
[ComfyMaster25] 画像を自由自在に!ControlNetで完全制御 #ComfyUI

求める画像を生成するために、プロンプトだけでは物足りないですよね?
そんな時、ControlNetが助けになります!
ControlNetは画像生成の制御性を大幅に向上させる革新的な技術として注目を集めています。特に、最新のSDXL(Stable Diffusion XL)モデルと組み合わせることで、その威力は一層増しています。
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第25回目になります。
本記事では、ComfyUIを使用してSDXLでControlNetを活用する方法を、初心者の方にも分かりやすく解説していきます。
前回はこちら
[ComfyMaster24] LoRAで表現をもっと自由に! スタイルを使いこなそう
1. ControlNetとは何か?
ControlNetは、既存の画像生成モデルに「制御」の要素を加える技術です。従来の画像生成AIは、プロンプト(テキストによる指示)のみをネットワークに画像を生成していました。そのため、言語で表現しきれない要素はランダム性が強く、ユーザーの意図通りにならないことも多々ありました。ControlNetは、この問題を解決するために開発されました。
ControlNetを使用すると、プロンプトに加えて、追加の情報をAIに与えることができます。この追加情報には、画像の輪郭線、深度情報、ポーズ、セグメンテーションマップなど、様々な種類があります。AIはこれらの情報をもとに、よりユーザーの意図に合致した画像を生成することができるようになります。
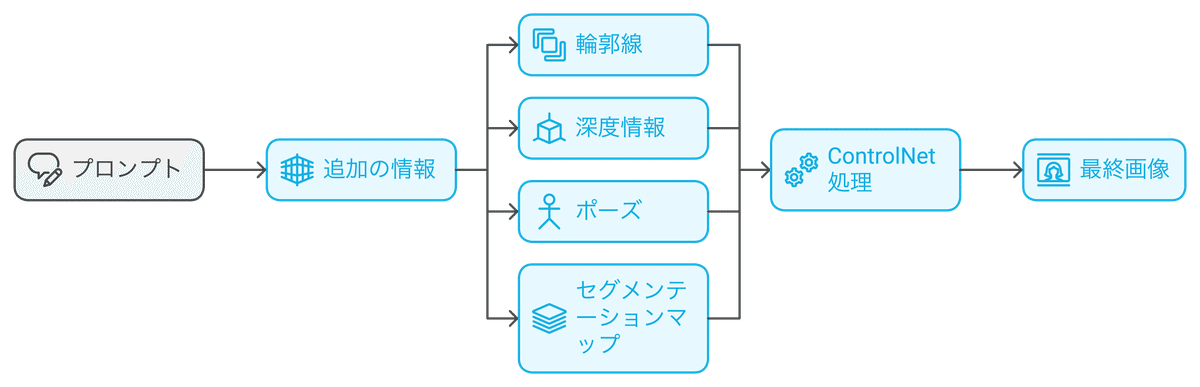
簡単に言えば、従来のモデルが「自由に絵を描くアーティスト」だとすれば、ControlNetは「具体的な指示を出せるアートディレクター」のような役割を果たします。
2. 各種ControlNetの説明と用途
ControlNetには、様々な種類があります。それぞれが異なる種類の条件に対応しており、用途も異なります。ここでは、代表的なControlNetの種類とその用途について解説します。
Canny Edge(キャニーエッジ)
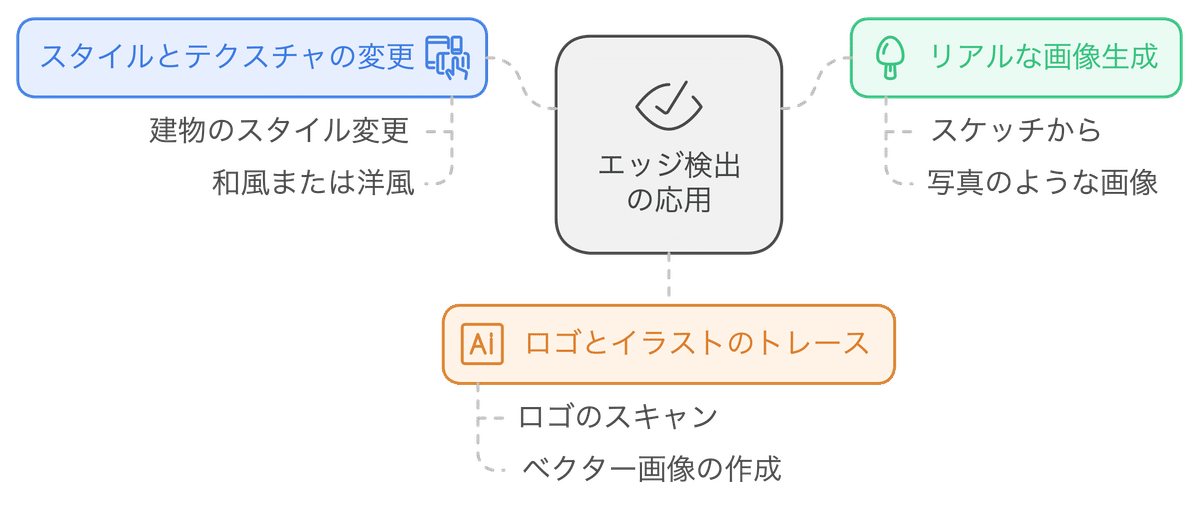
入力画像からエッジ(輪郭線)を検出し、そのエッジを元に画像を生成します。エッジ検出には、Cannyアルゴリズムと呼ばれる手法が用いられます。Cannyアルゴリズムは、ノイズの影響を受けにくく、正確なエッジを検出することができるため、ControlNetで広く利用されています。

