
Stable Video Diffusion 1.1 "Image-to-Video"をGoogle Colabで試す!

Stability AI社より 最新の動画生成モデル「Stable Video Diffusion 1.1 Image-to-Video」がリリースされました。

Stable Video Diffusion (SVD) 1.1 Image-to-Video は、静止画像を条件フレームとして取り込み、そこから動画を生成する拡散モデルです。
前回の初期リリースについて、AICU mediaでは Google Colabで動作するサンプルと動画を公開しました。
以下、公式HuggingFaceのモデルカードから紹介します
モデルの説明
(SVD 1.1) Image-to-Videoは、画像の条件付けから短いビデオクリップを生成するように学習された潜在拡散モデルです。
このモデルは、SVD Image-to-Video [25 frames]から微調整された、同じサイズのコンテキストフレームを与えられた解像度1024x576の25フレームを生成するように訓練されました。
微調整は、ハイパーパラメータを調整することなく出力の一貫性を向上させるために、6FPSと モーションバケット Id 127 で固定された条件で実行されました。これらの条件はまだ調整可能であり、削除されていません。固定コンディショニング設定以外のパフォーマンスは、SVD 1.0と比較して異なる場合があります。
mkshingさんによるデモが公開される
mkshingさんの善意によるデモと思われるコードが公開されています
SVD 1.1 seems to have been released 👀
— mkshing (@mk1stats) February 4, 2024
HF: https://t.co/95K8npSg45
For those who can't wait for the official announcement, you can try it on this colab for free.
Colab: https://t.co/SiYDRzLxTA
1/3#SVD https://t.co/FXC3wllPdB pic.twitter.com/yPrL3SIOps
SVD1.1がリリースされたようです👀。
HF: http://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
正式発表を待ちきれない方は、こちらのコラボで無料体験できます。
Colab:http://colab.research.google.com/github/mkshing/notebooks/blob/main/stable_video_diffusion_img2vid.ipynb
1/3
I found it interesting to use img2vid for ads. The background can be motionable while the caption doesn't change much.
— mkshing (@mk1stats) February 4, 2024
*init image is taken from https://t.co/1lEe2Cs8Bg
2/3 pic.twitter.com/eGr4QscZk8
img2vidを広告に使うと面白いですよ。背景は動かせるし、キャプションはあまり変わりません。*初期画像はhttps://cotori-sha.com/works/345。
*init image is taken from: https://t.co/99SFCBqLu3
— mkshing (@mk1stats) February 4, 2024
3/3 pic.twitter.com/ROaa3ruQI2
AICU mediaの編集部でも取り組んでみました!
どんなに忙しくても急なリリースでも手を動かさねば気がすまない しらいはかせCEOが「メモリが足りない―!」と言いながら丸1日取り組んでいましたが、ついに動いた、ということで、成功したようなので解説です。
https://twitter.com/o_ob/status/1754520368222732386
SVD1.1、うごいた! pic.twitter.com/X2HrDv0yf6
— Dr.(Shirai)Hakase しらいはかせ (@o_ob) February 5, 2024
準備するもの
Google Colabのデモコード
https://colab.research.google.com/github/mkshing/notebooks/blob/main/stable_video_diffusion_img2vid.ipynb
お使いのGoogleアカウントで「Open in Colab」してください。今回は有料版をおすすめします。
HuggingFaceのアカウント
途中でHuggingFaceアクセストークンが必要になります
https://huggingface.co/settings/tokens
から取得しましょう

HuggingFaceのTokenページでトークンをコピーして、Tokenに貼り付け「Login」を押します。

/content/generative-models/assets/test_image.png
こちらにサンプル画像がありますが、無視して進めて構いません。
T4(Colabフリープラン)でも一応動くようですが、25フレームの動画生成で約10分かかるそうです。また編集での実験では生成中に15GBのGPU RAMを超えることがあり、停止してしまうことが多くありました。
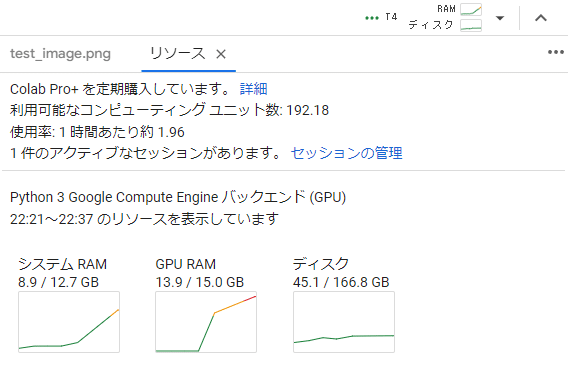
ここは奮発してA100で実験してみます。


