
【論文瞬読】AI界の常識を覆す!?Chain-of-Thoughtの真の実力を徹底解剖

こんにちは!株式会社AI Nestです。今日は、AI界で大きな話題を呼んでいる研究について、熱く語らせていただきます。その研究とは、「Chain-of-Thought (CoT) プロンプティング」の効果を徹底的に分析したものです。みなさん、準備はいいですか?では、潜入開始です!
タイトル:To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
URL:https://arxiv.org/abs/2409.12183
所属:The University of Texas at Austin、Johns Hopkins University、Princeton University
著者:Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, Greg Durrett
1. Chain-of-Thoughtって何? AIの思考プロセスを解き明かす魔法の杖?
まずは、Chain-of-Thought(CoT)について簡単におさらいしましょう。
CoTとは、大規模言語モデル(LLM)に対して、「ちょっと待って、一歩ずつ考えてみよう」と言うようなものです。つまり、LLMに段階的な思考プロセスを生成させることで、複雑な問題解決能力を引き出す手法なんです。
例えば、「2 + 2 × 3 = ?」という問題に対して、普通のAIなら「はい、答えは8です!」と即答するかもしれません。でも、CoTを使うと...
まず、掛け算を先に計算します。2 × 3 = 6
次に、その結果に2を足します。6 + 2 = 8
したがって、答えは8です。
...というように、人間のように「考える過程」を示してくれるんです。すごいでしょ?
この手法は、AIに人間らしい推論能力を持たせる魔法の杖として、多くの研究者や開発者から注目を集めてきました。でも、本当にそうなのでしょうか?
2. 衝撃の研究結果!CoTの真の姿が明らかに
ここで登場するのが、今回紹介する研究です。テキサス大学オースティン校の研究チームが、CoTの効果を徹底的に分析しました。その結果は...衝撃的でした!
2.1 研究方法:超大規模な分析と実験
研究チームは、まず100以上のCoT関連論文をメタ分析しました。さらに、14種類のLLMを使って20のデータセットで独自の評価実験を行いました。これは、まさに「CoT総力戦」と言えるでしょう。
2.2 意外な結果:CoTが効くのは限られたタスクだけ?
そして、判明したのは...
CoTは主に数学や論理的推論のタスクでしか効果がない!
えっ、マジで?そうなんです。他の種類のタスク、例えば常識的推論や知識を問う質問では、CoTはあまり効果がないか、場合によってはパフォーマンスを下げることもあるそうです。
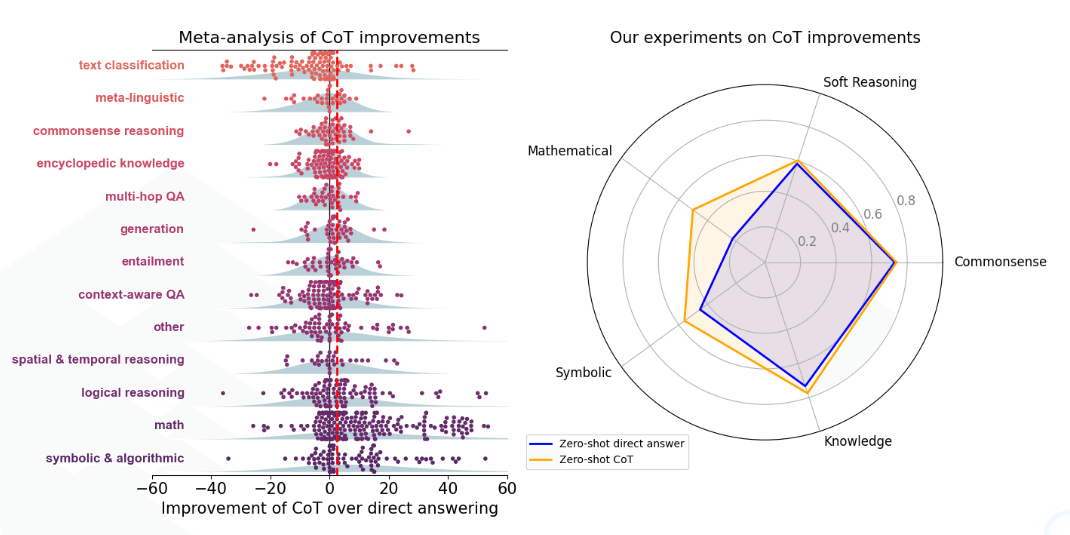
Figure 1を見てください。左側のグラフは、既存研究のメタ分析結果を示しています。右側のグラフは、研究チームが行った独自の実験結果です。どちらも、数学(Math)と記号的推論(Symbolic)のタスクでCoTの効果が顕著であることを示しています。一方で、常識(Commonsense)や知識(Knowledge)を問うタスクでは、効果がほとんど見られません。これは驚くべき発見ですよね!
3. CoTの効果を深掘り:なぜ数学で効くの?
では、なぜCoTは数学や論理的推論のタスクで特に効果を発揮するのでしょうか?研究チームは、さらに踏み込んだ分析を行いました。

