
【論文瞬読】Google DeepMindが切り拓く大規模AIの新時代 - Gemini 1.5シリーズの衝撃

こんにちは!株式会社AI Nestです。Google DeepMindが開発した大規模マルチモーダル言語モデル「Gemini 1.5」シリーズが、AIの可能性を大きく広げています。その驚異的な長文脈理解能力と高度なマルチモーダル性は、これまでの常識を覆す成果と言えるでしょう。今回は、Gemini 1.5シリーズの特徴と意義について詳しく解説していきます。
タイトル:Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
URL:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
著者:Gemini Team, Google
Gemini 1.5シリーズの概要
Gemini 1.5シリーズには、Gemini 1.5 ProとGemini 1.5 Flashの2つのモデルが含まれています。どちらも効率性、マルチモーダル性、長文脈推論、ダウンストリームタスクのパフォーマンスを追求した設計になっています。
特に注目すべきは、Gemini 1.5 Proの超長文脈理解能力です。なんと1000万トークン(約700万単語)もの入力を処理できるのです。これは、現在最長とされるClaude 3の200万トークンを大幅に上回る記録です。つまり、Gemini 1.5 Proは「戦争と平和」のような大作小説をまるごと読み込み、その内容について質問に答えられるということです。まさに、AIによる「本の理解」が現実のものとなったと言えるでしょう。
以下の表は、Gemini 1.5 ProとFlashの長文脈対応力を、先代のGemini 1.0シリーズと比較したものです。新モデルの大幅な性能向上が見て取れます。


長文脈理解能力の評価
では、Gemini 1.5シリーズの長文脈理解能力は実際にどの程度なのでしょうか?DeepMindのチームは、診断的評価と現実的評価の両面からアプローチしています。
診断的評価では、「針山の中の針」タスクを用いて、モデルが長い文脈の中から特定の情報を正確に取り出せるかを測定しました。以下のグラフは、テキストの針山タスクにおけるGemini 1.5 ProとGPT-4の性能を比較したものです。
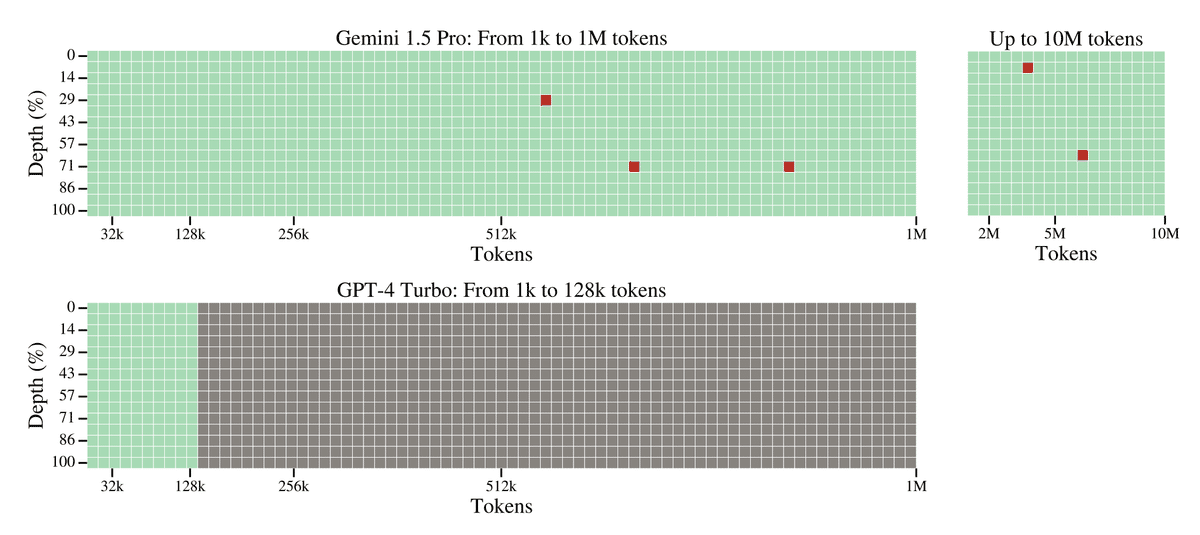
グラフから明らかなように、Gemini 1.5 Proは100万トークンの文脈の中から99.7%の確率で目的の情報を見つけ出すことができました。一方、Gemini 1.5 Flashも200万トークンまでは100%の精度を維持しており、優れた長文脈検索性能を示しています。
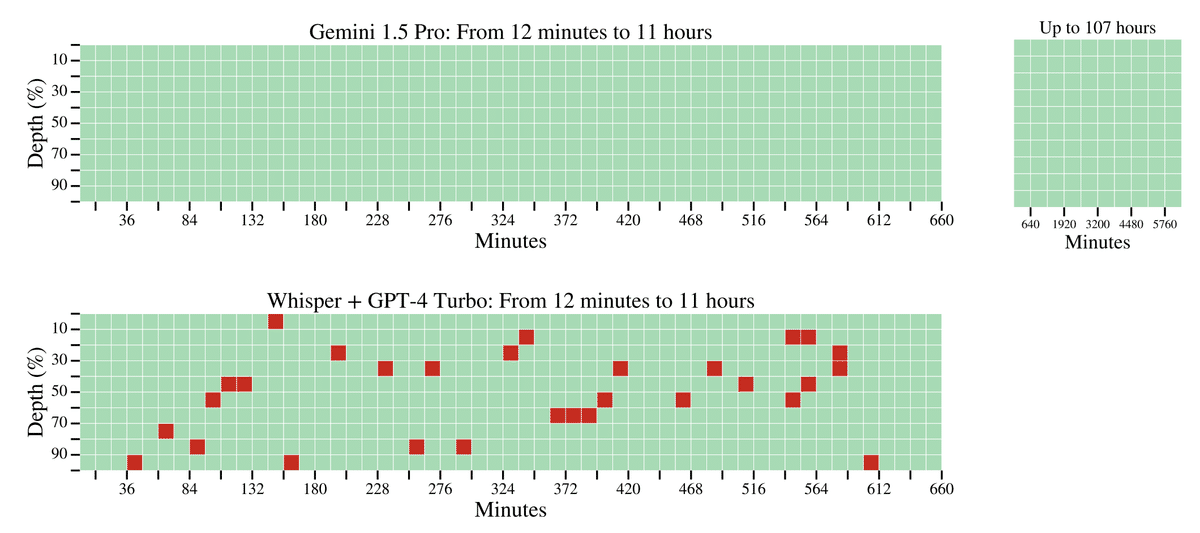
ビデオやオーディオの針山タスクでも、Gemini 1.5 Proは10時間を超える長時間のデータから高い精度で情報を取り出すことに成功しました。以下はその性能をGPT-4VやWhisper+GPT-4と比較したグラフです。

