
【論文瞬読】メモリを気にせずバッチサイズを大きくできる!? Inf-CLが実現する革新的なContrastive Learning

こんにちは!株式会社AI Nestです。今回は、最近話題の論文「Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss」について解説していきます。CLIPやSimCLRなどのContrastive Learningで悩ましいGPUメモリの制限に、画期的なソリューションを提案している論文です。
タイトル:Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
URL:https://arxiv.org/abs/2410.17243
所属:Zhejiang University、DAMO Academy, Alibaba Group、Nanyang Technological University
著者:Zesen Cheng, Hang Zhang, Kehan Li, Sicong Leng, Zhiqiang Hu, Fei Wu, Deli Zhao, Xin Li, Lidong Bing
1. なぜこの研究が重要なのか?
1.1 Contrastive Learningとは
まず基本的なところから。Contrastive Learning(対照学習)は、似ているデータ同士を近づけ、異なるデータ同士を遠ざけるように学習を行う手法です。例えば、「猫の画像」と「これは猫の写真です」というテキストは近くに、「これは犬の写真です」というテキストとは遠くに配置されるように学習します。
1.2 バッチサイズの重要性と問題点
従来の実装では、下図のように類似度計算のためにすべての画像-テキストペアの組み合わせをメモリに保持する必要がありました。これが、メモリ使用量が二次関数的に増加する原因となっています。

例えば、ViT-B/16モデルでバッチサイズ64kの場合、モデル自体は5.24GBのメモリしか使用しないのに対し、損失計算に66GBものメモリが必要になってしまいます。これは現実的ではありませんよね。
2. Inf-CLの革新的なアプローチ
2.1 タイルベース計算の魔法
そこでInf-CLは、下図のような新しいアプローチを提案しています。

巨大な類似度行列を小さなタイル(区画)に分割し、必要な部分だけを順番に計算していきます。これにより、メモリ使用量を劇的に削減することに成功しました。
下図は、従来手法とInf-CLのメモリ使用量の比較を示しています。

A800 GPUの80GBという制限に対して:
従来手法:バッチサイズの増加とともに二次関数的に増加
Inf-CL:線形的な増加に抑制され、はるかに大きなバッチサイズが実現可能
2.2 マルチレベルタイリングの賢さ
Inf-CLはさらに、計算を二段階で最適化します:
GPU間レベル:
複数のGPUで計算を分散
リング状の効率的なデータ通信
各GPUが担当する行列の一部を計算
GPU内レベル:
SRAMとHBMのデータ転送を最適化
融合カーネルによる計算の効率化
タイル単位での逐次的な処理
3. 驚きの実験結果
3.1 メモリ効率の劇的な改善
具体的な数値で見てみましょう。
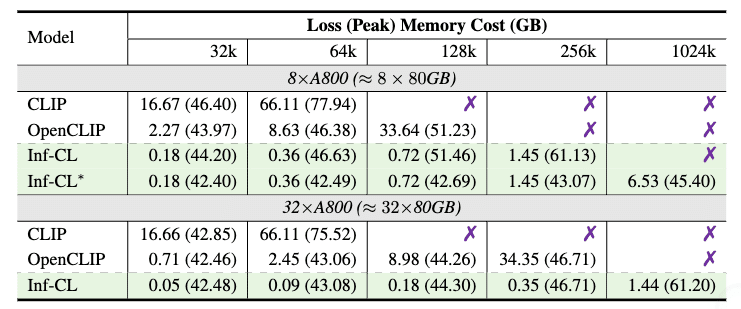
この表が示すように:
8台のA800 GPUでの64kバッチサイズ時:
CLIP:66.11GB
OpenCLIP:8.63GB
Inf-CL:わずか0.36GB!
さらに32台構成では1024kものバッチサイズまでスケール可能
3.2 速度は維持したまま
メモリ効率を改善すると処理速度が犠牲になるのでは?という疑問に対する答えが、以下のグラフです。

驚くべきことに、Inf-CLは従来手法と同等の学習速度を維持しています:
バッチサイズ64kでの1エポックあたりの学習時間:約59時間
バッチサイズを増やしても、処理時間は線形的な増加に抑えられている
4. 実践的な示唆と今後の展望
4.1 現場での活用について
この研究の意義は、既存のハードウェアでより効率的な学習が可能になることです。特に:
より大規模なモデルのトレーニングが現実的に
コスト効率の大幅な改善
実験のイテレーションを加速可能
4.2 注意点と課題
もちろん、完璧な手法というわけではありません:
極端に大きなバッチサイズでは性能が低下する可能性
ハイパーパラメータの調整が重要
学習率のスケーリング
十分な学習エポック数の確保
データセットの規模との関係性を考慮する必要あり
4.3 今後の発展性
この研究は以下のような方向への発展が期待できます:
他の深層学習タスクへの応用
さらなるメモリ最適化手法の開発
分散システムでの効率化
より大規模なデータセットでの検証
5. まとめ
Inf-CLは、Contrastive Learningにおけるメモリ制限という根本的な課題に対する、非常にエレガントな解決策を提示しています。理論的な美しさと実用性を兼ね備えた、まさに「技術的ブレークスルー」と呼ぶにふさわしい研究だと言えるでしょう。
特に印象的なのは、「制約をどう回避するか」ではなく、「問題の本質をどう解決するか」というアプローチを取っている点です。これは、他の深層学習の課題に取り組む際にも参考になる考え方ではないでしょうか。
最後に、この研究が示唆するように、深層学習の世界ではまだまだブレークスルーの余地が残されています。私たちエンジニアにとって、とてもワクワクする時代が続きそうですね!