主に以下のような用途で使用されます。
特定の形状を維持したまま、スタイルやテクスチャを変更したい場合: 例えば、建物の写真からエッジを検出し、そのエッジを元に、建物のスタイルを和風や洋風に変更することができます。
スケッチや線画を元に、リアルな画像を生成したい場合: 手描きのスケッチや線画からエッジを検出し、そのエッジを元に、写真のようなリアルな画像を生成することができます。
ロゴやイラストのトレース: ロゴやイラストをスキャンしてエッジを検出し、そのエッジを元に、ベクター画像を作成することができます。
Depth Map(深度マップ)
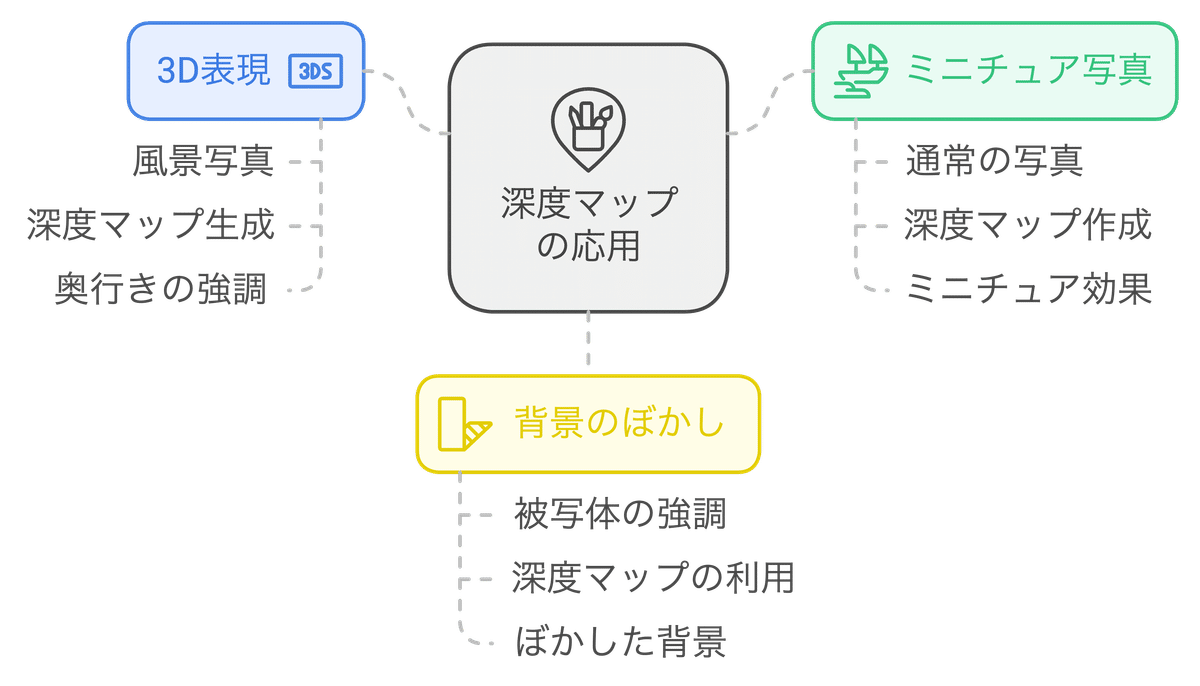
入力画像の奥行き情報を利用して、立体感のある画像を生成します。奥行き情報は、画像中の各ピクセルがカメラからどれだけ離れているかを表す情報です。深度マップは、白黒画像で表現され、白い部分が近く、黒い部分が遠くを表します。

主に以下のような用途で使用されます。
3D的な表現や、奥行きを強調したい場合: 例えば、風景写真から深度マップを生成し、その深度マップを元に、より奥行き感のある風景画を生成することができます。
ミニチュア風写真: 通常の写真から深度マップを生成し、その深度マップを元に、ミニチュア模型のような写真を作成することができます。
背景のぼかし: 深度マップを利用して、被写体以外をぼかした写真を作成することができます。
Pose Estimation(ポーズ推定)
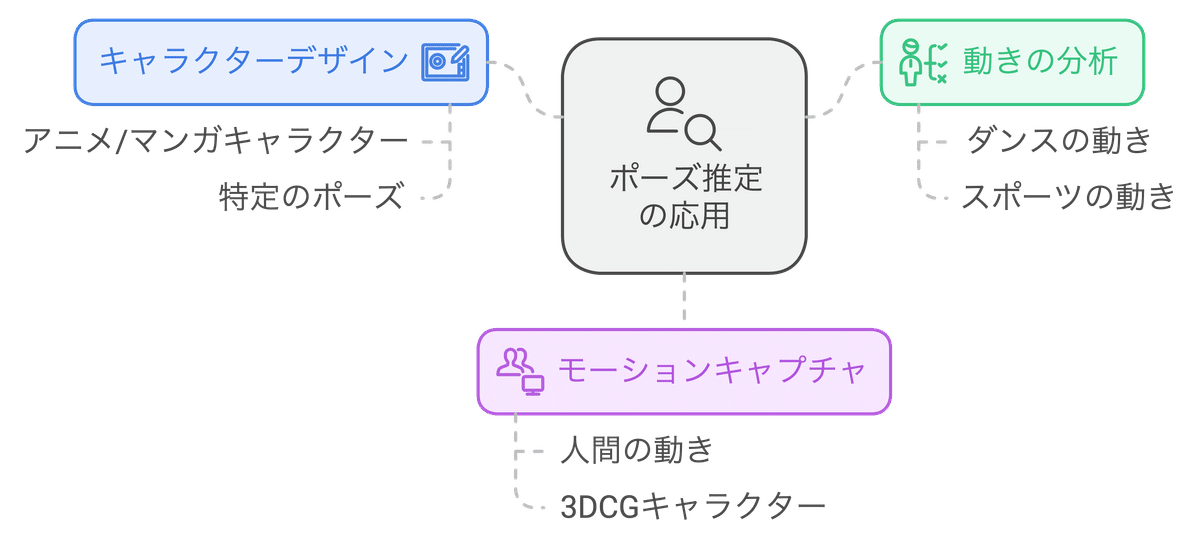
入力画像から人間の骨格情報(ポーズ)を推定し、そのポーズを元に画像を生成します。ポーズ推定には、OpenPoseなどのAIモデルが用いられます。OpenPoseは、画像から人間の関節の位置を検出し、骨格を推定することができます。

