
東工大と産総研、英語の言語理解や対話で高い能力を持つ大規模言語モデル「Swallow」を公開 #SwallowLLM

東京工業大学(以下、東工大) 情報理工学院 情報工学系の岡崎直観教授と横田理央教授らの研究チームと国立研究開発法人 産業技術総合研究所(以下、産総研)は、日本語能力に優れた生成AIの基盤である大規模言語モデル「Swallow」を公開しました。本モデルは現在公開されている日本語に対応した大規模言語モデルとしては最大規模であり、オープンで商用利用が可能であるため、ビジネスに安心して用いることができそうです。
AICU mediaでは早速サンプルを公開しました
以下は初期リリースに基づく記録となります
今回公開したLLMは、英語の言語理解や対話で高い能力を持つ大規模言語モデル・米Meta社「Llama 2」の日本語能力を拡張することで「Swallow」を構築。拡張前の Llama2 のの高い言語処理能力を維持しながら日本語能力を強化するため、言語モデルに日本語の文字や単語などの語彙を追加したうえで、新たに開発した日本語データを用いてモデルの構築を継続的に行う継続事前学習を行った。今回、パラメータ数が70億パラメータ「7B」、130億パラメータ「13B」、700億パラメータ「70B」であるモデルを公開した。
📢 大規模言語モデル「Swallow」をHugging Face上で公開しました。東京工業大学情報理工学院の岡崎研究室と横田研究室、産業技術総合研究所の研究チームでLlama 2 7B, 13B, 70Bの日本語能力を引き上げました。13Bと70BのオープンなLLMの中で日本語の最高性能を達成しました。 https://t.co/GcVppvdovF
— Naoaki Okazaki (@chokkanorg) December 19, 2023
大規模言語モデル「Swallow」をHugging Face上で公開しました。東京工業大学情報理工学院の岡崎研究室と横田研究室、産業技術総合研究所の研究チームでLlama 2 7B, 13B, 70Bの日本語能力を引き上げました。13Bと70BのオープンなLLMの中で日本語の最高性能を達成しました。
大学からもプレスリリースが発信されています
■日本語に強い大規模言語モデル「Swallow」を公開 英語が得意な大規模言語モデルに日本語を教える | 東工大ニュース | 東京工業大学
tokyotech-llm.github.io
プロジェクトのWebサイトも準備されています


tokyotech-llm.github.io/swallow-llama
Llama 2の日本語能力を強化した大規模言語モデル (7B, 13B, 70B) です。モデルのパラメータ(重み)が公開されていますので、LLAMA 2 Community Licenseに従う限り、研究や商業利用など自由に利用できます。
Zennに横田研究室・藤井一喜さんの技術解説もあります
https://zenn.dev/tokyotech_lm/articles/d6cb3a8fdfc907
すごく知見が集まっているので是非読んでほしい!

以下公式サイトからの引用ですが、しっかり論文スタイル、かつ読みやすい日本語解説が書かれています!
概要
大規模言語モデルSwallowは東京工業大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チームで開発された大規模言語モデルです。英語の言語理解や対話で高い能力を持つ大規模言語モデルLlama 2 7B, 13B, 70Bの日本語能力を拡張するため、研究チームは言語モデルに日本語の文字や単語などの語彙を追加したうえで、新たに開発した日本語データを用いてモデルの構築を継続的に行う継続事前学習を行いました。研究チームで実施した性能評価では、2023年12月現在オープンな大規模言語モデルの中で、日本語に関して最高性能を達成しました。今回公開したモデルは7B, 13B, 70Bの継続事前学習モデル(base)と、それぞれに指示チューニングを施した言語モデル(instruct)の計6種類で、Hugging Faceからモデルをダウンロードできます。
Swallow 7B base: https://huggingface.co/tokyotech-llm/Swallow-7b-hf
Swallow 7B instruct: https://huggingface.co/tokyotech-llm/Swallow-7b-instruct-hf
Swallow 13B base: https://huggingface.co/tokyotech-llm/Swallow-13b-hf
Swallow 13B instruct: https://huggingface.co/tokyotech-llm/Swallow-13b-instruct-hf
Swallow 70B base: https://huggingface.co/tokyotech-llm/Swallow-70b-hf
Swallow 70B instruct: https://huggingface.co/tokyotech-llm/Swallow-70b-instruct-hf
SwallowのライセンスはLlama 2のLLAMA 2 Community Licenseを継承しています。このライセンスに従う限りにおいては、研究および商業目的での利用が可能です。
性能
Llama 2に継続事前学習を行ったモデルで日本語の性能を比較しました。ただし、13Bのモデルは比較対象が無いため、日本語でフルスクラッチで学習したモデルとの比較を含めました。この結果から、Swallowは継続事前学習で日本語の能力を着実に伸ばしたこと、フルスクラッチで事前学習したモデルよりも高い性能を持つことが分かります。また、Swallowの継続事前学習にあたり、日本語の語彙を追加していますが、他のモデルでは日本語の語彙追加で性能が落ちるという報告があったため、比較対象のモデルは語彙追加を行っていないものを採用しています。我々が行った比較実験においては、語彙追加の有無による評価スコアの差は僅かで、むしろ系列長が短くなることのメリットの方が大きいことから、語彙追加ありのモデルを採用しています。