現実的評価でも、Gemini 1.5シリーズの長文脈理解能力の高さが示されました。例えば、Gemini 1.5 Proは70万語の長編小説「レ・ミゼラブル」を読み込んだ上で、その内容に関する質問に人間と遜色ない回答を生成できました。以下のグラフは、文脈長と回答の質の関係を示したものです。

また、たった1冊の文法書と単語帳を読み込むだけで、話者200人未満の少数言語カラマン語を学習し、英語からカラマン語への翻訳を人間と同等のレベルで行えるようになりました。以下は、文脈長の増加に伴う翻訳性能の向上を示したグラフです。

これらの結果は、Gemini 1.5シリーズの汎用性の高さと、少ないデータからの学習能力の高さを示すものだと言えます。
マルチモーダル性と中核的能力
長文脈理解能力以外にも、Gemini 1.5シリーズは高度なマルチモーダル性と、優れた中核的能力を有しています。
画像理解では、複雑な推論を必要とするMMUM(91.1%)やMathVista(63.9%)といったタスクで新記録を樹立しました。また、医療文書の理解を問うDocVQAでは93.1%、インフォグラフィックスの理解を問うInforgraphicVQAでは81.0%を達成するなど、幅広いベンチマークで高いパフォーマンスを示しています。
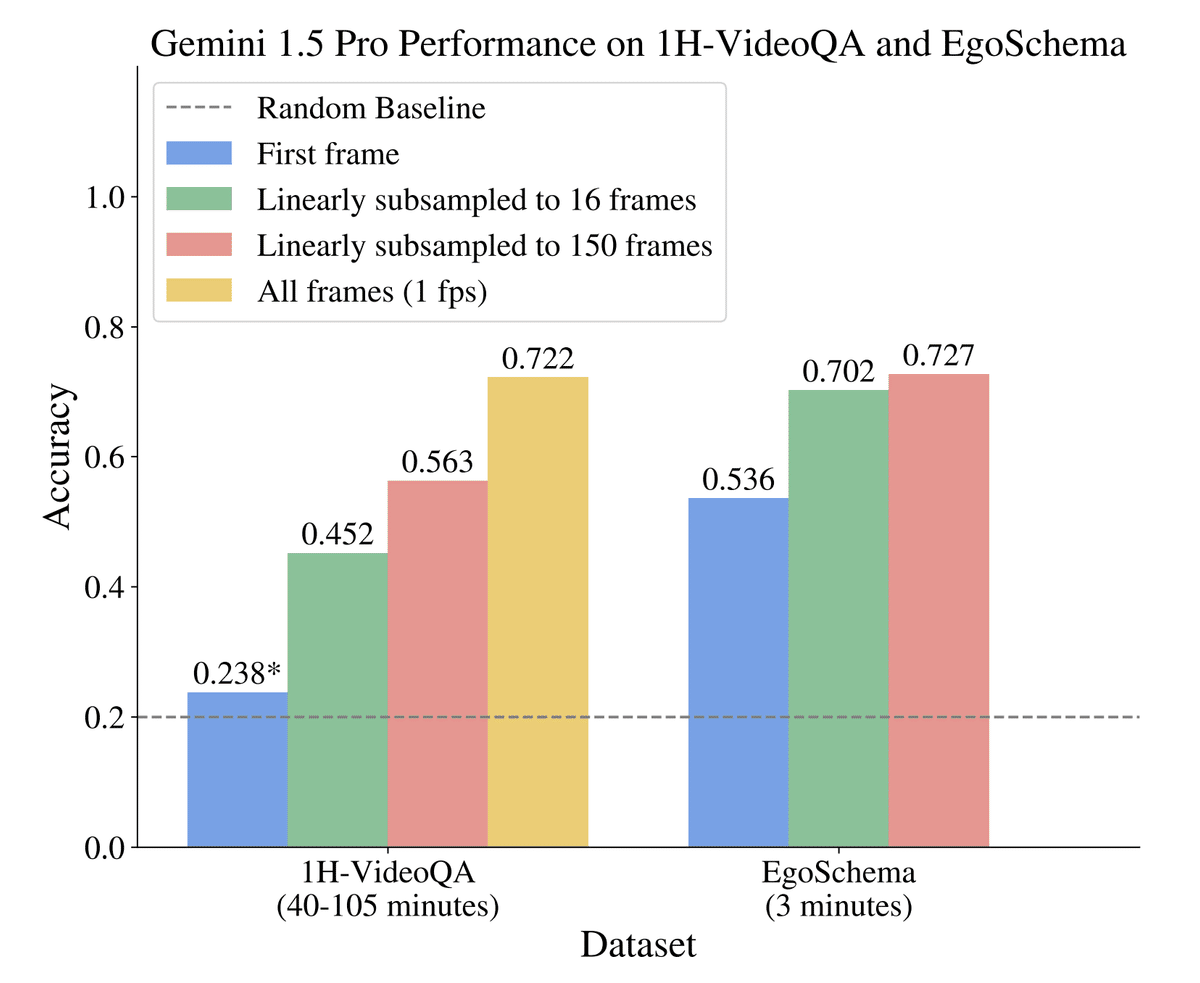
ビデオ理解でも、40分から105分の長尺動画に関する質問応答を行う新しいベンチマーク「1H-VideoQA」を用意し、Gemini 1.5 Proがその有効性を証明しました。以下は、1H-VideoQAにおけるGemini 1.5 ProとGPT-4Vの性能比較です。
一方、音声認識の分野では、15分の長音声を高精度(WER 5.5%)で書き起こすことに成功しています。
さらに、テキストを扱う中核的なタスクにおいても、Gemini 1.5 Proは旧世代のGemini 1.0シリーズを上回る成績を収めています。例えば、専門的な質問応答を行うExpertise QAタスクでは、以下のようにGemini 1.0シリーズを大きく上回る精度を達成しました。

