
Omostで画像生成を細かく制御しよう(2) GPT-4o でCanvasを Stable Diffusion 向けに最適化する

「Omost」は大規模言語モデル(LLM)のコーディング能力を画像生成に変換するオープンソースプロジェクトです。ControlNetやStable Diffusion WebUI Forge、Foocusの開発者として著名なlllyasviel氏が中心に開発しています。
そもそも「Omostって何」という方は前回の記事をご参照ください。
✨️本記事は Nobuyuki Kobayashi @nyaa_toraneko さんにご寄稿いただいた記事をベースに編集部でリライトしております。
Omostが生成するCanvasとは
Canvasは生成される画像に描かれるべき要素やモチーフを定義したオブジェクトです。
その構造は、大きく分けて2つのブロックから構成されています。
1.グローバル描写
まずは、シーン全体のテーマや雰囲気を設定するブロックです。これをグローバル描写と呼びます。グローバル描写では、以下の情報を設定します
description: シーン全体の簡単な説明です。例えば、「魔法の生き物が住む鮮やかなファンタジーの世界」などです。
detailed_descriptions: シーンに関するもう少し詳細な説明をリストで提供します。例えば、「明るくカラフルな環境」、「空気中に漂う神秘的な輝き」などです。
tags: シーンに関連するキーワードを指定します。例えば、「ファンタジー」、「魔法」、「自然」などです。
HTML_web_color_name: シーンの主な色をHTMLカラー名で指定します。例えば、「スカイブルー」などです。
2.ローカル描写
次に、キャンバス上の特定の部分について詳細を設定するブロックです。これをローカル描写と呼びます。ローカル描写では、以下の情報を設定します
location: 描写される部分の位置です。例えば、「中央」などです。
offset: オフセットの有無です。例えば、「オフセットなし」などです。
area: 描写される部分の面積です。例えば、「大きな四角いエリア」などです。
distance_to_viewer: 視聴者からの距離です。例えば、「1.0ユニット」などです。
description: 描写される部分の簡単な説明です。例えば、「流れるようなローブをまとった威厳のある魔法使い」などです。
detailed_descriptions: 描写される部分に関するもう少し詳細な説明をリストで提供します。例えば、「星柄のマントを着ている」、「光る杖を持っている」、「長い白髭」などです。
tags: 描写される部分に関連するキーワードを指定します。例えば、「魔法使い」、「魔法」、「キャラクター」などです。
atmosphere: 描写される部分の雰囲気です。例えば、「神秘的」などです。
style: 描写される部分のスタイルです。例えば、「ファンタジー」などです。
quality_meta: 描写の品質に関するメタデータです。例えば、「高詳細」などです。
HTML_web_color_name: 描写される部分の主な色をHTMLカラー名で指定します。例えば、「紫」などです。
例えば、実際にCanvasを用いてStable Diffusionで生成したあるイラストでは、以下のようにCanvasにローカル描写が指定がされています。

このように、イラスト全体の相対的な位置におおよそどんなモチーフが配置されるか指定することによって、イラスト全体のレイアウトができあがるということです。
ただ生成されたCanvasですが、読みやすく詳細な指定なのはいいのですが、とにかく長い。これをそのまま Stable Diffusion のポジティブプロンプトにコピペして、絵を出すこともできますが、ちょっとこのままでは扱いにくいのも事実です。
そこでCanvasの要素をなるべく残しながら、指定を最適化していきましょう。
筆者の場合、ここからはOpenAI社の GPT-4o上 でMy GPTsを設計し、「Omost Converter」というチャットボットを作りました。
Stable Diffusion向けにCanvasの最適化をChatGPT 4oで行う
ここでは、Canvasの最適化の手順を紹介します。
興味がある方は、自分自身でもOmost Converterを作ってみるといいでしょう。
1. Canvasの記述よりフルプロンプトを作成する
まず、Canvasの情報を元に、グローバル描写と各ローカル描写を収集したフルプロンプトを作成します。以下のようなフォーマットで作成します。
# グローバル描写
"{description} with elements of {detailed_descriptions}. The scene has a {tags} feel, colored primarily in {HTML_web_color_name}."
# 各ローカル描写
"In the {location}, there is a {description}. It is {offset} and occupies {area}. It is {distance_to_viewer} units away from the viewer. Detailed features include {detailed_descriptions}. The atmosphere is {atmosphere}, and the style is {style}, colored in {HTML_web_color_name}."
...