主に以下のような用途で使用されます。
キャラクターデザインやイラスト制作で、特定のポーズを表現したい場合: 例えば、人物の写真からポーズを推定し、そのポーズを元に、アニメキャラクターや漫画キャラクターを生成することができます。
ダンスやスポーツの動きを分析: ビデオからポーズを推定することで、ダンスやスポーツの動きを分析することができます。
モーションキャプチャ: 人間の動きを計測し、その動きを3DCGキャラクターに反映させることができます。
Scribble(落書き)
簡単な手描きの線画から、詳細な画像を生成します。Scribble ControlNetは、線画を元に、画像の内容を推定し、その内容に沿った画像を生成します。

主に以下のような用途で使用されます。
アイデアのスケッチを元に、具体的なビジュアルを得たい場合: 例えば、新しい製品のアイデアをスケッチし、そのスケッチを元に、製品の完成イメージを生成することができます。
ラフ画からイラストを生成: 簡単なラフ画を元に、詳細なイラストを生成することができます。
ストーリーボード作成: 映画やアニメのストーリーボードを作成する際に、Scribble ControlNetを利用して、各シーンのイメージを生成することができます。
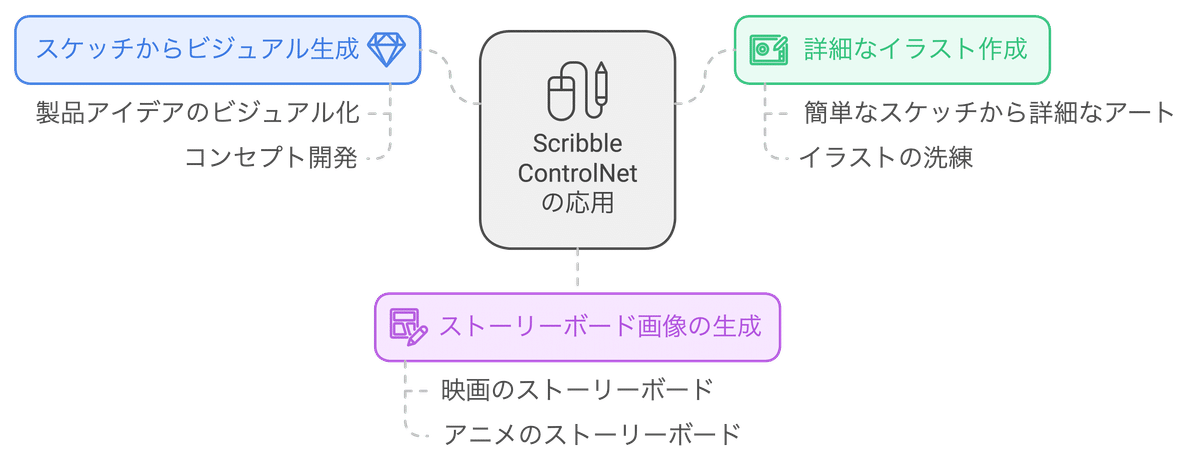
Segmentation Map(セグメンテーションマップ)
入力画像を複数の領域に分割し、各領域にラベルを付けたものです。セグメンテーションマップは、画像中のどの部分がどのオブジェクトに対応するかをAIに教えるために使用されます。