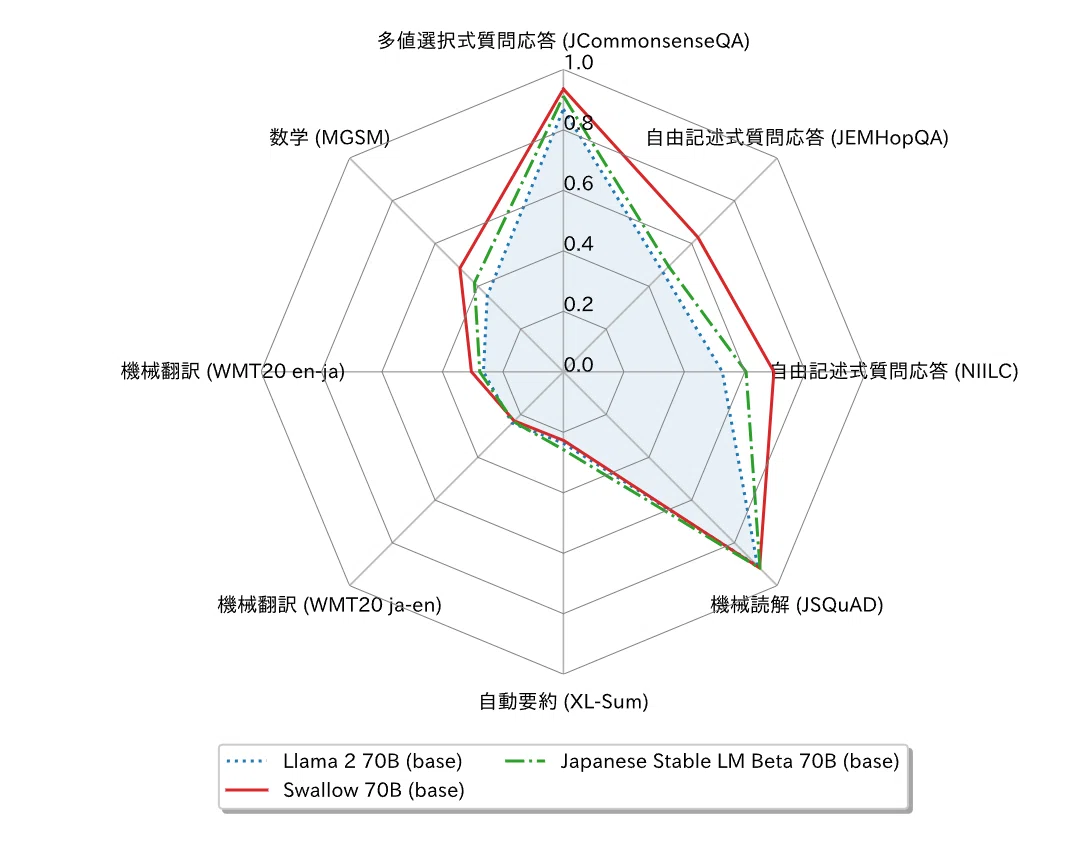

続いて、英語の性能を示します。Swallowの英語の性能は元のモデルよりも若干低下しています。Swallowでは継続事前学習に日本語と英語のテキストを混ぜたデータを利用していますが、他のモデルでよく用いられる混合比1:1ではなく、日本語を重視した9:1を採用しています。これが英語の性能低下に繋がったのかどうかは、今後の追加実験で明らかにしていく予定です。




なお、ベンチマークのスコアを異なるデータセット間で比較することができないことに注意してください。例えば、70Bモデルの日本語の評価結果において、機械翻訳のスコアよりも数学のスコアの方が高いですが、これはSwallowが翻訳よりも数学が得意であることを示唆しているのではありません(問題の難易度や採点基準が全く異なる試験の結果を比較しているようなものです)。同様の理由により、日本語タスクのスコアの平均値よりも、英語タスクのスコアの平均値の方が高いからといって、Swallowは英語の方が得意、と結論付けることもできません。ベンチマークのデータセットによって評価尺度や難易度が異なるため、このレーダーチャートの形状だけからタスクの得意・不得意について議論することは不適切です。
最後に、研究チームで実施した日本語の評価ベンチマークでの比較実験結果を示します。この評価実験ではパラメータの重みが公開されているオープンなモデルの性能を測定しました。
モデル日本語平均JComQAJEMHopQANIILCJSQuADXL-Sum日英翻訳英日翻訳MGSM