この段階でCanvasの情報は相当圧縮されますので、ChatGPT 4oでしたら、DALL-E 3で絵を生成することも可能ですが、まだまだ無駄が多いようですのでさらに最適化を進めましょう。
2. フルプロンプトを最適化する
続いてフルプロンプトを最適化します。最適化の目的は、プロンプトを短く、わかりやすくすることで、Stable Diffusionが生成する画像の品質を向上させることです。以下のステップに従って、プロンプトを最適化しましょう。
手順 1: 不要な情報を削除
プロンプトから冗長な情報や重複した情報を削除します。例えば、同じ意味の説明が繰り返されている場合、それを一度だけ記述するようにします。
手順 2: 簡潔な言葉を選ぶ
長いフレーズや文を、同じ意味を持つより短い言葉やフレーズに置き換えます。たとえば、「長い白髭を持つ魔法使い」ではなく、「白髭の魔法使い」といった具合です。
手順 3: 主要なキーワードを強調
プロンプトの主要なキーワードやフレーズを強調し、重要でない詳細を省略します。これにより、AIが重要な要素に焦点を合わせやすくなります。
手順 4: 一貫したスタイルとトーンを維持
プロンプト全体で一貫したスタイルとトーンを維持します。これは、読者がプロンプトを理解しやすくし、AIが意図を正確に把握するのに役立ちます。
手順 5: 最適化されたプロンプトの例
ここで、具体的な例を使って、最適化されたプロンプトを作成します。
元のフルプロンプト
# Global Description
"魔法の生き物が住む鮮やかなファンタジーの世界 with elements of 明るくカラフルな環境, 空気中に漂う神秘的な輝き, 幻想的な雰囲気. The scene has a ファンタジー, 魔法, 自然 feel, colored primarily in skyblue."
# Local Descriptions
"In the 中央, there is a 流れるようなローブをまとった威厳のある魔法使い. It is オフセットなし and occupies 大きな四角いエリア. It is 1.0 units away from the viewer. Detailed features include 星柄のマントを着ている, 光る杖を持っている, 長い白髭. The atmosphere is 神秘的, and the style is ファンタジー, colored in purple."
最適化されたプロンプト
# Global Description
"カラフルな魔法の世界, 明るい環境, 空気中に神秘的な輝き, 幻想的な雰囲気. ファンタジー, 魔法, 自然, スカイブルー."
# Local Descriptions
"中央に星柄のマントと光る杖を持つ白髭の魔法使い. オフセットなし, 大きなエリア, 1.0ユニット距離. 神秘的な雰囲気, ファンタジースタイル, 紫色."
手順 6: トークンの数を確認
最適化された各プロンプトが約75トークン以内であることを確認します。これは、AIがプロンプトを効果的に処理できるようにするためです。
最適化されたプロンプトは、元のプロンプトに比べて短く、明確で、重要な情報に焦点を当てています。これにより、Stable Diffusionがより正確で魅力的な画像を生成できるようになります。
またこの段階で、DALL-E 3に最適化されたプロンプトを試しに描かせてみてもよいでしょう。先にOmostで生成した画像と同様のモチーフの画像が生成されていれば成功です。
これらの最適化を実行することで、生成したいイラストのプロンプトは以下のようになりました。
A curious yet anxious girl with white hair floats in a dark, surreal alternate dimension, reaching out to a glowing orb through an open door. She is dressed as a bunny girl, with her white hair flowing around her, adding motion and wonder. Her expression mixes curiosity and anxiety, reflecting uncertainty about the future. The central focus is on her dynamic posture. The dimension features a tilted horizon and floating doors, creating a chaotic and disordered feel. The open door, made of otherworldly material, emits light that contrasts sharply with the dark space, enhancing the mystery. The glowing orb, symbolizing a wonderful future, emits radiant light, creating hope and anticipation. The scene is designed in a 16:9 aspect ratio, with detailed textures and light effects. The atmosphere is a mix of curiosity, anxiety, wonder, and trepidation, rendered in high-quality with a focus on detailed expressions and flowing hair.
