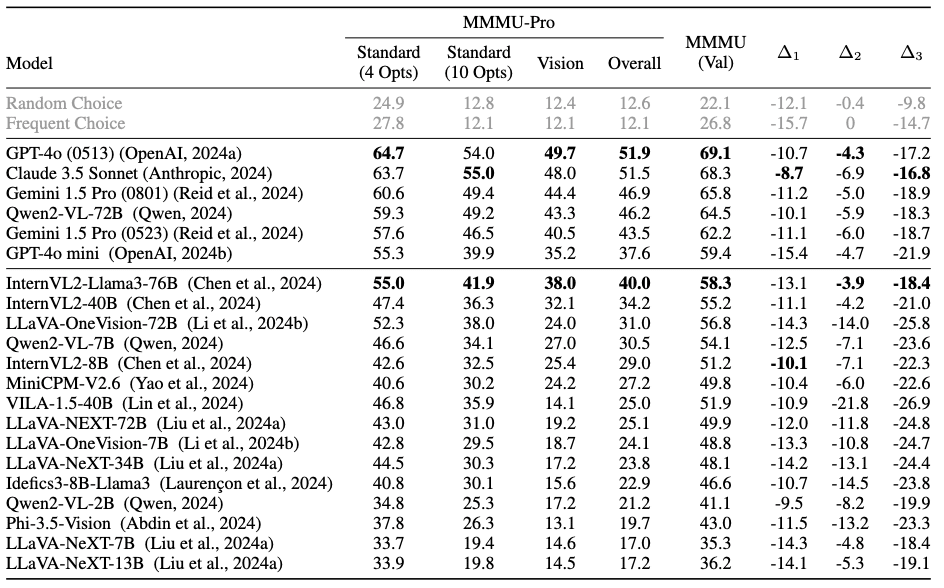
この結果は何を意味するのでしょうか?それは、現在のAIにはまだまだ改善の余地があるということです。特に、テキストと画像を真に「理解」し、それに基づいて「推論」する能力には大きな課題があることが明らかになりました。
興味深い発見 - OCRとCoTの効果
研究チームは、OCR(光学文字認識)プロンプトやCoT(Chain of Thought)推論の効果も詳細に調査しました。
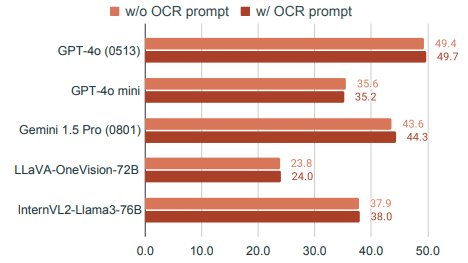

OCRプロンプトの効果:
意外にも、OCRプロンプト(画像内のテキストを書き出すよう指示すること)はほとんど効果がありませんでした。これは、最新のAIモデルがすでに高度な画像テキスト抽出能力を持っていることを示唆しています。CoT推論の影響:
一方、CoT(段階的な思考プロセスを促すプロンプト)は概してパフォーマンスを向上させました。ただし、その効果はモデルによって大きく異なりました。例えば、Claude 3.5 Sonnetは標準設定で42.7%から55.0%に大幅に向上しましたが、LLaVA-OneVision-72Bではほとんど改善が見られませんでした。
これらの結果は、AIの「思考プロセス」を促すことの重要性と、同時にその難しさを浮き彫りにしています。
実世界への示唆 - AIアプリケーション開発への影響
MMMU-Proの結果は、実際のAIアプリケーション開発にも重要な示唆を与えています:


ユーザーインターフェースの設計:
AIが画像内のテキストと視覚情報を同時に処理する能力が試されることで、より自然なユーザーインターフェースの設計が可能になるかもしれません。エラー処理の重要性:
AIの理解力や推論能力の限界が明らかになったことで、エラー処理やフォールバックメカニズムの重要性が再認識されました。説明可能性の向上:
CoT推論の効果が示されたことで、AIの決定プロセスをより透明化する取り組みが加速する可能性があります。
今後の展望 - AIはこれからどう進化する?
MMMU-Proの登場は、マルチモーダルAI研究に新たな挑戦状を突きつけました。今後注目されそうな研究テーマをいくつか挙げてみましょう:
マルチモーダル統合処理の高度化:
テキストと画像を真に統合的に理解し、処理する能力の向上が求められます。複雑な推論能力の強化:
単なる情報抽出だけでなく、抽出した情報を基に複雑な推論を行う能力の開発が必要です。ロバスト性の向上:
様々な形式や品質の入力に対して安定したパフォーマンスを発揮できるモデルの開発が期待されます。効率的な学習手法の探求:
より少ないデータと計算資源で、高度な理解力と推論能力を獲得する手法の研究が進むでしょう。倫理的配慮の組み込み:
高度な理解力と推論能力を持つAIの開発に伴い、倫理的な判断を組み込む研究も重要になってきます。
まとめ - AIの真の能力を知ることの重要性
MMMU-Proは、単なるベンチマークの改良にとどまりません。それは、AIの真の能力を知るための新しい物差しを私たちに提供してくれました。
この新しい評価基準により、私たちはAIとの付き合い方や、AIの実用化の道筋をより明確に見通せるようになります。同時に、AI開発者たちにとっては、より高度で実用的なAIの開発に向けた道標となるでしょう。
AIの「理解力」や「推論能力」は、私たちが思っていた以上に複雑で、まだ発展途上であることが明らかになりました。しかし、それは同時に、この分野にはまだまだ大きな可能性が眠っているということでもあります。
AIの世界は日々進化しています。これからも最新情報をお届けしていきますので、お楽しみに!次回のブログでまたお会いしましょう。