パラメータ数が7Bである他のモデルと比較すると、Swallow 7Bはフルスクラッチで学習されたモデルやLlama 2ベースの他のモデルを上回る性能を示しました。唯一、Japanese Stable LM Gamma 7B(Mistral 7B v0.1からの継続事前学習)を下回る結果となりましたが、これはベースとしているMistral 7B v0.1の性能が高いことが理由として考えられます。今後、Mistral v0.1をベースにした継続事前学習にも取り組みたいと考えています。
パラメータ数が13Bや70Bである他のモデルとの比較では、Swallowが最高性能を達成しています(2023年12月時点)。特に、13Bにおいてフルスクラッチで学習した他のモデルとの性能差が顕著に現れています。これらの実験結果から、性能の高い大規模言語モデルからの継続事前学習が効率的・効果的であることが示唆されますが、今後は大規模言語モデルのフルスクラッチでの学習において性能を高めるための方策や知見も探求していきたいと考えています。
評価ベンチマーク
日本語の評価ベンチマークとしてllm-jp-eval(v1.0.0)およびJP Language Model Evaluation Harness(commit #9b42d41)を用いました。内訳は以下の通りです。
多値選択式質問応答 (JCommonsenseQA [Kurihara+, 2022])
自由記述式質問応答 (JEMHopQA [石井+, 2023])
自由記述式質問応答 (NIILC [関根, 2003])
機械読解 (JSQuAD [Kurihara+, 2022])
自動要約 (XL-Sum [Hasan+, 2021])
機械翻訳 (WMT2020 ja-en [Barrault+, 2020])
機械翻訳 (WMT2020 en-ja [Barrault+, 2020])
数学 (MGSM [Shi+, 2023])
なお、大規模言語モデルの評価ベンチマークとしてよく用いられる自然言語推論(NLI)については、言語モデルがラベルを偏って予測する傾向があり、そのラベル予測の偏りが正解と偶然一致するとスコアが高くなるため、(特に7Bや13Bで)評価結果が安定しませんでした。そのため、今回は評価ベンチマークから除外しています。
英語の評価ベンチマークとしてLanguage Model Evaluation Harness(v.0.3.0)を用いました。内訳は以下の通りです。
多値選択式質問応答 (OpenBookQA [Mihaylov+, 2018])
自由記述式質問応答 (TriviaQA [Joshi+, 2017])
機械読解 (SQuAD 2.0 [Rajpurkar+, 2018])
常識推論 (XWINO [Tikhonov & Ryabinin, 2021])
自然言語推論 (HellaSwag [Zellers+, 2019])
数学 (GSM8k [Cobbe+, 2021])
構築方法
継続事前学習によるLlama2の日本語の能力の大幅な改善
米Meta AI社が開発したLlama 2シリーズは、オープンかつ高性能な大規模言語モデルとして世界中から支持を集めています。また、日本語も含めて、複数の言語からなるデータで学習されているため、Llama 2は日本語にも対応しています。ところが、Llama 2の事前学習データの約90%は英語が占めており、日本語の割合は全体の約0.10%に留まっています。そのため、Llama 2は英語で高い性能を示すにも関わらず、日本語の読み書きは苦手という弱点がありました。
そこで、研究チームではLlama 2の7B, 13B, 70Bのモデルをベースに、大規模な日本語ウェブコーパスと英語のコーパスを9:1で混ぜたデータで継続事前学習を行い、元々の言語モデルの能力を活かしながら日本語能力の改善を目指しました。その結果、我々が採用した日本語に関するベンチマークデータにおいて、7B, 13B, 70Bの全てのモデルはベースモデルよりも高い性能を示しました。また、日本語コーパスのみで事前学習された同規模の日本語大規模言語モデルよりも高い性能を示すことから、継続事前学習の有効性が明らかになりました。
語彙拡張による大規模言語モデルの学習・推論効率の改善
Llama 2では、バイト対符号化(BPE; Byte-Pair Encoding)に基づいてテキストがトークン(token)に区切られています。ところが、Llama 2は英語を重視した多言語のモデルとして学習されているため、日本語の主要な単語や文字が語彙に含まれず、テキストが不自然な単位に区切られることがあります。例えば、「吾輩は猫である」という7文字のテキストは、<0xE5><0x90><0xBE><0xE8><0xBC><0xA9>は<0xE7><0x8C><0xAB>であるという、人間には理解しにくい13トークンに区切られます。これは、「吾」「輩」「猫」という漢字が語彙に収録されていないためで、バイトフォールバック(byte-fallback)によりUTF-8文字コードのバイト単位でこれらの漢字が表現されるからです。