好奇心旺盛でありながら不安げな白い髪の少女が、暗く超現実的な異次元に浮かび、開いたドアから光り輝くオーブに手を伸ばしています。彼女はバニーガールの格好をしており、白い髪が周りに流れ、動きと驚きを加えています。彼女の表情は好奇心と不安が入り混じり、未来への不安を反映しています。中心は彼女のダイナミックな姿勢。次元は、傾いた地平線と浮遊するドアが特徴で、混沌とした無秩序な雰囲気を醸し出しています。別世界のような素材でできた開いた扉は光を放ち、暗い空間とのコントラストを際立たせ、神秘性を高めています。素晴らしい未来を象徴する光り輝くオーブは、希望と期待を生み出します。このシーンは16:9のアスペクト比でデザインされ、詳細なテクスチャと光のエフェクトが施されています。好奇心、不安、驚き、怯えが入り混じった雰囲気を、細かい表情や流れる髪を中心にハイクオリティで表現しています。
このプロンプトをDALL-E 3で出力させてやると、以下のようになりました。なかなかいいですね。

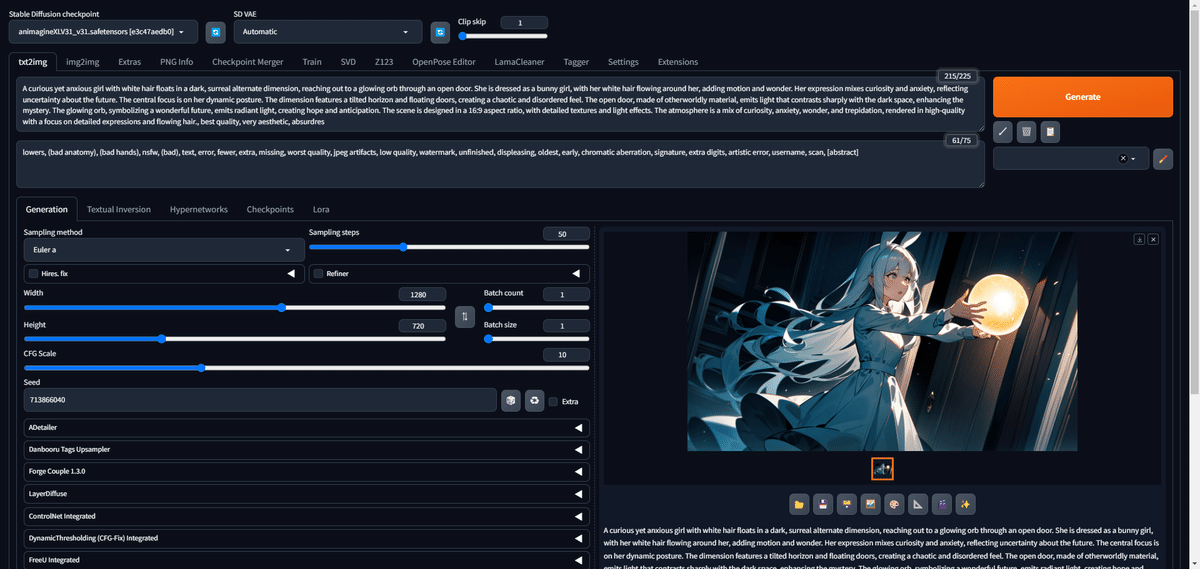
スタイルは違いますが、Omostで生成した画像と要素も一致しています。
加えて今回は、空間に浮いているドアもバッチリです。ただドアを沢山画面内に配置すると、当然キャラも小さくなってしまうのが難しいところですね。こういうところは検討材料にしておきましょう。
Stable Diffusionで最適化されたプロンプトを実行する
