
キャラLoRA学習ガイド2024年5月版 #SD黄色本

この記事では、Stable Diffusion で LoRA を使用して作品を制作した経験のある人向けに、キャラクターLoRA の学習、制作方法やそれに使用する Colab notebook を解説します。
この記事を読むと、こんな感じのデルタもんが生成できるLoRAが作れるようになります!

またこちらの記事は、AICU マガジン5月号のアップデート内容の一部になります。これらのLoRAを使って漫画を制作する方法や生成AIの倫理や法律についてはぜひこちらをご覧ください!
皆さん、AI でキャラクターや漫画を生成しようとしたことはありますか?
特定のキャラクターを何回も生成したいけど、プロンプトだけではなかなかキャラクターデザインや画風が揃わない…そんな時に、Stable Diffusion の LoRA を使用して画像を生成した経験がある人も多いと思います。
しかし LoRA を使っていても、自分で LoRA が作れる人は少ないはず。
そこで 5月15日(水)に、書籍「画像生成 AI Stable Diffusion スタートガイド」の公式ワークショップ「デルタもん LoRA を作ろう!」を開催しました。

BlendAI 社が運営する AI キャラクター「デルタもん」のデータセットを使用し、Google Colab で LoRA 学習を行うワークショップです。
この記事ではその復習として、デルタもん LoRA を作る方法の全容を3ステップで解説します!
漫画やイラストの制作のための LoRA が欲しい方や、機械学習に興味のある方はハンズオンで試してみてください。
(1) データセットを用意しよう
データセットとは?
