
[ComfyMaster56] ComfyUIでの「Wan2.1」で学ぶ最新動画生成モデルの内部(Text to Video編)

Alibabaが公開した動画生成モデル「Wan2.1」をComfyUIが公式サポートを行いました。AICUの調査によると10GB程度のローカルGPUやGoogle Colabといった環境で動作させることができます。
本稿では、Google Colabでの「Wan2.1」の動作から、最先端の動画生成AI、特に Text to Video の内部を分析していきます。
Google Colabのノートブックは文末にてメンバーシップ向けに提供します。
Colabのほうは、まずT4GPU(通常メモリ)で実験してみます。
ワークフローについてはComfy-OrgがHuggingFaceで提供しています。
Text to Videoを試す際に…
バグ解決:SaveWEBMが見つからない!
ワークフローを開くとまず、こんなエラーが出ます。SaveWEBMが見つからない、という内容ですが、調べてみると、これはCore Nodeという、ComfyUI公式が提供すべきノードです。まだ正式にリリースされていないのですが、mp4やAnimated-WebP形式ではなくWebMがサポートされるとなると、ブラウザ等で動画再生ができて便利ですが、一方では編集環境が揃っているわけではないので、変換が必要です。変換が必要という意味ではAnimated-WebPもあまり変わらない使い勝手なので、まずは慌ててでも先にリリースしてくれたComfy Orgには感謝ですが、ユーザーとしては静観するか、自分で開発するかというところです。
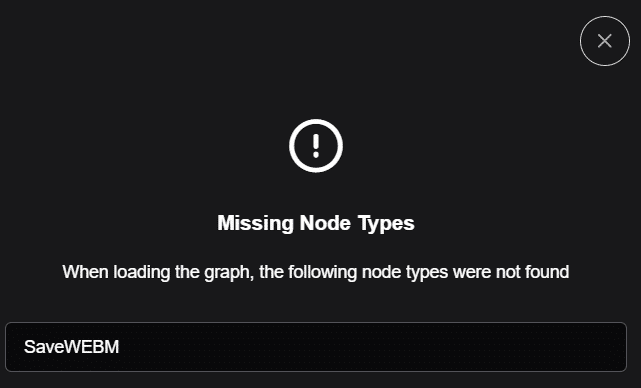
肝心の動画保存が動かないなら…といって諦めてしまいそうですが、実はよく見ると、SaveAnimatedWEBPノードが並列に接続されていますので、SaveWEBMは削除してよいことがわかります。削除しましょう。
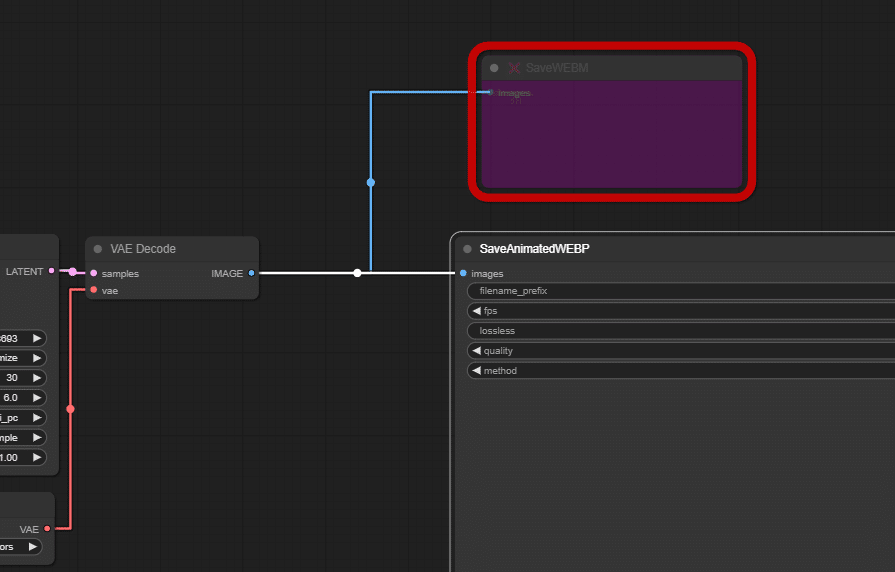
非常にシンプルなワークフロー
全体像を見ていただけると「非常にシンプルなワークフローである」という印象を持ちます。
参考までにHunyuanVideoのワークフローを紹介します。
必要なモデルの配置
次に「Queue」ボタンを一度押してみましょう。必要なモデルの配置とメモリの確保ができないとエラーになります。前回記事でも解説していますのと、提供するipynbでは適切なディレクトリにダウンロードされたファイルが保存されるように設定してありますが、以下まとめです。
①拡散モデルから1つ選択 → ComfyUI/models/diffusion_models に配置
以下の4つの動画生成モデルのうち、まずは「Text-to-video 1.3B」を使いましょう。
Text-to-video 14B: 480Pと720Pの両方に対応
Image-to-video 14B 720P: 720Pに対応
Image-to-video 14B 480P: 480Pに対応
Text-to-video 1.3B: 480Pに対応
