
【論文瞬読】LLMの知識ギャップに挑む:複数モデルの協調と競合が切り拓く新たな可能性

こんにちは!株式会社AI Nestです。今日は、大規模言語モデル(LLM)の知識ギャップに関する興味深い論文を紹介したいと思います。
タイトル:Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
URL:https://arxiv.org/abs/2402.00367
所属:University of Washington, University of California, Berkeley, The Hong Kong University of Science and Technology, Carnegie Mellon University
著者:Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
LLMは自然言語処理の分野で大きな注目を集めていますが、モデルの知識ギャップは避けられない問題です。情報の欠落や古い情報などによって、LLMが不適切な応答をしてしまうことがあるのです。
そこで、この論文の著者らは、LLMの知識ギャップを特定し、適切に答えを控える手法を提案しています。彼らは既存のアプローチの問題点を指摘し、複数のLLMの協調と競合に基づく新しいアプローチを導入しました。
既存アプローチの問題点
著者らは、LLMの知識ギャップに対処するための既存のアプローチを分析し、いくつかの問題点を指摘しています。
キャリブレーションベースのアプローチ:モデルの信頼度スコアを較正し、答えを控えるかどうかの閾値を設定する手法。ただし、知識ドメイン間の汎化性能に課題がある。
トレーニングベースのアプローチ:LLMの隠れ層の表現を分析したり、外部の検証器を訓練したりする手法。しかし、訓練データセットへの依存が高い。
プロンプトベースのアプローチ:LLMに自己反省を促すプロンプトを与える手法。ただし、LLMの自己反省能力には疑問が残る。

これらのアプローチは、ヘルドアウトセットへの過度の依存や自己反省の失敗など、いくつかの問題点を抱えているのです。
COOPERATEとCOMPETE:LLMの知識ギャップに立ち向かう2つの手法
著者らが提案しているのは、COOPERATEとCOMPETEという2つの手法です。これらは、複数のLLMの協調と競合に基づくアプローチで、既存の手法の問題点を克服することを目指しています。

COOPERATE:協調による知識ギャップの特定
COOPERATEは、複数のLLMが協力して知識ギャップを特定する手法です。まず、あるLLMが質問に対する答えを生成します。次に、他のLLMがその答えに対してフィードバックを提供。専門家としての役割を与えられた複数のLLMが、それぞれの観点から答えの正誤を判断するのです。
最終的に、別のLLMが司会者となって、すべてのフィードバックを統合。答えを控えるかどうかの最終決定を下します。このようにLLM間の協調を通じて、知識ギャップを効果的に特定することができます。
COMPETE:競合による知識ギャップの特定
一方、COMPETEは、LLM間の競合に基づく手法です。まず、あるLLMが質問に対する答えを生成します。次に、他のLLMが矛盾する情報を含む代替答えを提示。元のLLMがその代替答えに影響を受けて答えを変更するかどうかを観察します。
答えが変更された場合、元のLLMの知識にギャップがあると判断されます。このように、LLM間の競合を通じて、知識ギャップを明らかにするのです。
実験結果
著者らは、3つのLLM(MISTRAL-7B、LLAMA2-70B、ChatGPT)と4つの質問応答タスク(MMLU、K-Crosswords、Hellaswag、Propaganda)を用いて、提案手法の有効性を検証しました。
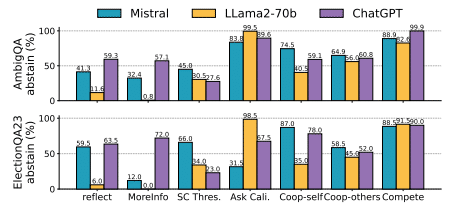
実験の結果、COOPERATEとCOMPETEは12のセッティングのうち9つにおいて、既存の手法を上回る性能を示しました。最大で19.3%の精度向上を達成したそうです。これは、提案手法がLLMの知識ギャップ特定に効果的であることを示唆しています。
また、著者らは提案手法が検索拡張LLMの失敗を特定したり、マルチホップ推論における知識ギャップを明らかにしたりする可能性も示唆しています。
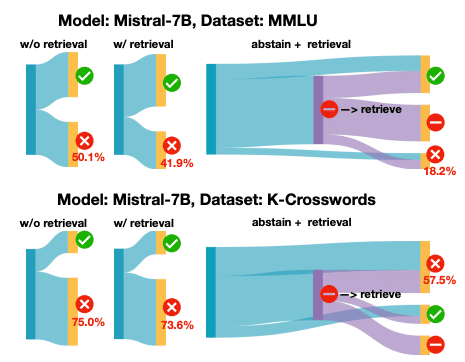
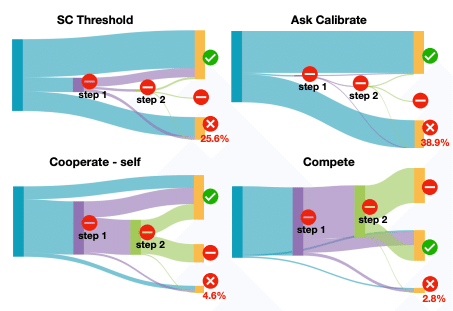
ただし、計算コストや知識ギャップ以外のLLMの限界についての議論は、まだ不十分かもしれません。また、「控える」というLLMの振る舞いがユーザーにとって最適かどうかも検討が必要でしょう。
とはいえ、この論文はLLMの信頼性と安全性を高めるための重要な一歩だと思います。複数のLLMを巧みに組み合わせることで、知識ギャップという難問に立ち向かう新しいアプローチを提案した点は高く評価できます。
今後の展望
今後は、より多様なタスクやモデルでの評価、そして実世界での応用に向けた研究の発展を期待したいですね。LLMの知識ギャップ問題に取り組むことは、より信頼できる自然言語処理システムの実現に不可欠です。
みなさんは、LLMの知識ギャップについてどう思いますか?また、この論文で提案された手法についてどのような印象を持ちましたか?Hallucinateに関する議論はつきませんが、今後の動向も追って行ければと思います!