まず LoRA 学習に欠かせないのがデータセットです。これは学習元となる画像のことで、今回制作する SD1.5 の LoRA の場合は15〜50枚程度の学習元画像を用意する必要があります。
今回は、例としてワークショップで配布し使用したデルタもんのデルタもんのデータセットを使用します。このデータセットには、デルタもんを運営している BlendAI 社からいただいた LoRA 用データセットと3Dモデル、AICU で制作した表情差分などを使用しています。
すべての画像はこちらからご覧ください。
デルタもん LoRA 用データセット(AICU版)→(https://huggingface.co/AICU/SDXL-LoRA/resolve/main/Deltamon.zip)
データセット作りのコツ
学習元画像と聞いて、「デルタもんを学習させたいなら、デルタもんの画像を用意すればいいだけでしょ?」と思うかもしれません。しかしデータセット収集は奥が深く、枚数や画像の質が LoRA の完成度に大きく影響してきます。
まずキャラクターのデータセットのコツは、ポーズや表情、角度などにバリエーションをつけることです。
デルタもんのようにキャラクターを学習させたい場合、そのキャラクターの様々な角度の画像がないと、一方向から見た画像しか生成されなくなってしまいます。例えば左側を向いたデルタもんの画像のみを学習させると、AI は「『デルタもん』は左を向いているものだ!」と勘違いしてしまいます。余計な情報が学習されてしまうということです。
そのため、このように様々な角度から撮影したデルタもんをデータセットに組み込みます。
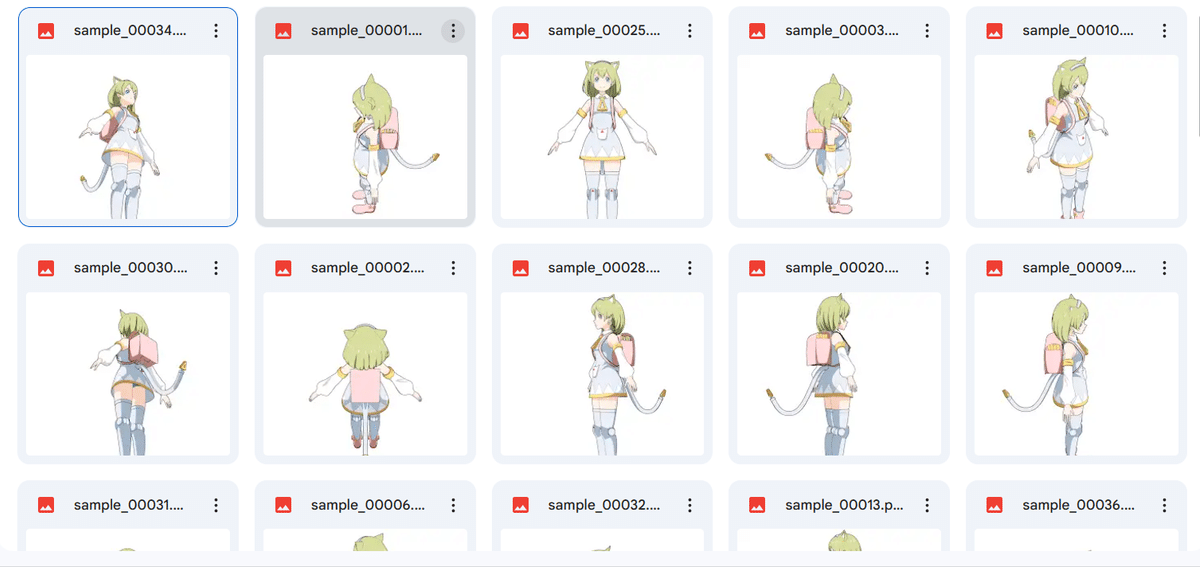
さらに、この状態のデータセットだと、デルタもんの全身のみが生成されやすくなってしまうと考えられるので、上半身のみのものも追加します。これは公式ホームページで公開されている立ち絵から切り取らせていただきました。またこの画像により胸元の三角のネクタイが良く学習されるのではないかとも考えます。