主に以下のような用途で使用されます。
シーン全体の構成をコントロールしたい場合: 例えば、風景写真をセグメンテーションマップで分割し、「空」・「海」・「山」などのラベルを付けることで、それぞれの領域の色やテクスチャを個別に制御することができます。
画像編集: セグメンテーションマップを利用して、特定のオブジェクトだけを切り抜いたり、色を変更したりすることができます。
自動運転: 自動運転システムでは、セグメンテーションマップを利用して、道路、歩行者、信号機などを認識しています。
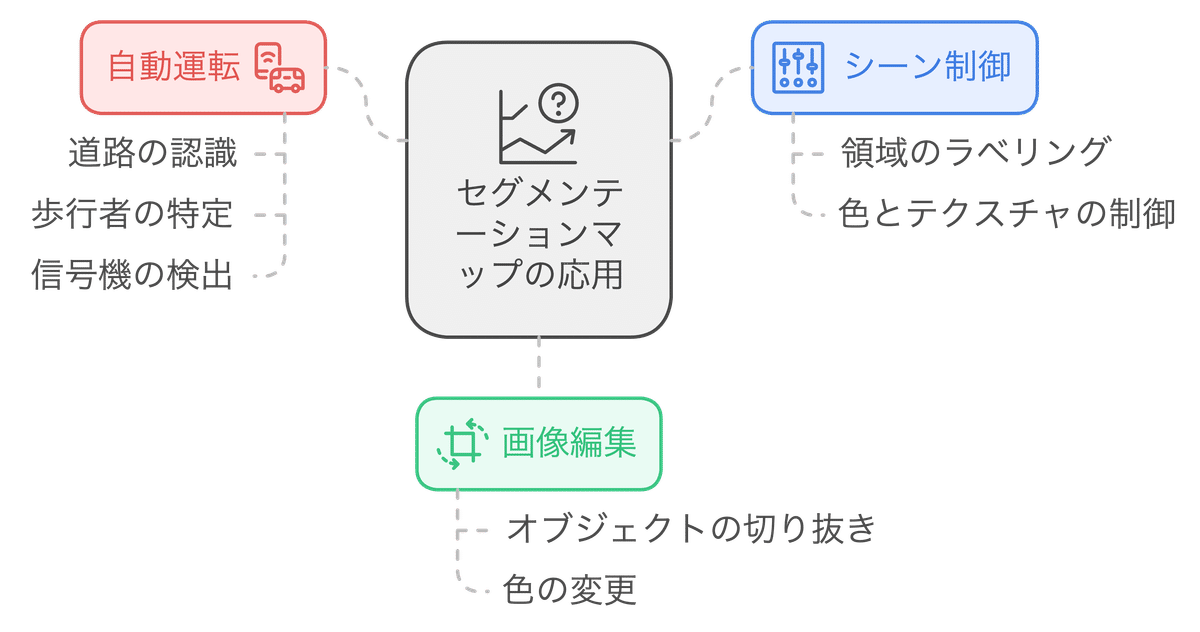
HED boundary
HED boundary(Holistically-Nested Edge Detection)は、画像からエッジ(境界線)を検出するControlNetです。Canny Edgeと同様に画像の輪郭を捉えますが、HED boundaryはより繊細で複雑なエッジを検出することに特化しています。これは、人物の髪の毛や衣服の細かい模様、自然風景の複雑な葉っぱの形状など、Canny Edgeでは捉えきれない微細なエッジを検出できることを意味します。

主に以下のような用途で使用されます。
より写実的な画像生成: HED boundaryは、より詳細なエッジ情報を捉えるため、生成される画像のリアリティを高めるのに役立ちます。特に、人物のポートレートや自然風景など、細部まで描き込みたい場合に効果的です。
複雑なテクスチャの再現: 衣服の織り目や木の葉の葉脈など、複雑なテクスチャをより忠実に再現したい場合に適しています。
アニメ・漫画風画像の生成: 線画の質感を重視するアニメや漫画風の画像を生成する場合にも、HED boundaryは有効です。
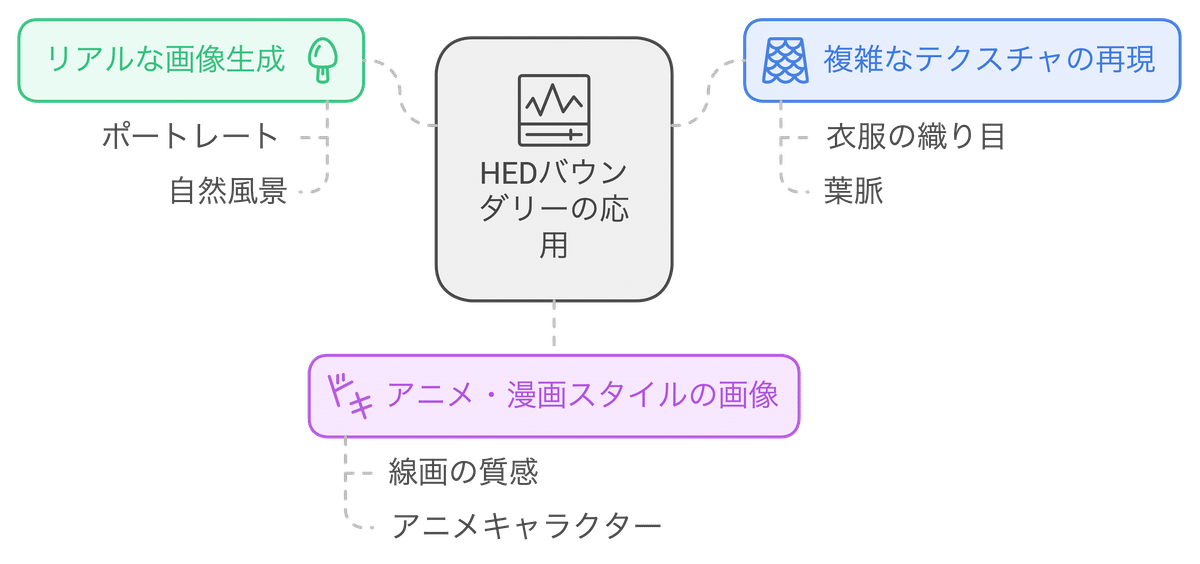
Normal map (法線マップ)
Normal map(法線マップ)は、画像の表面の向きを表す情報です。各ピクセルに、その地点における表面の法線ベクトル(表面に対して垂直なベクトル)の情報が格納されています。法線マップは、3Dグラフィックスで物体の表面の陰影や反射を表現するために広く使われています。

