
【論文瞬読】驚愕の高速化!LLM推論を加速する新手法「CLLM」とは?

こんにちは!株式会社AI Nestです。
今回は、大規模言語モデル(LLM)の推論効率化に関する最新の研究をご紹介します。その名も「Consistency Large Language Models (CLLM)」。なんと、この革新的な手法は、生成品質を維持しつつ最大3.4倍の高速化を達成しているんです!一体どんな魔法を使っているのか、詳しく見ていきましょう。
タイトル:CLLMs: Consistency Large Language Models
URL:https://arxiv.org/abs/2403.00835
所属:Shanghai Jiao Tong University, University of California San Diego
著者:Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, Hao Zhang
CLLMの概要
CLLMは、並列デコード手法であるJacobiデコーディングの効率を大幅に向上させるために特化した新しいモデルファミリーです。既存の効率的なLLM推論手法とは異なり、追加のアーキテクチャコンポーネントやドラフトモデルを必要とせず、事前学習済みLLMから直接適応されるのが大きな特徴です。
Jacobiデコーディングとは?
CLLMを理解するためには、まずJacobiデコーディングについて知っておく必要があります。Jacobiデコーディングは、LLMの逐次的なデコードプロセスを並列化することで効率化を図る手法です。以下の図は、Jacobiデコーディングの概要を示しています。
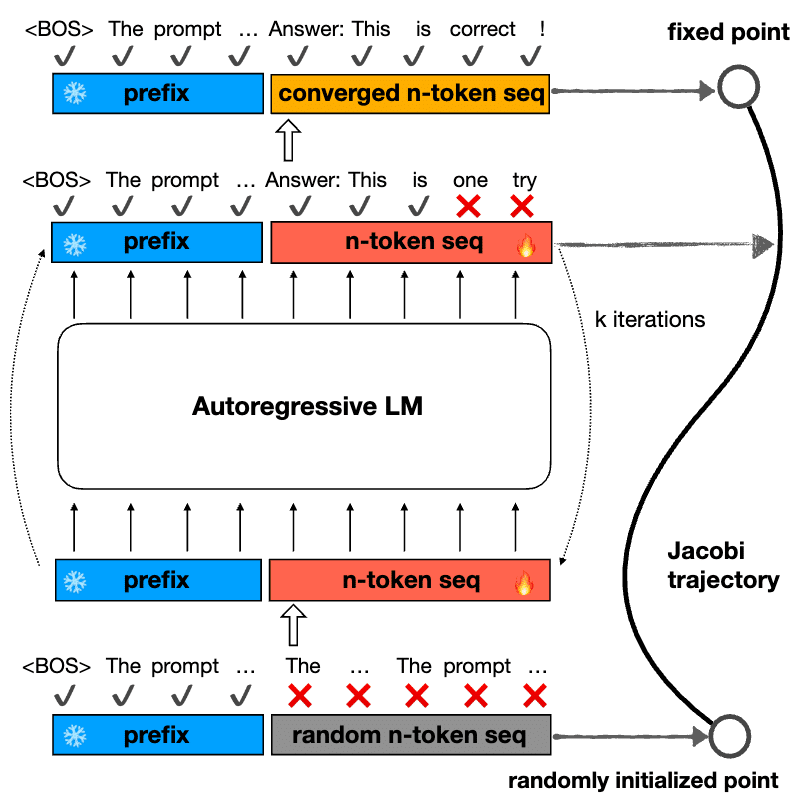
しかし、従来のLLMではその効果が限定的でした。CLLMは、まさにこの問題を解決するために開発されたのです。
CLLMの高速化の秘密
さて、CLLMがどのようにして高速化を達成しているのか、その秘密に迫ってみましょう。実は、CLLMには「ファストフォワーディング」と「ステーショナリートークン」という2つの興味深い現象が観察されているんです。
以下の図は、ターゲットLLMとCLLMのJacobi軌跡を比較したものです。CLLMがより効率的に収束していることがわかります。

ファストフォワーディング
ファストフォワーディングとは、CLLMが1回の前向き計算で複数のトークンを正しく予測できる現象のことです。通常のLLMでは1回の計算で1つのトークンしか生成できませんが、CLLMはこの制限を打ち破っているのです。
ステーショナリートークン
ステーショナリートークンとは、先行するトークンが不正確であっても、CLLMが正しいトークンを予測し維持できる現象を指します。これにより、不連続な正しいトークンを同時に拡張することができるんです。
コロケーションの学習
これらの現象の鍵を握っているのが、言語の重要な概念である「コロケーション」の学習だと著者らは考察しています。コロケーションとは、単なる偶然以上の頻度で共起する一連の単語や用語のことです。CLLMはこれを上手く学習することで、驚異的な高速化を実現しているのです。
実験結果と今後の展望
CLLMは様々なベンチマークで評価され、その有効性が実証されています。以下の表は、CLLMと他の手法を比較したものです。
Table1, LLaMA2-7Bをバックボーンモデルとして使用した、蒸留ドラフトモデルを使用した推測デコーディング、Medusa、ファインチューニングモデルとCLLMの比較
特に特定のドメインでは、生成品質を維持しつつ最大3.4倍の高速化を達成しているんです。

さらに、CLLMは他の効率化手法とも組み合わせ可能で、より一層の高速化が期待できます。
以下の図は、GSM8Kデータセットにおける、異なるn-tokenシーケンス長で学習したモデルの精度と高速化を示しています。
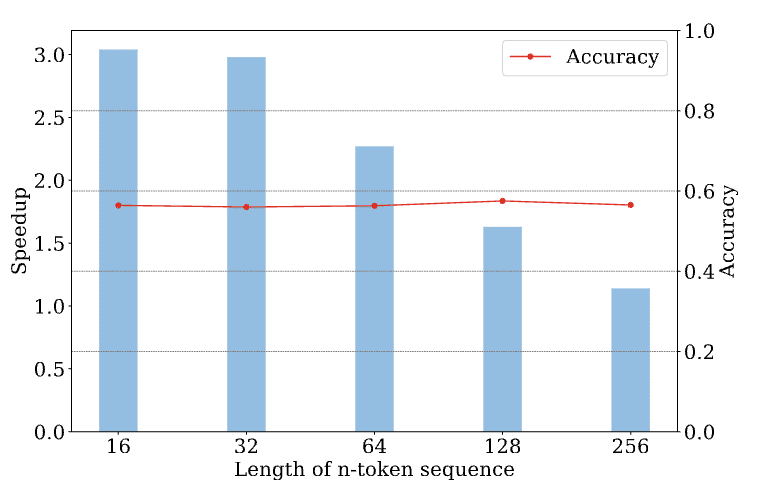
とはいえ、CLLMにも課題がないわけではありません。トレーニングにはJacobi軌道を収集するオーバーヘッドがあるのです。でも、トレーニング済みモデル自体の出力をサンプルとして使うことで、この問題も解決できるかもしれません。
結論
CLLMは、LLMの推論効率化に向けた画期的なアプローチだと言えるでしょう。シンプルで扱いやすく、高い性能を示すCLLMは、実用上の利点も大きいのです。今後、この手法がLLMの事前学習にも適用され、さらに強力で効率的なモデルが実現されることに期待が高まります。
LLMの世界は日進月歩で、新しい手法が次々と登場しています。CLLMもその一つですが、これからも目が離せない分野ですね。私たちは、これらの技術革新を追いかけ、理解を深めていくことが重要です。そうすることで、より豊かで効率的な自然言語処理の未来を切り拓いていけると信じています。