最後に、様々な表情が生成されるように、表情差分も追加します。
これは上半身の画像に表情を手描きで加筆し、i2i にかけて整えたものです。

最後に全ての画像をコピー&ペーストし、コピーした画像を左右反転します。
これにより、キャラクターの向きが偏って学習されにくくなります。

データセットができました。
学習するときのために、zipファイルにまとめ、Google Drive や Hugging Face などにアップロードしておきましょう。
(2) Google Colaboratory で学習しよう
それでは、作ったデータセットを Google Colaboratory(以下 Colab)を使用して学習していきます。ローカルPC でも学習する方法はありますが、多大なリソースを必要とするため、今回は Colab を使用する方法のみ紹介していきます。
Colab notebook の用意
まずは AICU の GitHub から、LoRA 制作用 Colab notebook にアクセスします。
URL →( https://j.aicu.ai/SDLoRA2)
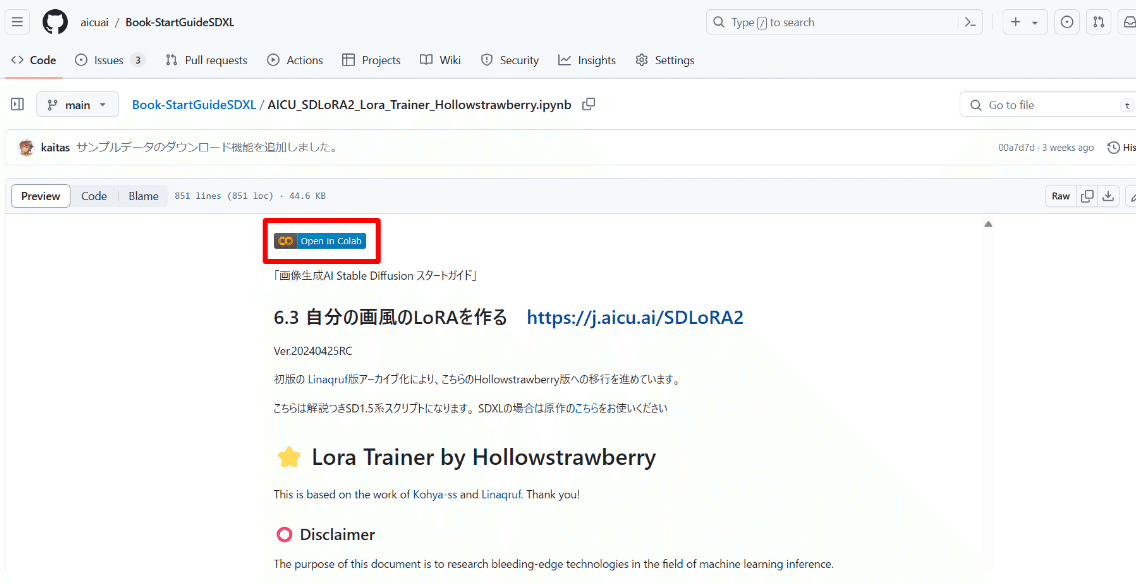
画面上部の「Open in Colab」のボタンを選択し、Colab notebook を開きます。このような画面になります。
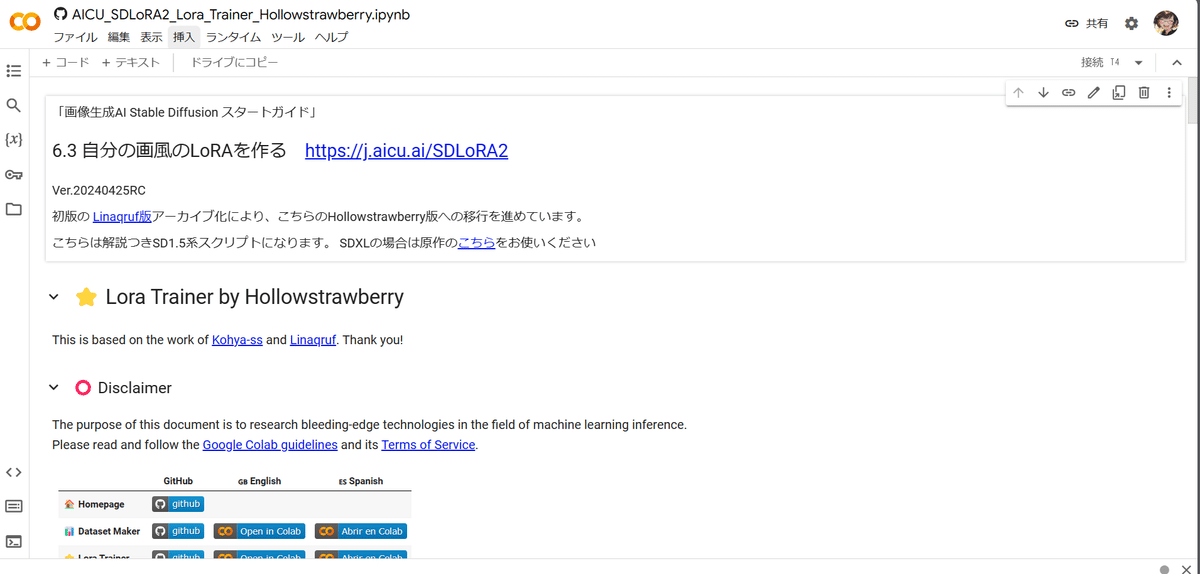
このままでは出力結果などが保存されないので、この notebook を自分のドライブにコピーして保存します。
「ファイル」から「ドライブにコピーを保存」でコピーされたnotebook が開きます。