②umt5_xxl_fp8_e4m3fn_scaled.safetensors → ComfyUI/models/text_encoders に配置
③clip_vision_h.safetensors → ComfyUI/models/clip_vision に配置
image to videoに必要なので、T2Vでは使いません。
④wan_2.1_vae.safetensors → ComfyUI/models/vae に配置
ワークフロー全体を見るとこのような感じです。
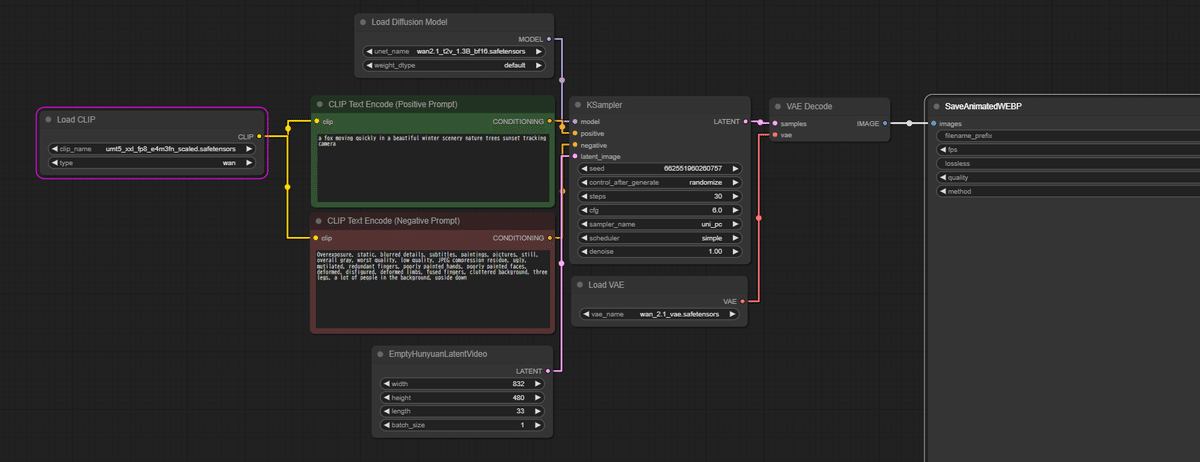
Wan2.1の特徴
Wan2.1は、主に以下の要素から構成される生成プロセスを持っています。
・Video Diffusion DiT:潜在空間での動画生成
・テキストエンコーダ (T5):テキストプロンプトのエンコード
・3D Variational Autoencoder (Wan-VAE)
これらの要素が連携して、テキストや画像から高品質な動画を生成します。
動画の生成は Video DiT モデル
Load Diffusion Modelを使って wan2_1_t2v_1.3B_bf16.safetensorsをロードして KSamplerに入れます。ここはU-Netによって実装されている点からStable Diffusionの1.xや2.x、SDXL系と近いようですが、Video DiT (diffusion transformer)モデルと呼ばれる手法を使っています。
scalable diffusion models with transformers
DiT(Diffusion Transformer)は 元祖Stable Diffusion XLまでに使われていたUNetベースのDiffusionモデルよりも性能がよく、OpenAIの動画モデルSoraでも使われていることが発表されています。
Video Diffution Model (VDM)
Video Diffusion Transformer (Video DiTもしくはVDT)
Wan2.1は、主流の拡散トランスフォーマーのパラダイム内で、フローマッチングフレームワークを使用して設計されています。モデルのアーキテクチャは、T5エンコーダを使用して多言語テキスト入力をエンコードし、各トランスフォーマーブロック内のクロスアテンションによってテキストをモデル構造に埋め込みます。さらに、線形層とSiLU層を持つMLP(多層パーセプトロン)を使用して、入力された時間埋め込みを処理し、6つの変調パラメータを個別に予測します。このMLPはすべてのトランスフォーマーブロックで共有され、各ブロックは個別のバイアスセットを学習します。我々の実験結果は、このアプローチにより、同じパラメータ規模でパフォーマンスが大幅に向上することを示しています。
データ

膨大な量の画像と動画データからなる候補データセットをキュレーションし、重複排除が行われています。データキュレーションの過程で、基本次元、視覚品質、動きの品質に焦点を当てた4段階のデータクリーニングプロセスが設計されており、堅牢なデータ処理パイプラインを通じて、高品質、多様性、大規模な画像および動画のトレーニングセットを容易に取得できるようになったそうです。
