
楽々操作!LoRA入門:GUIで手軽に始める注目の追加学習(画像生成AI)

まず初心者用に流れを書いて後で駄文を書きます。
※かたらぎさんのリンクから来た人は駄文-〇AIは画像のキャンプションで学習してますのとこに目的のものがあります。
・kohya GUIを利用してやります。kohya GUIはwebui 1111とは別の環境です。
https://github.com/bmaltais/kohya_ss
・SD2系の人はwebui extensionからadditionnal-networkもインストールしておきましょう
初心者のためのLoRA
1.学習したい画像をフォルダにいれます。後々のために以下の構成にしてください。
・適当なフォルダ|<数字><アンダーバー><アルファベット><半角スペース><名詞>
ex) Aikimi\100_aik girl
<アルファベット>がpromptのトリガーになるらしい
2.画像と同名のtxtにキャプションをつけます。
ここではkohya_GUIを使って自動でやる説明します。
Utilities-Captioningで自動でつけられるアルゴリズムが選べるので好きな奴を使って作成します。以下はWD14 captioningの例です。
・赤下線に1のフォルダを設定します
・caption imagesを押して待ちます

3.ベースモデルの設定をします。
Dreambooth LoRAタブに行き学習したいモデルを設定します。
ここではWD1.5 beta2を設定してます。
〇v2とv_parameterizationはSD2系(WD1.5)ならチェックを入れてください
configuration fileは設定ファイル用です。save asで適当な名前を付けて変更するたびにsave押していきましょう

4.入力フォルダの指定をします。
・image folderに学習画像が入っている一つ上のフォルダを設定します(注意!)
・outputとmodel nameはそのままの意味です
ex)stable-diffusion-webui\extensions\sd-webui-additional-networks\models\lora

5.パラメータの設定をします。
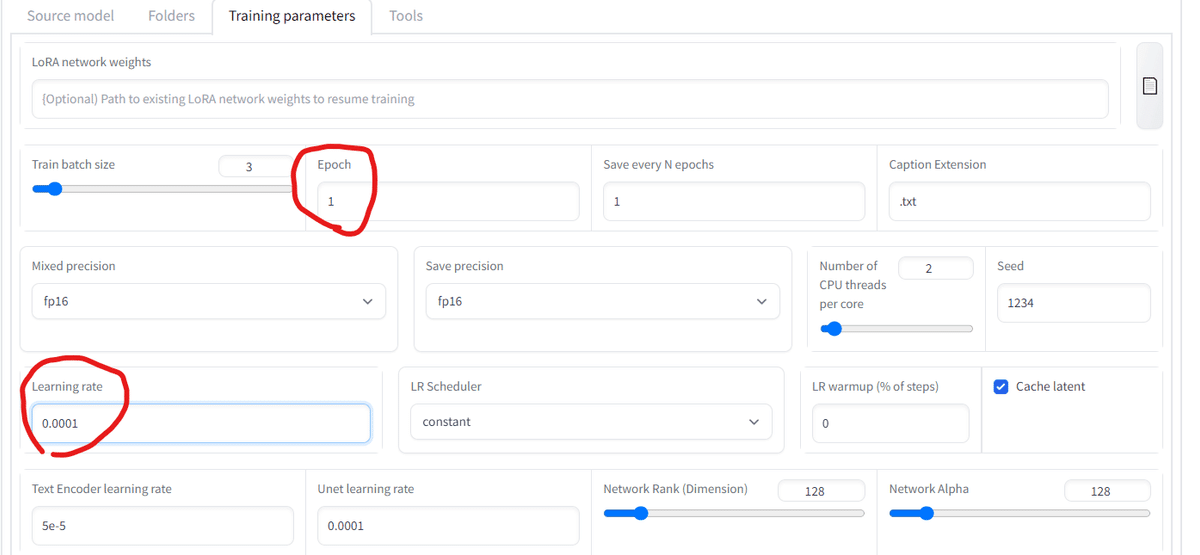
5-1 学習率の設定をします。
・こんなイメージです。
(Learning rate) x (step) x (画像枚数) x (Epoch)
〇Learning rate : 学習率
〇step : 1で設定したフォルダ名(多分1画像あたり何回みたいな感じ)
〇Epoch:学習繰り返し回数(5とかにしてsave eve…を1にしておけば繰り返しごとにLoRAが作られる
・過学習気味だな~とおもったらLearning rateを下げたりフォルダ名を小さくしてみましょう。低めにしてEpochで調整して寝る前などにかけ流せば、epochごとのLoRAモデルができます。
◆precisionはよくわからんけどfp16にしてる
◆encoderとかunetとかschedulerとかnetworkとか他にも弄りがいは有り
5-2.解像度とバッチを指定します。
自分のグラボに合わせて解像度とバッチを指定します。
高解像で学習するとその分高解像で分身とか崩れるとかが少なくなります(多分)
実行時にmemoryエラーが出た際はこれらの数値を小さくしてみましょう