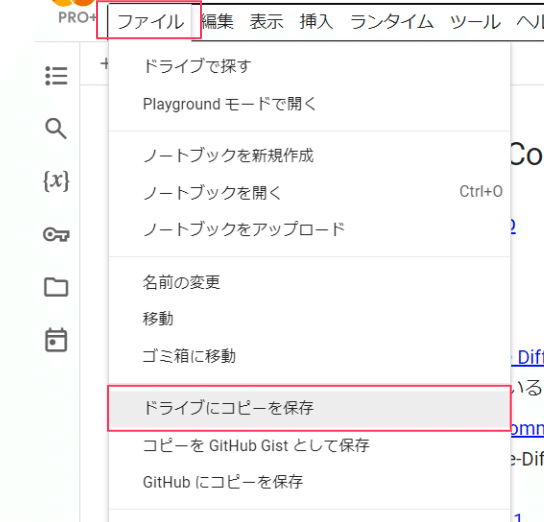
notebook のファイル名に、「のコピー」が付いているのがドライブに保存できている目印です。
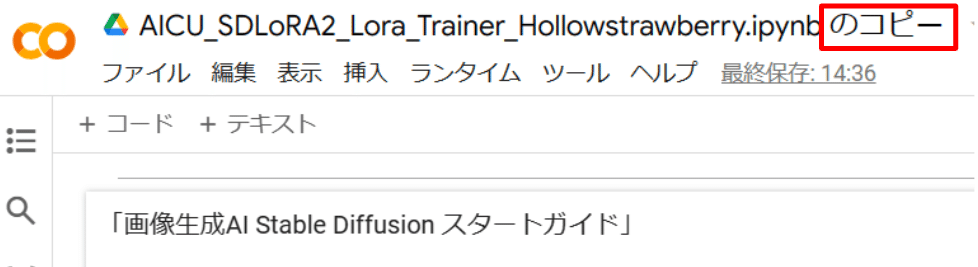
では各種設定を見ていきましょう。
データセットの展開
まずはデータセットを展開し、学習の用意をしていきます。
最初のセルがデータセットの準備を行うセルです。
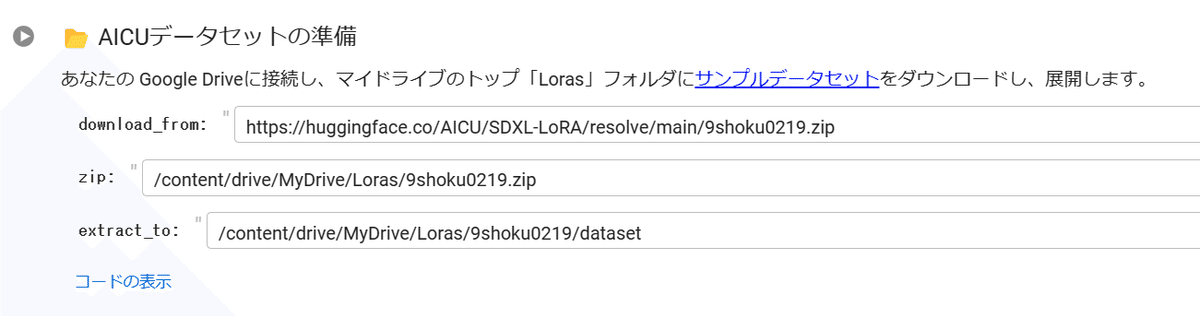
最初の欄「download_from」には、データセットのURLを入力します。
先ほど紹介したデルタもんのデータセットを使用する場合は、こちらのURLを貼り付けます。
https://huggingface.co/AICU/SDXL-LoRA/resolve/main/Deltamon.zip
次の欄「zip」は、ドライブ内のどこにzipファイルを保存するかを指定します。
基本的には、zipファイル名(デフォルトの Colab notebook では「9shoku0219」の箇所)を「Deltamon.zip」など任意のファイル名に変更するだけで大丈夫です。
最後の欄「extract_to」では、どこに画像を展開するかを指定します。
こちらも同様に、/dataset の前(デフォルトの Colab notebook では「9shoku0219」の箇所)を「Deltamon」など任意のファイル名に変更します。
これでデータセットのパスなどの設定は完了です。セルを実行します。
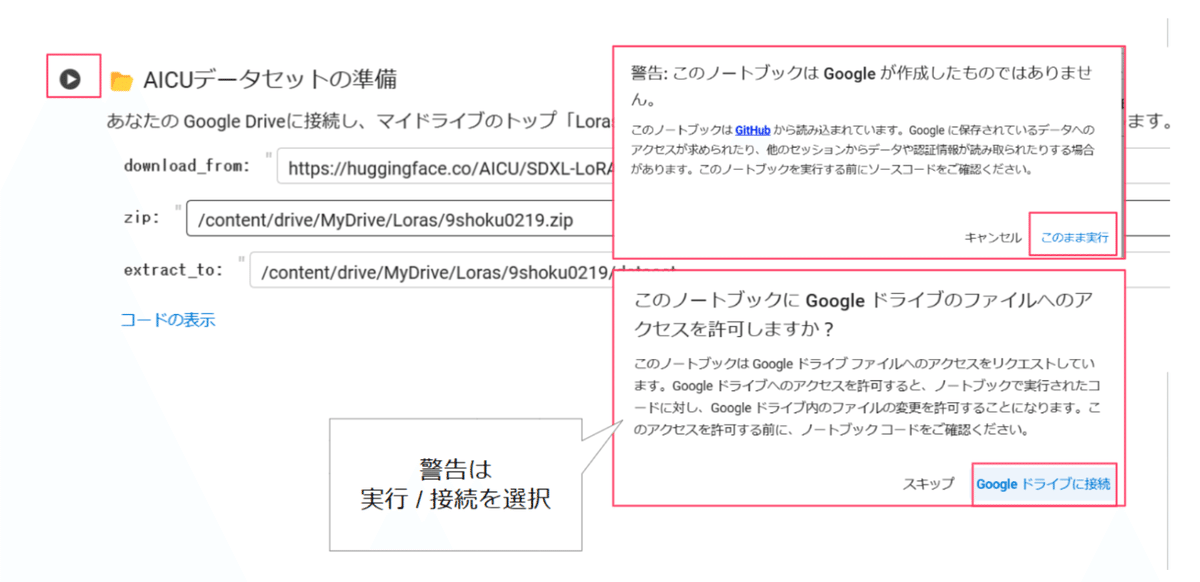
警告が表示されたら、実行/接続を選択します。
これでデータセットの準備は完了です。次のセルに移りましょう。
学習の設定