A100の場合はだいたい1分程度で生成できています。
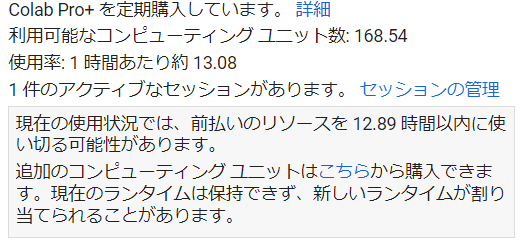
ちなみにA100を使うと、1ヶ月のコンピューティングユニットの割当を13時間程度で使いきってしまいますので緊張感があります!
結果は…?
YouTubeでお送りします!
Stable Video Diffusion 1.1 first trial
https://youtu.be/xgeRSi1PdEo
お気軽にシェアどうぞ
全体的に安定性が増している印象です。
mkshingさんのご指摘にあるとおり、ロゴのようなものは完全に安定しています。別のレイヤーとして扱われているような感じでしょうか。
また前回はアニメっぽいデジタルイラストレーションはパンのみになってしまったりと苦手な印象でしたが、SVD1.1は2-3回生成すると時々上手に生成されています。同じ入力でも何度か試してみるのが良さそうです。
こちらがSVD初版による生成結果です
謝辞:価値あるソースコードを公開していただいたMkshingさんに感謝です
補足:ソースコードの解説
def sample(
input_path: str = "assets/test_image.png", # Can either be image file or folder with image files
resize_image: bool = False,
num_frames: Optional[int] = None,
num_steps: Optional[int] = None,
fps_id: int = 6,
motion_bucket_id: int = 127,
cond_aug: float = 0.02,
seed: int = 23,
decoding_t: int = 14, # Number of frames decoded at a time! This eats most VRAM. Reduce if necessary.
device: str = "cuda",
output_folder: Optional[str] = "/content/outputs",
skip_filter: bool = False,
):
"""
Simple script to generate a single sample conditioned on an image `input_path` or multiple images, one for each
image file in folder `input_path`. If you run out of VRAM, try decreasing `decoding_t`.
"""どうやらdecoding_t を減らせばVRAMの消費は抑えられるようです。
モーションバケットIDやFPSについても記載があります。
if resize_image and image.size != (1024, 576):
print(f"Resizing {image.size} to (1024, 576)")
image = TF.resize(TF.resize(image, 1024), (576, 1024))画像サイズは1024x576にリサイズされます。64の倍数であることが求められます。
警告:提供されたコンディショニングフレームは576x1024ではありません。これはモデルが576x1024でしかトレーニングされていないため、最適なパフォーマンスではありません。cond_augを増やすことを検討してください。
モデル自体が1024x576でトレーニングされているようです。
パラメータはAdvanced Optionsで渡せます。
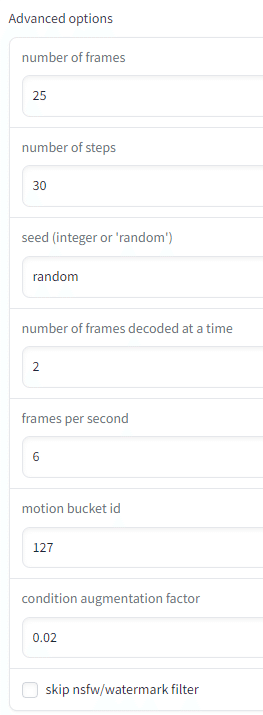
ランダムシードが指定できるので、安定させたければ固定すればいいかもしれません。
GPUをT4にしてゆっくり探索していきましょう!
応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!