
イーロン・マスク xAIによる「Grok-1」リリース!明らかに重すぎる重みが重い

イーロン・マスク氏が2024年7月に立ち上げたAI企業「xAI」が3月17日、「Grok-1」のベースモデルの重み(weights)とアーキテクチャをリリースしました。GitHubにて、Apache 2ライセンスで配布されています。
当初、LLMだと思われていたこの「Grok-1」ですが、OpenAIの ChatGPT のようなAPIサービスや、Mistral「Mixtrial-7B」, Stability AI「Japanese Stable LM-7B」, CyberAgent「OpenCALM-7B」のようなLLMとも異なるようです。
我々は314B (3,140億)のパラメータを持つMixture-of-Expertsモデル、Grok-1の重みとアーキテクチャを公開する。
私たちの大規模言語モデルであるGrok-1のベースモデルの重みとネットワークアーキテクチャを公開します。Grok-1は3,140億パラメータのMixture-of-Expertsモデルで、xAIによってゼロからトレーニングされました。
これは、2023年10月に終了したGrok-1プレトレーニングフェーズの生のベースモデルチェックポイントです。つまり、対話のような特定のアプリケーション向けに微調整されたモデルではない。
我々は、重みとアーキテクチャをApache 2.0ライセンスの下で公開しています。
モデルの使用を開始するには、github.com/xai-org/grok の指示に従ってください。
モデルの詳細:
・大量のテキストデータで訓練されたベースモデルで、特定のタスクのために微調整されていません。
・314BパラメータのMixture-of-Expertsモデルで、重みの25%が与えられたトークンでアクティブになります。
・2023年10月にJAXとRustの上にカスタムトレーニングスタックを使用してxAIによってゼロから訓練されました。
カバー画像は、Grokによって提案

次のプロンプトに基づいてMidjourneyを使用して生成されました:透明なノードと光り輝く接続を持つニューラルネットワークの3Dイラストで、接続線の異なる太さと色として変化する重みを示しています。
Mixture of expertsモデルについては後ほど解説します。
以下、しらいはかせによる解説でお送りします。
まずモデルダウンロードから重い
weightはtorrent使って落とすのか…懐かしい感じするけど分散ネットワークの意義を感じる
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) March 18, 2024
GitHub - xai-org/grok-1: Grok open release https://t.co/KFFgoU5jah
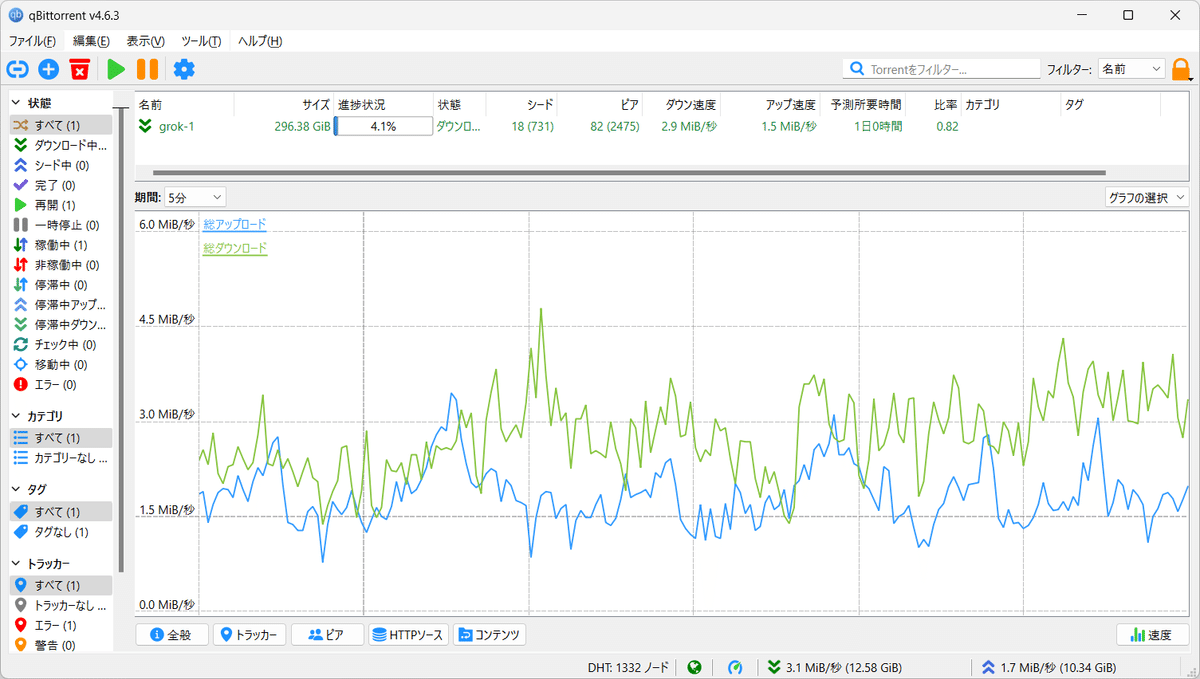
ダウンロードには分散ファイルシステムの torrentを使います。
296GBあります。

ダウンロードが終わる気配がありません。
現時点で、だいたい4日~1週間ぐらいかかりそうです。
またモデルのサイズが大きい(314Bパラメータ)ため、サンプルコードでモデルをテストするには、十分なGPUメモリを持つマシンが必要です。もし、このファイルサイズそのままをGPUにロードするのであれば296GB以上のVRAM環境が必要です。
つまりダウンロードに成功したとしてもtorrentネットワークの分散ファイルシステムに協力者として放置するぐらいしかできることがなさそうです。
OpenAIの最初のインターンであり、スタンフォード大学博士、現NVIDIAリサーチマネージャー兼エンボディドAI(GEARグループ)リーダー。エージェント、ロボティクス、ゲームのための基礎モデルを作成する ジム・ファン @DrJimFan のツイートが興味深いです。
今まで見たことが無いサイズのオープンLLM、世界トップクラスのチームが育成、magnetリンクで投下された。Apache 2.0だ。
@grok、オープンにされた気分はどんなものだろう。
3140億、mixture of export(8アクティブのうち2つが出力)。アクティブパラメータのみ(86B)でも最大のLlamaより多い。ベンチマークの結果を見るのが待ち遠しい。
The largest ever open LLM, trained by a world class team, dropped by a magnet link. Apache 2.0. I wonder what it feels like to be out-opened by @grok.
— Jim Fan (@DrJimFan) March 17, 2024