ControlNetにおけるNormal mapは、この法線マップの情報を利用して、立体感や陰影をより精密に制御することができます。
主に以下のような用途で使用されます。
3Dモデルのような立体的な画像生成: 法線マップの情報を利用することで、光源の位置や強さを考慮した、リアルな陰影表現が可能になります。
金属やガラスなどの質感表現: 法線マップは、金属の光沢やガラスの透明感など、材質感を表現するのにも役立ちます。
彫刻やレリーフのような表現: 法線マップを利用することで、画像に彫刻やレリーフのような凹凸感を表現することもできます。
Lineart
Lineartは、画像から線画を抽出するControlNetです。Canny EdgeやHED boundaryも線画を検出できますが、Lineartは特にアニメや漫画のような線画スタイルの画像に特化しています。

主に以下のような用途で使用されます。
アニメ・漫画風画像の生成・編集: 線画を強調したイラストを作成したり、既存の画像を線画化したりすることができます。
イラストの着色: 線画を抽出後、ControlNetと組み合わせて自動的に着色したり、手動で着色したりすることができます。
線画のクリーンアップ: スキャンした線画のノイズ除去や線の補正など、線画の編集作業に利用できます。
Pidi (Softedge)
Pidi (Softedge) は、画像からソフトなエッジを検出するControlNetです。Canny EdgeやHED boundaryのようなシャープなエッジではなく、ぼかしのかかったような滑らかなエッジを抽出します。Pidiは、softedgeという別名でも知られています。

主に以下のような用途で使用されます。
水彩画やパステル画のような、柔らかいタッチの画像生成: ソフトなエッジは、水彩画やパステル画など、境界線がぼやけた表現に適しています。
被写体の輪郭を強調しながら、自然な雰囲気を保ちたい場合: シャープなエッジでは硬すぎる印象になる場合に、Pidiを用いることで、より自然で優しい雰囲気の画像を生成できます。
写真から絵画風に変換: 写真のエッジをPidiでソフトにすることで、絵画のような風合いを出すことができます。
TEED
TEEDは、Tiny and Efficient Edge Detector の略称で、軽量ながらも高精度なエッジ検出を行うControlNetです。わずか58Kのパラメータ数で、最先端モデルと比較してサイズが0.2%未満と非常に軽量なのが特徴です。
ControlNetにおいては、TEEDは入力画像からソフトなエッジを抽出し、それを元に画像生成を行います。Canny Edgeなどとは異なり、境界線がぼやけた、より自然で滑らかなエッジ検出を得意としています。特にSDXLとの組み合わせに最適化されています。

主に以下のような用途で使用されます。
SDXLを用いた、ソフトエッジを強調した画像生成: 水彩画、パステル画、印象派の絵画など、ソフトなタッチの画像を生成する際に効果的です。
入力画像の雰囲気を維持した画像生成: 画像全体の構図や色調を維持しつつ、異なる要素を追加したり、スタイルを変更したりすることができます。
プロンプトエンジニアリングの負担軽減: プロンプトなしで、入力画像のエッジ情報を元に画像生成ができるため、プロンプト作成の手間を省くことができます。
MLSD
MLSD (Multi-Level Line Segment Detector) は、画像から直線を検出することに特化したControlNetです。建物や道路、家具など、直線的な要素が多い画像から、正確な直線情報を抽出することができます。

主に以下のような用途で使用されます。
建築物や都市景観の画像生成: 建物の輪郭や道路のラインなどを正確に捉え、リアルな都市景観を生成できます。
幾何学模様のデザイン: 直線や多角形を組み合わせた幾何学模様のデザインを作成する際に役立ちます。
パースペクティブの修正: 写真の歪みを修正したり、パースペクティブを強調したりする際に利用できます。
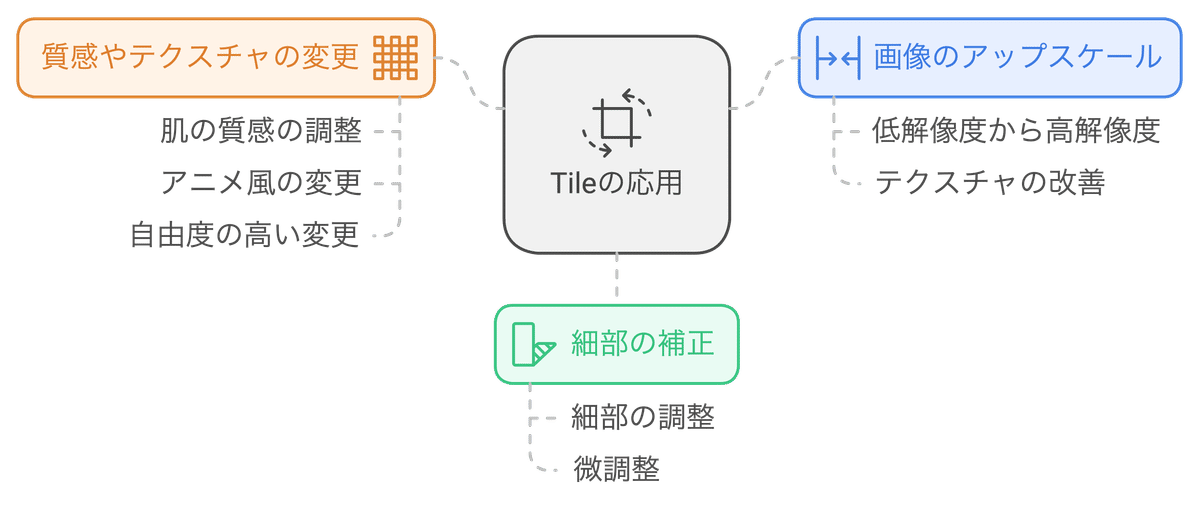
Tile
Tile は、入力画像をタイル状に繰り返し配置して、シームレスなパターンを生成するControlNetです。元絵の構図や特徴を維持した状態で画像生成が可能なため、