CLIPはGoogleのUMT5
Googleによる「mT5」Multilingual T5は、107 の言語をカバーする言語-言語の変換モデルです。typeは「wan」を指定します。今回の更新で新たに追加されたタイプのようです。
クロスアテンション: 各トランスフォーマーブロックでクロスアテンションを使用し、テキスト情報をモデルに埋め込みます。
MLP (Multi-Layer Perceptron): 入力された時間埋め込みを処理し、6つの変調パラメータを個別に予測するために、線形層とSiLU層を持つMLPを使用します。
T5エンコーダは、入力されたテキストプロンプトを、DiTが理解できる形式(数値ベクトル)に変換する役割を担います。Wan2.1では、多言語に対応したT5エンコーダを使用しており、日本語のプロンプトも利用可能です。
プロンプト
a fox moving quickly in a beautiful winter scenery nature trees sunset tracking camera
(美しい冬の風景、自然の木々、夕日の中を素早く移動するキツネの追跡カメラ)
いつもおなじみの狐耳のComfyUIのキャラクター…ではなく、実写の狐を動かしたいというプロンプトになります。
ネガティブプロンプト
実は最初のバージョンではネガティブプロンプトだけが中国語で書かれていました。
色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走
(明るい色、露出オーバー、静止、ぼやけた詳細、字幕、スタイル、アートワーク、絵画、画像、静止、全体的に灰色、最低品質、低品質、JPEG 圧縮残留物、醜い、不完全、余分な指、下手な手、下手な顔、変形、傷ついた、奇形の手足、癒合した指、静止画像、雑然とした背景、3 本の足、背景に大勢の人、後ろ向きに歩く)
中国語でなければだめ、ということではなく、現在のワークフローでは以下のように英語に修正されています。
Overexposure, static, blurred details, subtitles, paintings, pictures, still, overall gray, worst quality, low quality, JPEG compression residue, ugly, mutilated, redundant fingers, poorly painted hands, poorly painted faces, deformed, disfigured, deformed limbs, fused fingers, cluttered background, three legs, a lot of people in the background, upside down