314B, mixture of expert (2 out of 8 active). Even the active parameters only (86B) is more than the biggest Llama. Can’t wait… pic.twitter.com/tNoJbIzTOR
ソースコードを読んでみる
torrentでのダウンロードの方法については、こちらを参考にしつつ、
ダウンロードに数日掛かりそうなのと、一般的なPC環境などで利用できるモデルではなさそうなので、以下はリポジトリからの調査になります。
README 和訳
このリポジトリには、Grok-1 open-weightsモデルをロードして実行するためのJAXサンプルコードが含まれています。
checkpointをダウンロードし、ckpt-0 ディレクトリを checkpoint に置き、テストコードを実行してください。
pip install -r requirements.txt
python run.pyスクリプトは checkpoint をロードし、テスト入力にモデルからサンプルをロードします。
モデルのサイズが大きい(314Bパラメータ)ため、サンプルコードでモデルをテストするには、十分なGPUメモリを持つマシンが必要です。このリポジトリにおける MoE レイヤーの実装は効率的ではありません。これは、モデルの正しさを検証するためのカスタムカーネルの必要性を避けるために実装しています。
torrentクライアントと、このマグネットリンクを使ってウェイトをダウンロードできます。
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounceライセンス:このリリースのコードと関連するGrok-1の重みは、Apache 2.0ライセンスの下でライセンスされています。このライセンスは、このリポジトリのソースファイルとGrok-1のモデル重みにのみ適用されます。
Mixture of experts (MoE)とは
日本語での原著論文解説を if001 さんがZennで寄稿されていますので引用させていただきます。
Mixture of experts (MoE)とは特定のタスクに特化したexpertsを複数用意し、入力に対してexpertを切り替えることで性能を上げる手法。expertを選択するgate部分とexpert部分からなる。decoder型のtransformerの場合、Mixture of expertsはattention層のあとのFFNに対して適応される。
https://zenn.dev/if001/articles/40917524959913
もともとの論文ではスパースなMoEについてですが、if001さんのZenn記事ではスパースではない実装についてもコードとともに解説されています。
https://arxiv.org/abs/2101.03961
TransformerのFFN (フィードフォーワードネットワーク)についてはニツオさんのZennが詳しいです。
▼AI界を席巻する「Transformer」をゆっくり解説(5日目) ~Model Architecture編 3~|ニツオ
https://zenn.dev/attentionplease/articles/1a01887b783494
GPTやStable Diffusionの内部で使われている「Transformer」の原著論文「Attention is all you need」で解説されているアーキテクチャー内での青い部分が「Feed Forward」です。
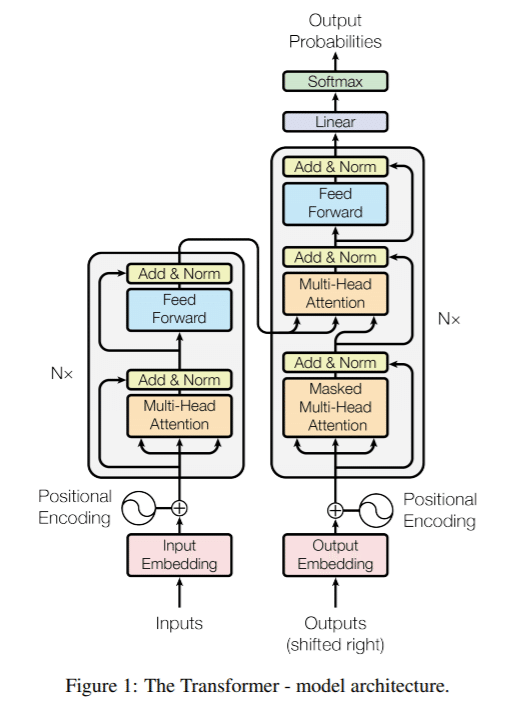
右側のデコーダーの線形変換の部分で、灰色の部分は6回繰り返しになっています。アテンション・サブレイヤーに加え、エンコーダーとデコーダーの各レイヤーには全連結のフィード・フォワード・ネットワークが含まれており、各ポジションに別々に同じように適用されます。これは2つの線形変換とその間のReLU活性化で構成されています。通常は、元の画像や文章をベクトル変換して、1つのデータとしてまとめて行列として扱うのですが、そのサイズや次元数を減らすためにフィルターを通して、サイズや次元数を減らします。これは畳み込み(CNN: convolutional neural network)を使います。線形変換はそのフィルターサイズが1x1カーネルで畳み込みをした場合と同じとみなせます。
MoEについてHuggingFaceの解説
MoEとは
高密度モデルと比較して、事前トレーニングがはるかに高速
同じ数のパラメータを持つモデルと比較して推論が高速になります
すべてのエキスパートがメモリにロードされるため、高 VRAMが必要
微調整では多くの課題に直面しているが、MoE の命令調整に関する最近の研究は有望である