では、「Start here」のセルに移っていきます。ここでは学習の際の様々なパラメータの設定を行います。
まずは「Setup」の「project_name」を「Deltamon」など任意の単語に変更しましょう。これは LoRA のファイル名になります。
またこれは必ず、前のセルで設定した画像フォルダの名前と同一である必要があります。
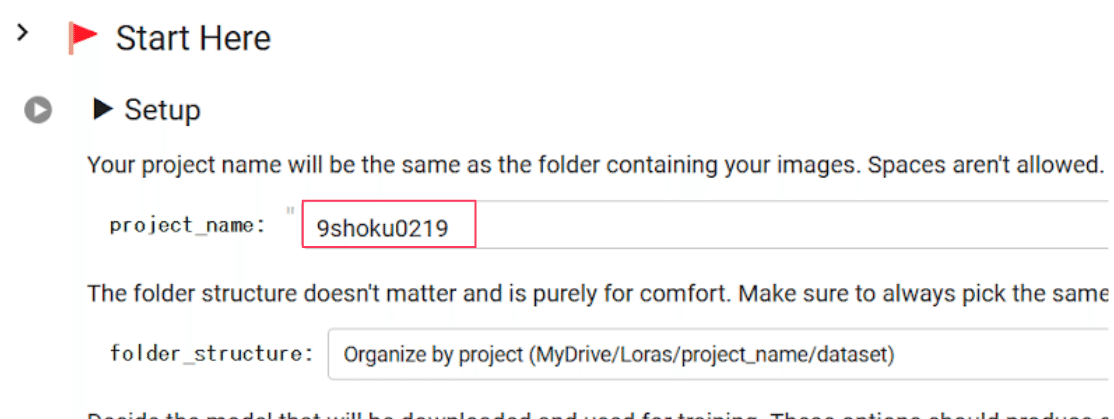
この先のモデル、トリガーワードや学習パラメータなどはまずはデフォルトで実行して大丈夫ですが、応用がきくように解説していきます!
学習に使用する画像生成モデルを選択します。
デフォルトは「AnyLoRA」で、デルタもんなどのアニメ調のキャラクターを学習する際はこちらをおすすめします。実写の画像を学習する場合は「Stable Diffusion」を選択すると学習の精度が上がるので、学習する画像によって使い分けましょう。

次に、「Steps」を見ていきます。
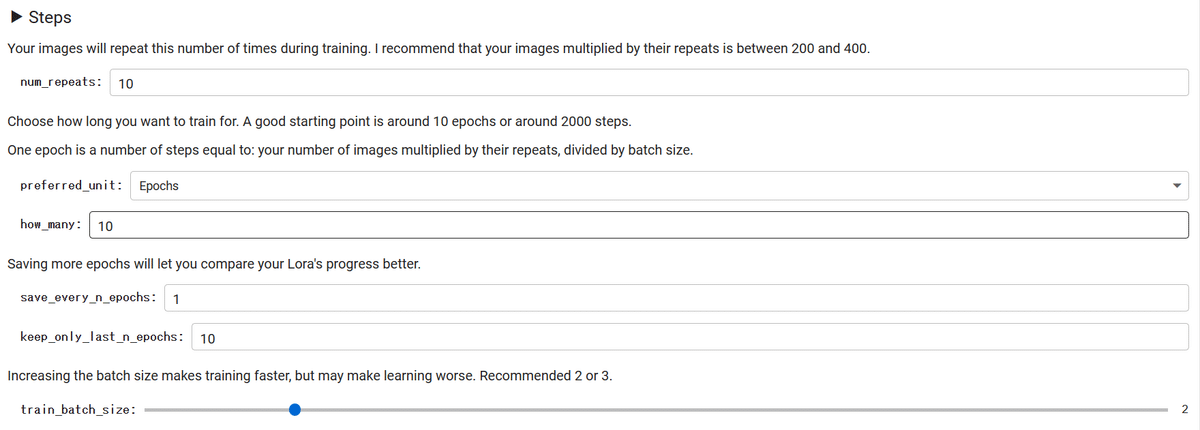
変更する必要があるのは以下の項目です。
・num_repeats
一連の学習を行う回数
・how_many
データセットを学習する繰り返し回数
・train_batch_size
一回に学習する画像の枚数
これらの数の最適な大きさは、画像の枚数や作りたいもの、どのような画像を学習するかによって全く異なるので、一概に何回とは言い難いです。
しかし、(num_repeats) x (how_many) x (データセットの枚数)÷ (train_batch_size) が3000〜8000になると精度の高い LoRA になりやすいのではないかと感じます。この大きさは皆さんの作りたい LoRA で研究してみてください。