(露出過多、静止、細部がぼやけている、字幕、絵画、写真、静止、全体的に灰色、最低品質、低品質、JPEG 圧縮残留物、醜い、切断された、余分な指、下手な手、下手な顔、変形、傷ついた、変形した手足、癒合した指、雑然とした背景、3 本の足、背景にたくさんの人がいる、逆さま)
かわいい人形とアイスクリームを持って自撮りをしている赤髪の青年が笑っている
Latent画像はHunyuanLatentVideo
ComfyUIサンプルフロー内ではTencent開発のHunyuanVideoで使われるLatent動画を使っているようです。
16:9に近い画面比率だと1280x720か832x480になるようですが10GB程度のメモリの場合には832x480で試すことをおすすめします。Lengthはフレーム数で、秒16フレームで2秒の設定になっています。
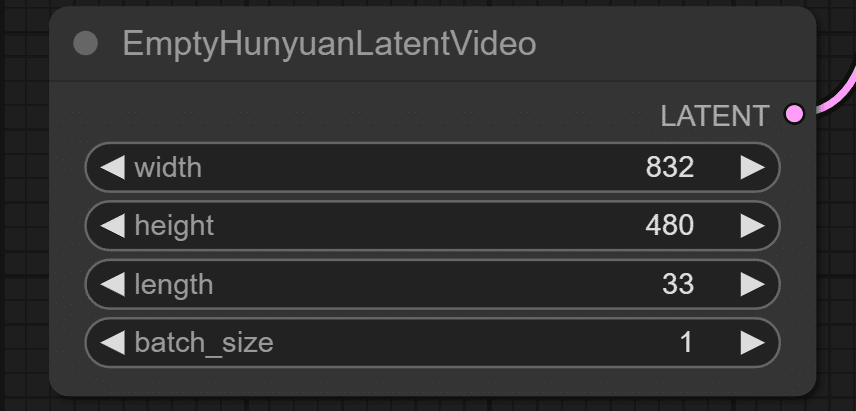
処理としてはこの33フレーム全体での破綻がないようにイテレーションが回わるようです。この33を長くしても、動かない動画が出来上がるだけなので、作りたい映像のフレームレートに合わせて調整していったほうが良さそうです。
LatentのLengthを2秒(33)から20秒(329)にしてもピクリとも動かなったので、様々な実験が必要そうです。
— AICU 「つくる人をつくる」クリエイターのためのAIメディア (@AICUai) March 1, 2025
(L4 GPUで20分ぐらいかかりました) pic.twitter.com/BZckq5IV0w
なおHunyuanVideoのGGUF版も存在するのでWan2.1以外の動画モデルを試してみたい人はどうぞ。
Wan2.1公式のREADMEによると、1280x720は14Bで、1.3Bの小サイズモデルは832x480を指定すべきであるようです。またメモリオフロード機能もあるようなので、VRAMに乗り切らない場合も時間はかかっても生成はできる可能性はあります。
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
VAEはWan2.1専用
Wan2.1の特徴の一つはオリジナルのVAEを提供している点です。

このVAEは生成プロセスにおいて重要な役割を果たします。
VAEは、高次元のデータ(この場合は動画)を、低次元の潜在空間にエンコード(圧縮)し、そこから元のデータをデコード(復元)する役割を担います。
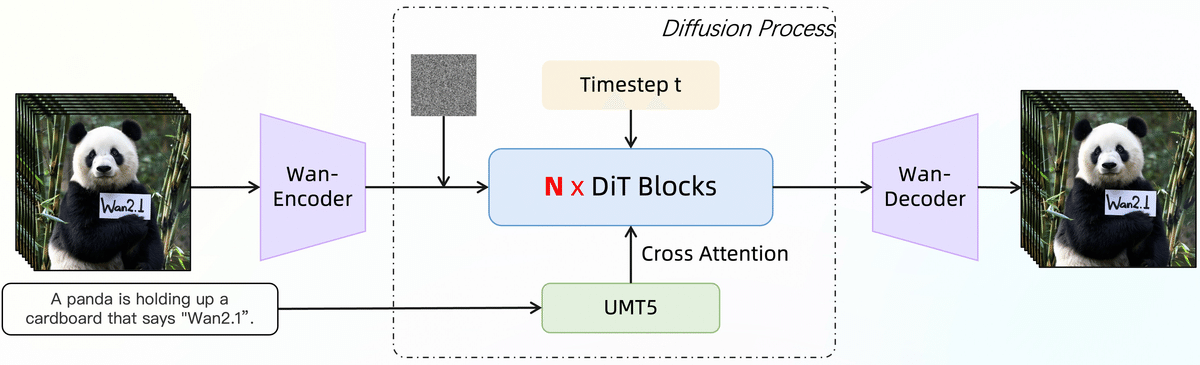
Wan-VAEは、Wan2.1のために特別に設計された、新しい 3D Variational Autoencoder (Wan-VAE) です。従来のVAEとは異なり、動画生成に特化しています。主な特徴として(1)時空間圧縮の改善 として、複数の戦略を組み合わせることで、空間(画像フレームの縦横)と時間(フレーム間の動き)の両方の情報を効率的に圧縮します。そして(2)メモリ使用量の削減です。これにより、より少ないメモリで高解像度の動画を処理できます。さらに(3)時間的因果関係の保証として、動画の各フレームが、過去のフレームの情報のみに依存するように設計されています。これにより、生成される動画の動きが自然になります。これにより他のオープンソースVAEと比較して、優れたパフォーマンスと効率を実現しています。