日本語の語彙が不足している言語モデルは、日本語を不自然な単位で取り扱うことに加え、テキストをより多くのトークンで表現してしまうため、学習や生成の効率が低下します。大規模言語モデルの学習に必要な計算予算はトークン数に比例するので、逆に計算予算が一定である条件下では、テキストを少ないトークンで表現する方がより多くの情報を学習に詰め込めます。また、大規模言語モデルがテキストを生成するのに要する時間はトークン数に比例するため、同じテキストを生成するのであれば、より少ない数のトークンで表現できる方が短時間で結果を出力できます。さらに、大規模言語モデルの入力や出力には、一度に扱えるトークン長の上限があります。入力をより少ないトークンで表現できる方が、タスクの指示や解き方(few-shot事例)を多く詰め込めるので、下流タスクでの性能向上も期待できます。研究チームはLlama 2のトークナイザに16,000件の日本語のトークンを追加することで、日本語テキストのトークン長を56.2%に削減しました。
大規模な日本語のウェブコーパスの開発
大規模言語モデルの学習には膨大な言語データが必要です。その中でも、ウェブページを収集し、テキスト化したデータは、大規模言語モデルの構築の要です。従来、オープンな日本語大規模言語モデルの学習には、CC-100、mC4、OSCARなど既存のデータセットの日本語部分が用いられてきました。ところが、これらのデータセットでは、ウェブページのHTMLをテキスト化する際のノイズが混入していることや、最新の情報や知識を収録していないという問題がありました。また、これらは多言語のデータセットとして構築されているため、日本語に特化してデータの品質を高めるような工夫は取り入れられていません。
そこで、研究チームではCommon Crawl(用語8)から配布されているアーカイブ(2020年から2023年にかけて収集された21スナップショット分、約634億ページ)から日本語のテキストを独自に抽出・精錬し、約3,121億文字(約1.73億ページ)からなる日本語ウェブコーパスを構築しました。この規模は、CC-100 (約258億文字)、mC4(約2,397億文字)、OSCAR 23.10(約740億文字)を抜き、日本語の言語モデルの学習コーパスの中で、商用利用が可能なものとしては最大となります。
その他
Swallowの構築方法や実験結果については、準備が整い次第、随時情報を公開していきます。また、言語処理学会第30回年次大会(NLP2024)でも報告予定です。
付記
Swallowの研究開発は、産総研が構築・運用するAI橋渡しクラウド(ABCI: AI Bridging Cloud Infrastructure)の「大規模言語モデル構築支援プログラム」、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の「次世代人工知能・ロボットの中核となるインテグレート技術開発」プロジェクト (JPNP18002) の「熟練者観点に基づき、設計リスク評価業務における判断支援を行う人工知能適用技術の開発」、その他の支援によって実施されました。なお、本成果の一部は、大学共同利用機関法人情報・システム研究機構国立情報学研究所、産総研、東工大、NIIが主催する勉強会LLM-jp(NII、東北大学、東京大学、早稲田大学などが参加するLLM研究開発チーム)が2023年9月に共同で提案して採択された、産総研ABCIの一定部分(Aノードと呼ばれる高性能な計算ノード)を最大60日間占有利用する機会を提供する「大規模基盤モデル構築支援プログラム」によるものです。また、学習した大規模言語モデルの評価実験では、LLM-jp (LLM勉強会)で開発されているデータや知見を活用しました。
huggingface.co/tokyotech-llm

AICU media 編集部より
オープンに公開されている meta社+Microsoft社「Llama2」と Stability AI社の 「Japanese Stable LM Gamma 7B」を使った日本語:英語が9:1のモデルを提案するというアプローチは大変興味深いと考えます。性能面や評価方法についても公開されており、様々な用途での評価や応用がし易い状態になっていると考えます。また Stability AI 社の評価リポジトリ「JP Language Model Evaluation Harness」を使いオープンな評価を行いつつ、Mistral系がランキング上位で残った点も興味深く、今後の日本語LLMの発展や研鑽が期待できるアプローチです。
まずは関係者の皆様に「リリースおめでとうございます」と「お疲れ様でした」をお伝えしたいです!
Google Colab Pro で動くソースコードはこちらに置いておきます!
https://github.com/aicuai/GenAI-Steam/commit/a32aea014c7eddebf141228da9f6a3b1d3396ec1
(AICU・しらいはかせ)
最後まで読んでいただきありがとうございました 【特報】「ComfyUIマスタープラン」購読の皆様向けに無償テスターコードを配布します。興味のある方はぜひどうぞ!