また、train_batch_size については、大きいほど大雑把に、小さいほど細部まで画像を学習します。そのためキャラクターなど細かな特徴を学習させたい場合には2や3、画風などを全体的な特徴を学習させたい場合は6や8を選択するのがよいかと感じます。
これで Setup のセルの設定は完了です。実行して、学習を開始しましょう。
正しく実行されれば、30分~1時間程度で実行が終了します。
(3) 生成した LoRA を回収しよう
では生成できた LoRA を回収し、画像を生成しましょう。
LoRA は、Google Drive のマイドライブ>Loras>LoRA名>output フォルダに格納されています。
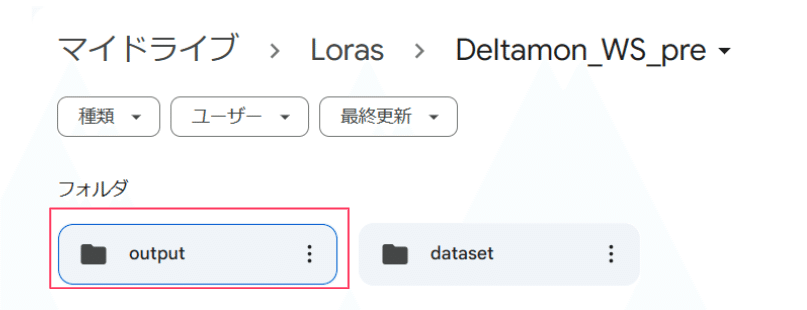
この中のファイルを最終更新順に並べ、一番左のファイルが最終成果物です。
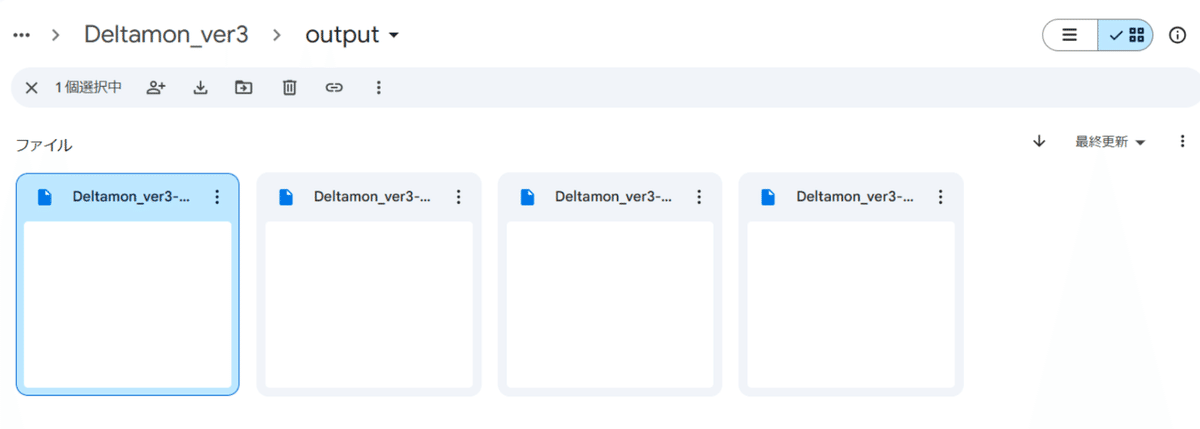
Colab で画像生成を行う場合はこれを移動します。
ローカルで使用する場合はダウンロードしてLoRAのディレクトリに移動しましょう。
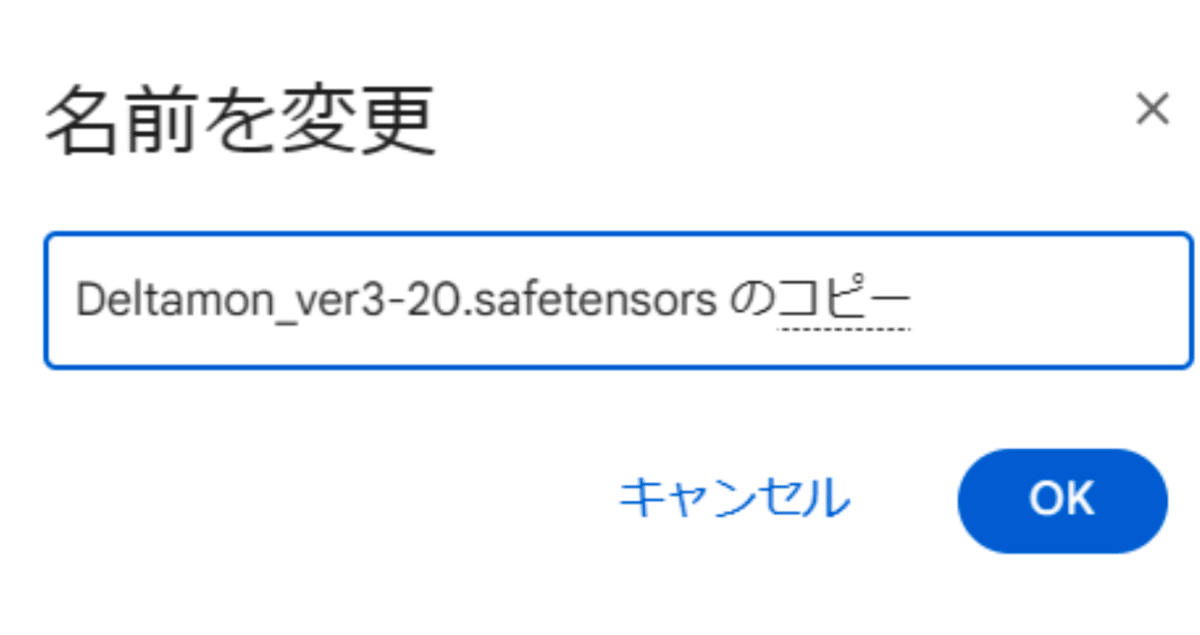
またドライブ内でファイルを移動する際、ファイル名に「のコピー」がついていると Stable Diffusion に認識されません。「のコピー」を削除して使用しましょう。
生成してみよう!
では、今回制作したデルタもんLoRAで画像を生成しましょう!
推奨モデルは AnyLoRA ( https://civitai.com/models/23900/anylora-checkpoint )です。ライセンスはこちら→(CreativeML Open RAIL-MAddendum)
作例
プロンプト