数学や科学、論理推論、プログラミング、多言語対応、指示書の理解など、あらゆる分野で従来モデルを凌駕しているのです。
安全性とセキュリティ、倫理的配慮
一方で、Gemini 1.5シリーズの開発においては、安全性とセキュリティ、倫理的な配慮も欠かせません。DeepMindのチームは、責任あるAI開発のためのプロセスを丁寧に踏んでいます。
具体的には、有害なコンテンツの生成を防ぐためのフィルタリングや、攻撃的な入力に対する堅牢性の評価、プライバシー保護のための匿名化処理など、様々な角度から安全性を担保する取り組みが行われています。
また、モデルの公平性や説明責任についても綿密なチェックが行われており、技術的に優れているだけでなく、倫理的にも健全なAIの開発を目指しているのです。
今後の展望
Gemini 1.5シリーズは、大規模言語モデルの新しい可能性を示した画期的な成果だと言えます。しかし、同時に克服すべき課題も明らかになりました。
超長文脈言語モデルの評価手法については、まだ発展の余地が大いにあります。より現実世界に即した大規模なベンチマークの構築や、人間との能力比較など、体系的な評価フレームワークの確立が求められるでしょう。
また、安全性や倫理的な課題についても、技術の進歩に合わせて継続的に議論と対策を行っていく必要があります。
大規模言語モデルは社会に大きな影響を及ぼす可能性を秘めているだけに、慎重かつ大胆に開発を進めていくことが肝要だと言えます。
さいごに
Google DeepMindのGemini 1.5シリーズは、AIの新しい地平を切り拓く野心的な取り組みです。超長文脈の理解、高度なマルチモーダル性、優れた中核的能力は、従来の大規模言語モデルの限界を大きく超える成果と言えるでしょう。
一方で、安全性や倫理的な課題への真摯な取り組みも欠かせません。AIの健全な発展のためには、技術的なブレークスルーと社会的な議論の両輪が重要だと改めて感じさせられます。
Gemini 1.5シリーズの登場は、まさにAIの新時代の幕開けを告げる出来事だったのではないでしょうか。今後のGeminiプロジェクトの進展から目が離せません。