MoE では、Transformerモデルのすべての FFN 層を、ゲートネットワークと一定数のエキスパート(専門家)で構成される MoE 層に置き換えます。

DrJimFanの「mixture of export (2 out of 8 active)」とは8つのエキスパートのうち2つが出力しているよ、という意味と捉えました。
Grok-1のリポジトリには
このリポジトリにおける MoE レイヤーの実装は効率的ではありません。これは、モデルの正しさを検証するためのカスタムカーネルの必要性を避けるために実装しています。
たしかに、モデルの正しさに対して、チートする目的があれば、MoEをスパース(まばら)を最適化して、カスタムカーネルを用意することでサイズを減らし、特定目的に特化させることはできると考えます。おそらく今後、このGrok-1を削る形で様々なモデル(例えばチャットボットや文書検索、翻訳タスクなど)が出てくるのではないでしょうか。
ただし現状は、このファイルをダウンロードして、Transformerにかけることができる演算基盤を持っている方々に限られます。
イーロン・マスクからの挑戦状、というところでしょうか。
dm-haiku
内部での必要なライブラリについても目を向けていきます
[requirements.txt]
dm_haiku==0.0.12
jax[cuda12_pip]==0.4.25 -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
numpy==1.26.4
sentencepiece==0.2.0
Google Deepmindによる「dm-haiku」というJAXベースのニューラルネットワークライブラリを使っています。
JAXベースのニューラルネットワークライブラリです。フレームワークではありません。そしてこれは Google内のDeepMindとGoogle Brainの"仁義なき戦い"でもあります。
2023年7月現在、Google DeepMindは新しいプロジェクトにHaikuの代わりにFlaxを採用することを推奨しています。FlaxはもともとGoogle Brainによって開発され、現在はGoogle DeepMindによって開発されているニューラルネットワークライブラリです。FlaxはHaikuで利用可能な機能のスーパーセットを持っており、より大規模で活発な開発チームと、Alphabet以外のユーザーとのより多くの採用があります。Flaxは、より広範なドキュメント、サンプル、そしてエンドツーエンドのサンプルを作成する活発なコミュニティを持っています。Haikuは引き続きベストエフォートでサポートされますが、プロジェクトはメンテナンスモードに入り、バグフィックスとJAXの新しいリリースとの互換性に開発の努力が注がれます。HaikuがPythonとJAXの新しいバージョンで動作し続けるように新しいリリースが行われますが、新しい機能を追加する(またはPRを受け付ける)ことはありません。私たちはGoogle DeepMind社内でHaikuをかなり使用しており、現在このモードでHaikuを無期限にサポートする予定です。
JAX/Flaxでの日本語でLLMを作る実装について、fukugawaさんによるGCPでの解説がありましたので引用させていただきます。
JAX/Flaxで作るTransformer言語モデル ❷ cc100編
https://zenn.dev/fukugawa/articles/6f27513f5dce1c
GCP上でテンソルプロセッサを使って0.1BのLLMを作ろうとしています。だいたいこれの3万倍ぐらいの演算基盤が必要になりそうですね。
(計算が間違ってたらすみません)
xAIは「宇宙を理解する」企業
せっかくなのでxAIについても調査してみました。
「Our Mission: Understand the Universe」(宇宙を理解する)とあります。
xAIは、人間の科学的発見を加速させる人工知能の構築に取り組む新しい会社です。私たちは、宇宙についての理解を深めることを使命としています。
xAIの技術チーム
xAIのチームは、 Tesla と SpaceX のCEOであるイーロン・マスクが率いています。過去に、DeepMind, OpenAI, Google Research, Microsoft Research, Tesla, University of Toronto. Adam optimizer, 特に Batch Normalization, Layer Normalization, adversarial examples といった発見に貢献しています。