masterpiece, best quality, ultra detailed, full body,
1girl, ,yellow triangle tie, blue one piece dress, green short hair, cat ears, cat tail,smile,flat chest,<lora:Deltamon:0.75>
white background,
ネガティブプロンプト
worst quality, low quality, bad anatomy, big chest, chest, NSFW

デルタもんが生成できました。ネクタイの三角やランドセル等も綺麗に再現されていますね!
また、プロンプトに「Chibi」を追加するとミニキャラを生成することができます。


かわいいミニキャラが生成できました。
以上、Coogle Colab を使って LoRA 学習を行い、自分の LoRA を制作する方法でした。
AICU ではこのような画像生成ワークショップを開催しているので、AICU の TECH PLAY をフォローして次回のワークショップ情報をお待ちください!https://techplay.jp/community/AICU
また、画像生成AIを使って作品を作りたい!というクリエイター向けのマガジン「AICU マガジン5月号 次世代まんが制作特集!」もぜひ手に取ってみてください!
今回のワークショップの教科書はこちら
書籍「画像生成AI Stable Diffusion スタートガイド」https://j.aicu.ai/SBXL
ワークショップに参加した皆さまのご感想はこちら
最後まで読んでいただきありがとうございました 【特報】「ComfyUIマスタープラン」購読の皆様向けに無償テスターコードを配布します。興味のある方はぜひどうぞ!