主に以下のような用途で使用されます。
画像のアップスケール:低解像度の画像を高解像度に変換する際に使用されます。Tileモデルは、画像の細部を補正し、テクスチャを改善することで、より高品質な画像を生成します。
細部の補正:生成された画像の細部を修正する際に使用されます。Stable Diffusionが細部の調整に苦手な場合、ControlNet Tileを使用して、画像の細部を微調整することができます。
質感やテクスチャの変更:画像の質感やテクスチャを変更する際に使用されます。ControlNet Tileは、肌の質感を調整したり、アニメ風にしたり、自由度の高い変更が可能です。
3. ControlNetの使用準備
カスタムノードのインストール
ControlNetを使用するために、「ComfyUI's ControlNet Auxiliary Preprocessors」をインストールします。標準ノードだけでもControlNetを使用できますが、本記事で紹介したControlNetの一部しか実現できません。そのため、カスタムノードをインストールし、使用できるControlNetの幅を広げます。ComfyUI's ControlNet Auxiliary Preprocessorsは、ComfyUI Managerからインストール可能です。
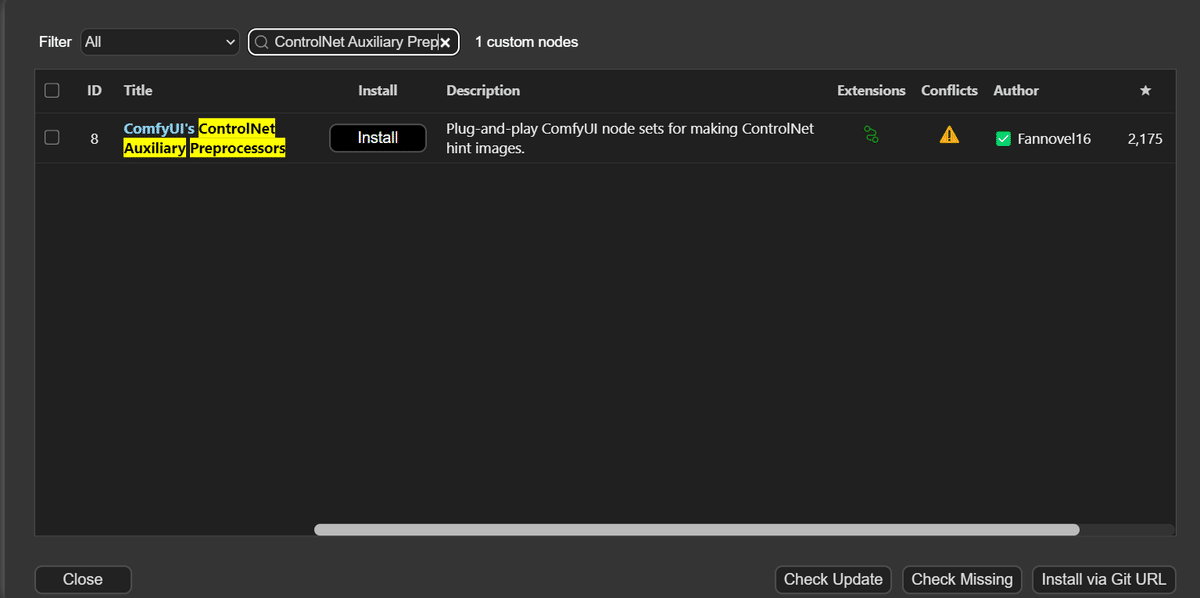
以下がリポジトリになります。
https://github.com/Fannovel16/comfyui_controlnet_aux
プリプロセッサーモデルのダウンロード
ControlNetの使用には、プリプロセッサーモデルが必要になるため、そのモデルをダウンロードします。SDXLには、controlnet-union-sdxl-1.0という、これまでに紹介した各種ControlNetを1つに集約した便利なモデルがあります。今回は、このモデルを使用します。以下のリンクよりファイルをダウンロードし、Google Colabを使用しているDriveで「ComfyUI/models/controlnet」フォルダに格納してください。
https://huggingface.co/xinsir/controlnet-union-sdxl-1.0/resolve/main/diffusion_pytorch_model.safetensors
参照元画像
ControlNetの参照元画像として以下の画像を使用します。