さらにこの分野で最大のブレークスルーのいくつか Transformer-XL, Autoformalization, Memorizing Transformer, Batch Size Scaling, μTransfer, SimCLR といった革新的な技術や分析を導入してきした。AlphaStar, AlphaCode, Inception, Minerva, GPT-3.5, GPT-4 に取り組み、開発をリードしてきました。
・xAI社の社内AIチューターは、技術チームと協力して、当社のモデルをトレーニングおよび評価するための高品質なデータを作成し、管理しています。当社のチューターは幅広い分野の専門家であり、専門的なライティングスキルを備えています。
・xAI社のチームは、現在 Center for AI Safetyのディレクターを務めるダン・ヘンドリックスがアドバイザーを務めています。
パートナーシップ
私たちはX Corpと密接に提携し、Xアプリの5億人以上のユーザーに私たちの技術を提供しています。
開発者 イゴール・バブーシキン
grok-1のリポジトリでメインコントリビューターである イゴール・バブーシキン(Igor Babuschkin)についても注目していきます。
Google DeepMind、OpenAIを経験、スタークラフトIIの研究者でもあります
DIY Automated Papers:論文を自動で書くPythonスクリプトを中心としたGitHubリポジトリです。9年前に書かれています。
完全に再現可能な研究論文の例 これはGithub、Python、jinja2、travisを使った完全に再現可能な研究論文の例です。git pushのたびに、travisはこのリポジトリをチェックアウトし、run.pyスクリプトを実行します。
このスクリプトで定義された変数は、jinja2のテンプレートpaper.tex(研究論文のLaTeXコードを含み、スクリプトから入力されるべき値のテンプレートフィールドがある)で利用できるようになります。Travisはテンプレートを埋めてpaper.texをPDFファイルにコンパイルし、このリポジトリのgh-pagesブランチにアップロードします。(レンダリングされたウェブページは https://ibab.github.io/fully-reproducible を参照) つまり、分析の各段階は、対応する PDF ファイルと git コミットとして表されます。
すべての研究者が論文の最終版を表すコミットに合意したら、git tag を使ってそれを正式な最終版としてマークすることができます。論文が査読段階に入ったら、今度は git tag を使って修正箇所に印をつけることができます。
このように、研究者の共同作業は非常に簡単。例えば、Githubのプルリクエスト機能を利用すれば、グループ内の他の研究者が変更を受け入れる前に、何が変更され、論文の結果がどうなったかを確認することができます。こうすることで、ミスを早い段階で発見できる可能性が高くなるだけでなく、グループの有効性も高まる。
また、部外者(機械学習の専門家、ソフトウェアエンジニア、素人、...)が簡単に研究プロジェクトを発見し、貢献することも可能になる。完全に再現可能な研究論文は、初日から公開されるのが理想的だ!
ここで概説したアイデアは、分析に必要な計算量がそれほど大きくなければ(トラビスノード1台で実行可能)、すでに実現可能な非常に基本的なアプローチである。工夫次第では、AWSのようなクラウド上でノードのクラスタを自動的に起動することも可能だろう。これによって、任意に難しい計算も可能になるはずであり、外部の人間が自分のノードを立ち上げて分析を検証することも容易になるはずである。
https://babushk.in/research.html
最近の論文ではこのような研究も発表されています。
"Formal Mathematics Statement Curriculum Learning" (2022)
(形式化数学記述カリキュラム学習)
Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, Ilya Sutskever
https://arxiv.org/abs/2202.01344
形式化数学、つまり数学の証明などの問題をコンピュータに記述させる課題です。高校のオリンピックから抽出した複数の難問を自動的に解くという、最先端の成果を発表しています。
ダウンロード、終わりそうにないですね!
以上、速報でした。
Grokについての技術情報はこちら
https://x.ai/blog/grok
Grokのような巨大なモデルを必要としないチャットボット開発などはAICU AIDX Labにご相談ください!
最後まで読んでいただきありがとうございました 【特報】「ComfyUIマスタープラン」購読の皆様向けに無償テスターコードを配布します。興味のある方はぜひどうぞ!