6.Train modelを押して学習開始!
以上で終了です。完成したのを
additional-networkの欄から適用してください(有効化忘れずに!)

駄文
以下適当な駄文です。すべての文に多分を追加してください。
〇LoRAは差分データです。
つまり学習元と離れている情報を記録してます。
例えば、絵柄を再現せずにキャラの特徴を学習したいならその絵柄に近いモデルを学習元にしましょう。そしてそれを別にモデルに適用しましょう。
・3Dモデルで再現させてリアル系で学習
・コスプレモデルをリアル系で学習
・目的のキャラをその作者のほかの画像使って過学習気味にモデルを作ってそれベースで学習
など
〇AIは画像のキャプションで学習してます。
当たり前と思うかもしれませんがAIの気持ちになって考えましょう
例えば以下の画像のキャラLoRAを作成したいとします。

特徴を持ったLoRAを作成したいときは再現したい箇所をキャプションから消しましょう。キャラを学習したいなら「1girl,long_hair,white_hair,blue_eyes,school_uniform,white_background」
→「1girl,school_uniform,white_background」
とキャプションを変更しましょう。1girl,long_hair,white_hair,blue_eyesがこの少女だ!と学習するより、1girl=この少女と学習したほうが再現しやすいのは自明ですね。
LoRAに限ったことではないですが分けたくないものはキャプションから消しましょう。
逆に分けたいものはキャプションに入れましょう。例えばwhite_backgroundを消して学習すると背景のデフォルトがwhiteになりやすくなります。
特に背景の指定が入ってないのに豪華な背景が出やすいモデルは背景がうまく分けられずにそれをAI君がデフォ(1girlとかに紐づいてる)だと思っているからですね。
質のいい画像にはmasterpieceとかつけずに学習するほうがいいモデルができると思います。(それをデフォにする)。
消すのはいちいちやってられないのでフォルダ内のtxtファイルすべてから任意の文字列を消すプログラムを作成しました。
1.フォルダ内にコピー
2.右クリック-powershellで実行
3.任意の文字列入力してenter
中身見れば置換とかにも変えられます(アンダーバーをスペースにするとか)。
〇せっかくだしVRAMのギリギリをせめたい。
学習するときの大体の計算方法です。
「解像度 x 解像度 x batch数」をベースに計算しましょう。
ctrl+shift+escでタスクマネージャーが開けます。そこのパフォーマンスのGUIの欄の専用GPUメモリが自分の使えるVRAMです。
実行中にそこを見て空いていたら上の式を見てその分好きなところを増加させてみましょう

いかがでしたか?
とりあえず思いつくままに書いてみました。
タイトルはGPT4に考えさせました。
特定の作者狙い撃ちなどは個人の範囲で楽しみましょう
間違いとか補足したい人はコメントで見た人のためになるようにしてね。
loconとかlohaとかGUIでわかりやすくできたら追記したいね
投げ銭用
以下投げ銭用に有料記事を設定。
何もないのもあれなのでLoRAの値をマイナスに適用することによる品質向上を狙ったファイル(WD1.5系用)を置いておきます。
bad aestheticな画像5088枚で学習しました。
ここから先は
¥ 500
Amazonギフトカード5,000円分が当たる
モチベーションの増加につながるのでよろしければサポートお願いします。