画像ファイルは、以下よりダウンロードください。
画像をダウンロード(右クリックで保存)
☆この画像にworkflowは埋め込まれていません。
workflowは文末にて。
4. ワークフロー解説
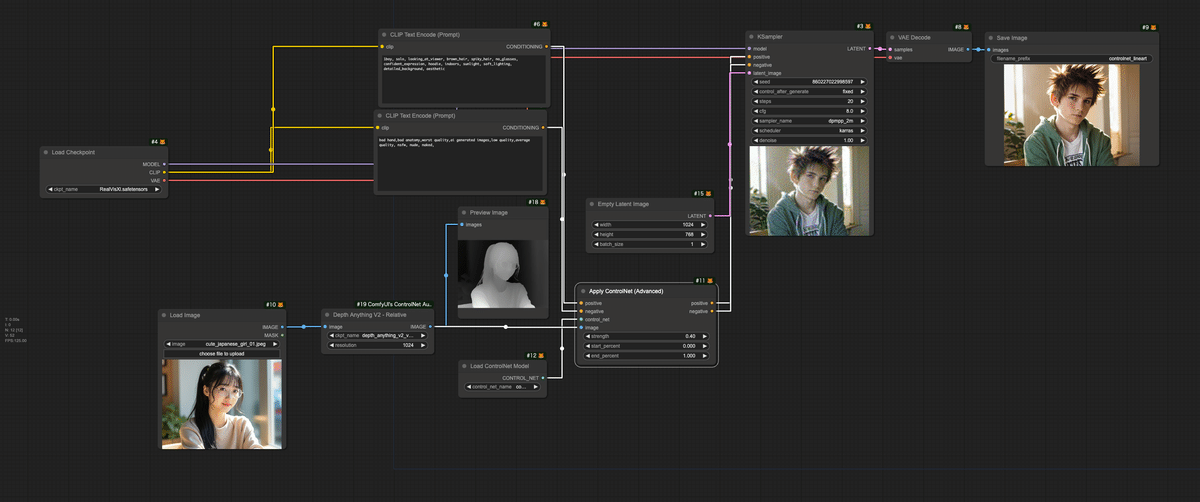
このワークフローは、入力された女性の画像の構造(深度情報)を保持しながら、指定されたプロンプトに基づいて男性の特徴を持つ新しい画像を生成します。結果として、元の画像の構図や照明条件を維持しつつ、全く異なる人物(男性)の画像が生成されることが期待されます。これは、ControlNetと深度マップを組み合わせた高度な画像変換・生成の例といえます。
以下に、このワークフローの主要な部分とその機能を図示し、詳細に説明します。
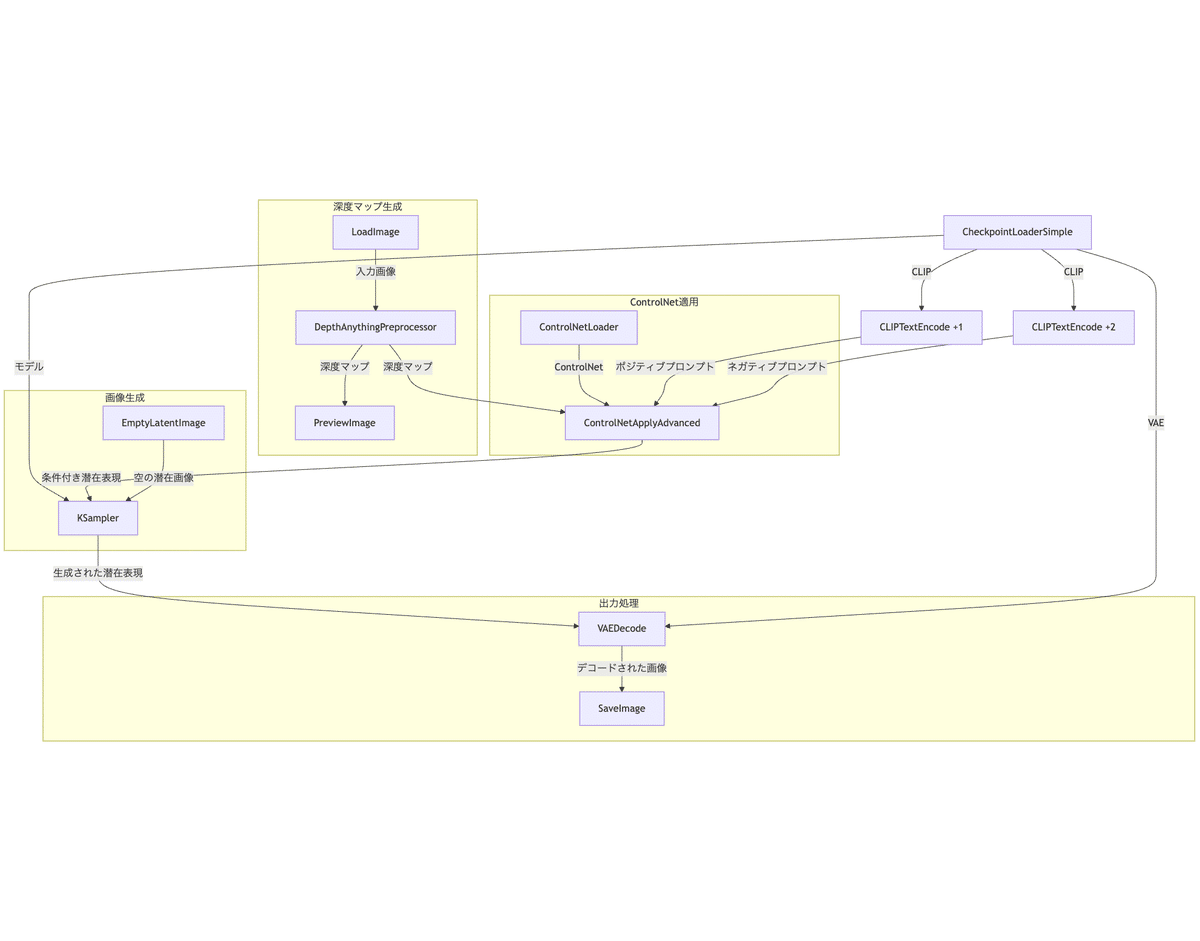
入力画像の読み込みと深度マップ生成
Load Imageノード: 「girl-for-controlnet.jpeg」を読み込みます。
Depth Anything V2 - Relativeノード: 入力画像から深度マップを生成します。
使用モデル: 「depth_anything_vitl14.pth」
解像度: 512
Preview Imageノード: 生成された深度マップをプレビューします。
モデルとControlNetの読み込み
Load Checkpointノード: 今回は「RealVisXl.safetensors」モデルを使用。
Load ControlNet Modelノード: 「controlnet-union-sdxl-1.0.safetensors」を読み込みます。
プロンプト処理 (CLIPTextEncode ノード x2)
ポジティブプロンプト: 「1boy, solo, looking_at_viewer, brown_hair, spiky_hair, no_glasses, confident_expression, hoodie, indoors, sunlight, soft_lighting, detailed_background, aesthetic」
ネガティブプロンプト: 「bad hand,bad anatomy,worst quality,ai generated images,low quality,average quality, nsfw, nude, naked,」
ControlNetの適用 (Apply ControlNet (Adovanced) ノード)
深度マップ、ControlNet、およびプロンプトの条件付けを組み合わせます。
強度: 0.40 (ControlNetの影響力)
潜在画像の準備 (Empty Latent Image ノード)
「girl-for-controlnet.jpeg」と同じサイズである「1024x768」を設定
画像生成 (KSampler ノード)
Seed: 860227022998597
Steps: 20
CFG Scale: 8
Sampler: dpmpp_2m
Scheduler: karras
画像のデコードと保存
VAE Decode ノード: 生成された潜在表現を実際の画像にデコードします。
Save Image ノード: 最終的に生成された画像を "controlnet_lineart" という名前で保存します。
5. ワークフローの検証
それでは、ワークフローを実行してみましょう。ControlNetの強度を0.40で生成してみます。以下が生成結果です。しっかりプロンプトに従った画像になっています。