3.1 MMLU(大規模多タスク言語理解)データセットの分析
研究チームは、MMMLUという多様なタスクを含むデータセットを詳しく分析しました。すると、CoTの効果が主に「=(イコール)」を含む問題、つまり数式を扱う問題に集中していることが分かったんです。
Figure 4を見てください。このグラフは、質問や回答に「=」が含まれるかどうかでCoTの効果を比較しています。驚くべきことに、「=」を含む問題でCoTの効果が圧倒的に高いことが分かります。つまり、CoTは主に数学的な問題で威力を発揮するんです!
3.2 数学タスクの解剖:計画と実行の2段階
さらに、数学タスクを「計画段階」と「実行段階」に分解して分析しました。その結果、CoTは主に「実行段階」、つまり計算のステップを追跡する部分で効果を発揮していることが判明しました。
つまり、CoTは「数学の問題をどう解くか」を考えるのではなく、「計算の手順を正確に追う」のが得意なんです。ちょっと意外ですよね?
4. CoTvs外部ツール:AIの限界が見えた?
研究チームは、さらに踏み込んで、CoTと外部の数式ソルバーを比較しました。結果は...

外部ソルバーの方が、CoTよりも高性能!
Figure 6を見てください。このグラフは、数学と論理的推論のタスクにおいて、CoTと外部ツールの性能を比較しています。青い棒(Plan + Tool Solver)が外部ツールを使用した場合の性能で、ほとんどのケースでCoT(オレンジの棒)を上回っています。
これは、現在のAIの限界を示すと同時に、AIと外部ツールを組み合わせることの重要性を示唆しています。つまり、「AI+ツール」のハイブリッドアプローチが、未来の方向性かもしれません。
5. この研究が示す未来:AIの進化の道筋
さて、この研究結果から、私たちは何を学べるでしょうか?
5.1 CoTの戦略的使用
CoTは万能ではありません。タスクの性質に応じて、CoTを使うかどうかを選択する必要があります。特に、計算コストとパフォーマンスのバランスを考えると、数学や論理的推論以外のタスクでは、別のアプローチを検討した方が良いかもしれません。
5.2 AIと外部ツールの融合
AIの弱点を外部ツールでカバーする。この考え方は、今後のAI開発の重要な方向性になるでしょう。AIにすべてを任せるのではなく、AIの長所と外部ツールの長所を組み合わせる「ハイブリッドAI」の時代が来るかもしれません。
5.3 新たな推論手法の探求
数学以外のタスクでAIの推論能力を向上させるには、CoTとは異なるアプローチが必要かもしれません。この研究は、新たな推論手法の開発に向けた重要な一歩と言えるでしょう。
6. まとめ:CoTは万能ではない、でも可能性は無限大!
今回の研究は、CoTの限界を明らかにしました。でも、これはAIの可能性を否定するものではありません。むしろ、AIの真の力を引き出すために、私たちはもっと賢く、戦略的にAIを使う必要があるということです。
CoTは、確かにAIに「考える力」を与えました。でも、それはまだ人間の思考の一部を模倣しているに過ぎません。これからのAI研究は、より多様な思考プロセスをAIに実装する挑戦になるでしょう。
みなさん、AIの進化はまだまだ続きます。この先どんな驚きが待っているか、ワクワクしませんか?次回のブログでも、最新のAI研究について熱く語っていきますので、お楽しみに!