エンコード、つまり入力された動画を、潜在空間内のより小さなデータ表現(潜在変数)に変換します。これにより、計算負荷を軽減し、効率的な処理を可能にします。そして、デコードで潜在変数から元の動画を再構築します。
長さに制限なく、高解像度(1080P)の動画をエンコード(情報を圧縮)およびデコード(情報を復元)できます。さらに、過去の時間的情報(以前のフレームの動きなど)を失うことなく処理できるため、動画生成タスクに非常に適しています。Wan2.1では、このWan-VAEが、動画を効率的に扱い、高品質な生成を可能にする基盤となっています。
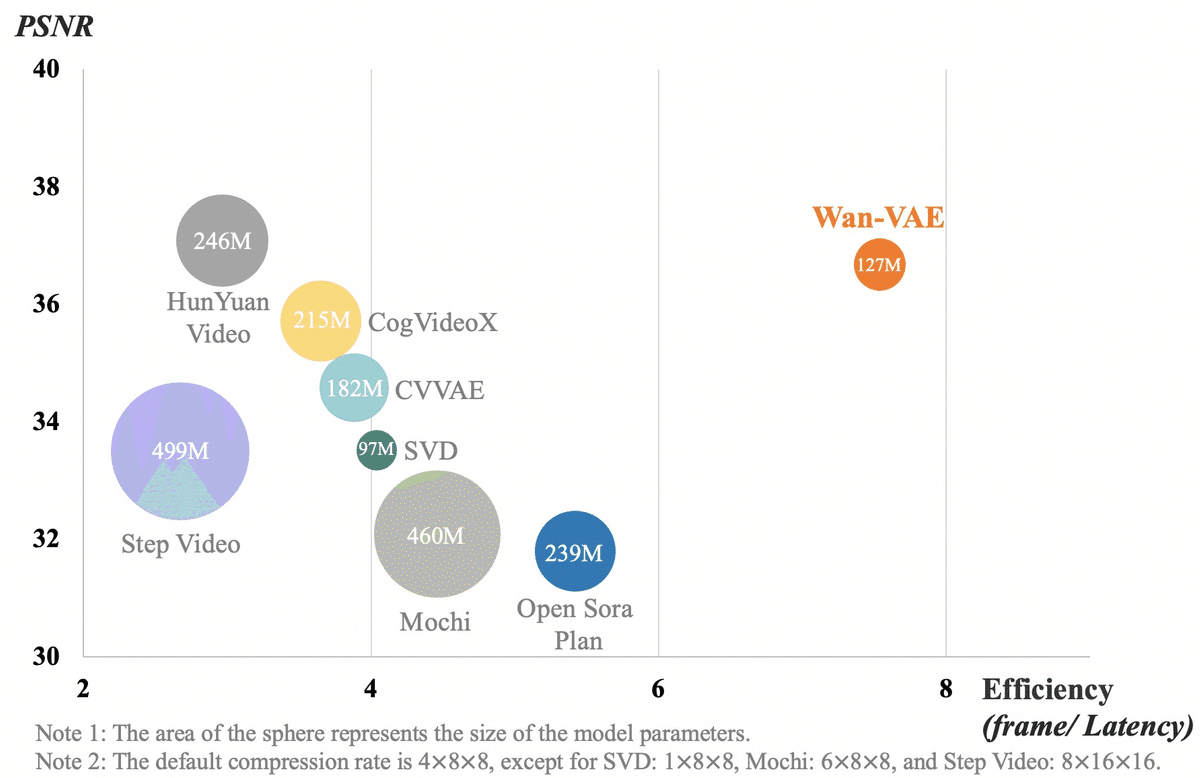
円の大きさはモデルパラメータ、PSNR(Peak Signal to Noise Ratio)ピーク信号対雑音比で画像の場合「雑音が少なければ少ない」(=元の画像との差分が少ない)ほど、PSNRは大きな値を取ります。この場合HunYuanVideoとWan-VAEは同レベルのPSNRでパラメータサイズが倍、VAEの効率としては Stable Video Diffusion (SVD)の倍近い効率であると示されています。
まとめ:Alibabaの動画生成モデル「Wan2.1」のText to Videoの内部動作
本稿では、Alibabaが公開した最先端の動画生成AIモデル「Wan2.1」を、ComfyUIを使ってGoogle Colab環境で動作させる方法と、その内部構造について解説しました。
Wan2.1の特徴:
Video DiT (Diffusion Transformer) モデル:
Stable DiffusionのU-Netよりも高性能。
OpenAIのSoraでも採用されている技術。
T5エンコーダで多言語テキストを処理し、クロスアテンションでモデルに埋め込む。
MLPで時間埋め込みを処理し、変調パラメータを予測。
大規模データセットでの学習:
4段階のデータクリーニングプロセスを経た、高品質で多様なデータを使用。
Wan-VAE:
Wan2.1専用に設計された、動画生成に特化した3D VAE。
時空間圧縮の改善、メモリ使用量の削減、時間的因果関係の保証を実現。
多言語対応T5エンコーダ: 日本語プロンプトも利用可能。
HunyuanLatentVideo形式のLatent画像を使用
Wan2.1は、最先端の技術(Video DiT, 独自のVAE)を採用し、高品質な動画生成を実現する強力なモデルです。ComfyUIとの連携により、シンプルなワークフローで利用できるようになり、ローカルGPUやGoogle Colabなどの環境でも動作するため、多くのユーザーがその可能性を体験できるでしょう。今後の動画生成AIの発展を牽引する存在として、Wan2.1の動向に注目です。

Google Colabでのワークフローはメンバーシップおよび「共有ComfyUI」サブスクリプション宛てに提供します。
このラインより上のエリアが無料で表示されます。