参照元画像と比較してみましょう。構図を維持しながら、人物を変えることに成功しています。

次にControlNetの強度を0.80にしてみます。そうすると、参照元画像の女性に近づき、ポニーテールの中性的な男性の画像が生成されました。
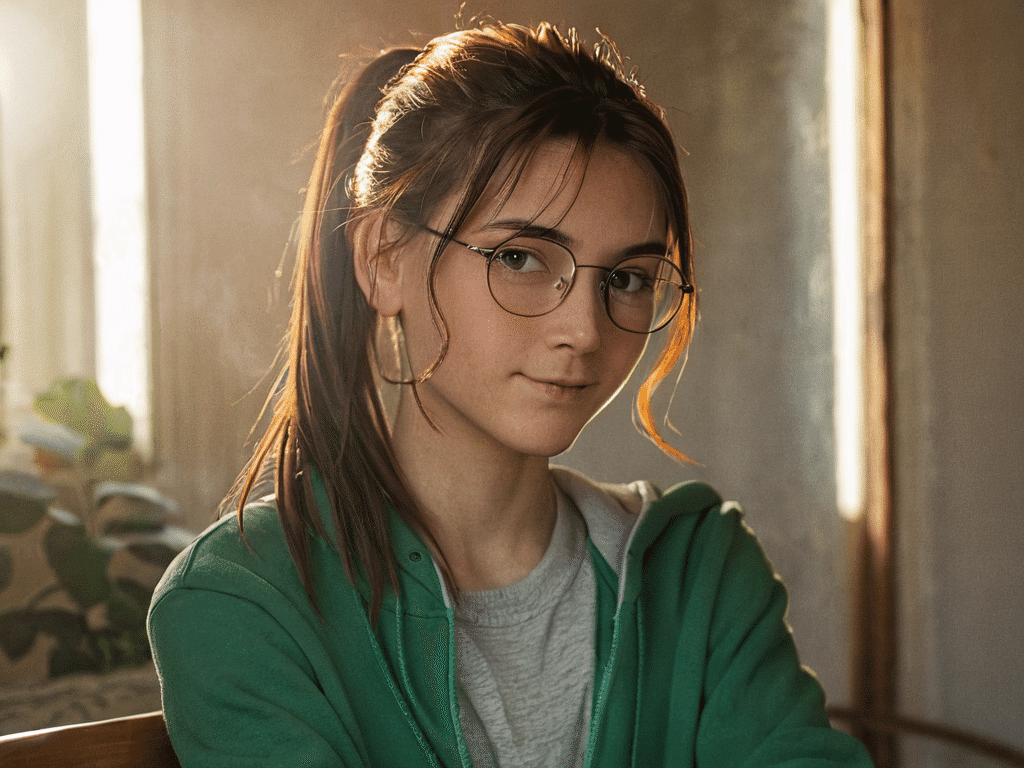
反対に強度を0.10と低くしてみます。今度は参照元画像から離れ、体勢も変わってしまっています。

以下が強度別の生成結果になります。強度が高くなるにつれ、参照元画像に近づき、強度が小さくなるにつれ、参照元画像に似なくなっていることが分かります。

6. まとめ
ControlNetは、画像生成AIの可能性を飛躍的に広げる革新的な技術です。輪郭線、深度情報、ポーズなど様々な条件をAIに与えることで、これまで以上にユーザーの意図を反映した画像生成が可能になります。この記事では、Canny Edge、Depth Map、Pose Estimationなど主要なControlNetの種類とその用途を紹介し、具体的なワークフロー例を通して、その驚くべき効果を実証しました。ControlNetを使いこなすことで、マーケティング素材の作成、イラストやデザイン制作、3Dモデリングなど、様々な分野で創造性を加速させることができます。ぜひ、ControlNetの力を体感し、あなたのクリエイティブな活動を新たなステージへと導いてください。
次回は、 ControlNetでイラストを精密に実写化!を紹介します。
乞うご期待!
https://note.com/aicu/n/n4fafc970da0a
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
ワークフローは、以下よりダウンロードください。
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!