最適化されたプロンプトからどんな絵が出るか、DALL-E 3で確認できたので、次はStable Diffusionでテストしてみましょう。
Stable Diffusionでは、様々なCheckpoint(モデル)が選べますが、どちらかと言えば文章で構成されているプロンプトから画像を生成するには、SDXL系のモデルを使うことをお薦めします。今回は、AnimagineXL v3.1を使用しました。
まずポジティブプロンプトに最適化されたプロンプトをペーストし、ネガティブプロンプトには、皆さんがよく使うようなものを入れて、生成しましょう。
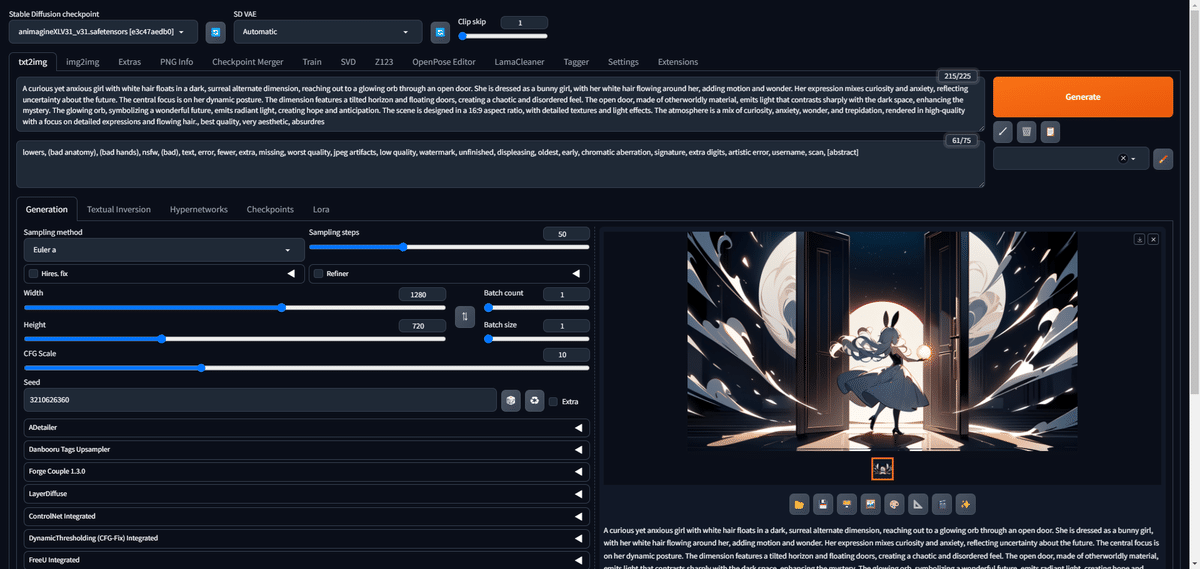
今回は1回目から、かなり近いテーマの絵が生成されました。これでOmostのプロンプトがStable Diffusionでも使えることがわかったと思います。
何回か試してみると、キャラが大きく表示されるシードが見つかりました。
これでシード次第で、キャラを大きく表現できることがわかります。
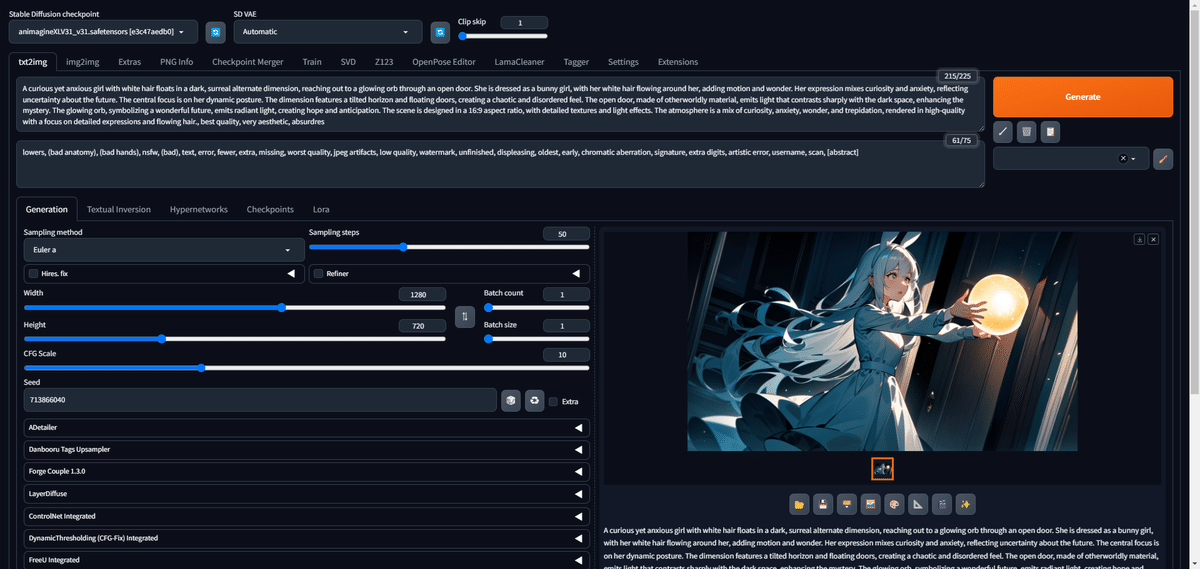
ここからは、プロンプトに自由に魔改造を施していきましょう。
ここから先は
Amazonギフトカード5,000円分が当たる
最後まで読んでいただきありがとうございました 【特報】「ComfyUIマスタープラン」購読の皆様向けに無償テスターコードを配布します。興味のある方はぜひどうぞ!
