
BQML で施策効果測定しちゃダメ🙅♀️

タイトルが釣りっぽくてすみません🎣 でも事態は重大です。
普通に使ってるとロジスティック回帰等で正しい数値を推定できません(符号の正確さも保証されません(!))
精密に言えば、BQML で効果測定するなら、 `MAX_ITERATIONS` を充分大きくして、絶対に `EARLY_STOP` は FALSE にしてください!!!!!!!
できれば、`MAX_ITERATIONS = 40` の場合の係数と `MAX_ITERATIONS = 49` の場合の係数を比較するなど、ちゃんと係数の学習が収束してるか確認しましょう。
ほんとに超絶大事な意思決定の場面ではBQMLを利用せず統計ライブラリを利用しましょう。
なにか間違いがあったら教えて下さい!!!!!
あとは読まなくていいです。詳細を知りたい人だけ!
Acknowledgement
この発見は、株式会社アトラエのインターンメンバーである小池元さん†の仕事です。ほんとうにありがとう!!!!!
† 東京工業大学 情報理工学院 数理・計算科学系 博士課程3年
(わたしの contribution は、以下の toy model とその厳密解の提案・調査協力です。早く伝えるべきと思い、書くのが早いわたしが書きました)
なぜか?
上記の設定をしない場合、BQML による係数の推定値が正しくないからです。
その理由は `MAX_ITERATIONS` と `EARLY_STOP` の指定にあります。
その背景には、BQML は ML であるという設計思想があります(と思います)
以下、これを解説していきます!
具体例を見てみる

このデータをつかって、xを説明変数とし、y = 1 であるかどうかを予測する logistic regression のモデルを作ってみます。
y = 1 である確率を $${\displaystyle \sigma (x) = \frac{1}{1 + e^{-ax + b}}}$$ として logistic regression を行うと、尤度が最大になるのは $${a = \log 3 \fallingdotseq 1.09861, b = 0}$$ だと計算できます。(正規化はナシの場合)
BQML のデフォルトに近い設定でこの係数を推定すると、以下の通りの結果が得られ、値がずれていることが分かります。
CREATE OR REPLACE MODEL
`project.dataset.model` OPTIONS ( INPUT_LABEL_COLS = ['y'],
MODEL_TYPE = 'logistic_reg',
DATA_SPLIT_METHOD = 'no_split',
L1_REG = 0, # 正則化はなしで検証
L2_REG = 0,) AS # 正則化はなしで検証
...... # 以下、ダミーデータを作成して渡す query
`MAX_ITERATION` と `EARLY_STOP = FALSE` を設定した場合
明示的に `MAX_ITERATION = 20` と `EARLY_STOP = FALSE` を指定した場合の結果が以下です。
確かに、正しい係数を推定できていますね。
CREATE OR REPLACE MODEL
`project.dataset.model` OPTIONS ( INPUT_LABEL_COLS = ['y'],
MODEL_TYPE = 'logistic_reg',
DATA_SPLIT_METHOD = 'no_split',
MAX_ITERATION = 20, # この行で MAX_ITERATION を指定(デフォルトと同じ)
L1_REG = 0,
L2_REG = 0,
EARLY_STOP = FALSE ) AS # この行で early_stop を指定
...... # 以下、ダミーデータを作成して渡す query
悲惨な例(実用的な例)
今回は、とある施策の効果測定のため、100変数くらいある logistic 回帰モデルを回してみました。その一部の係数を以下の画像に示します。
statsmodels の方の推定値が正しいと信じた場合、
BQML では MAX_ITERATION を最大の 49 に設定しても正しい推定値を算出できませんでした(※)。

特に var_3 は悲惨で、デフォルト設定(一番左)と正しい推定値(一番右)では符号が反転しています。これが split test のグループ分けの変数の場合、判断が逆転するのでかなり悲惨です。(当然、p値もアテになりません)
一応、learning rate を調整したら良くなるのだとは思いますが、そんなことやりたくないよー😇
※ 鋭い人は見て気づくかも知れませんが、var_1 ~ 3 は one-hot encoding された変数で、どれかが1になるデータの割合が結構多いです。なので推定値の推移がこうなっています。
VIF は5程度なので、多重共線性と言うほどではないですが、そういうデータについての場合の話と理解いただけると良いと思います。
現実的な方針
というわけで、以下の方針で BQML を利用するのが良いと思います
(下に行くほど慎重で、大事な意思決定に利用可能)
あんま気にせずデフォルトの BQML でいく(ワタシ的非推奨)
`MAX_ITERATION` を大きめに設定し、`EARLY_STOP = False` も指定しておく
`MAX_ITERATION = 40` の結果と `MAX_ITERATION = 49` の結果を比較するなど、係数の学習が収束しているか確認する
BQML 以外でやる
BQML と統計ライブラリの思想の違い
BQML のこの挙動の背景には、BQML が ML であるという設計思想にあると思います。
最初の簡単な例での loss curve はこんな感じです。
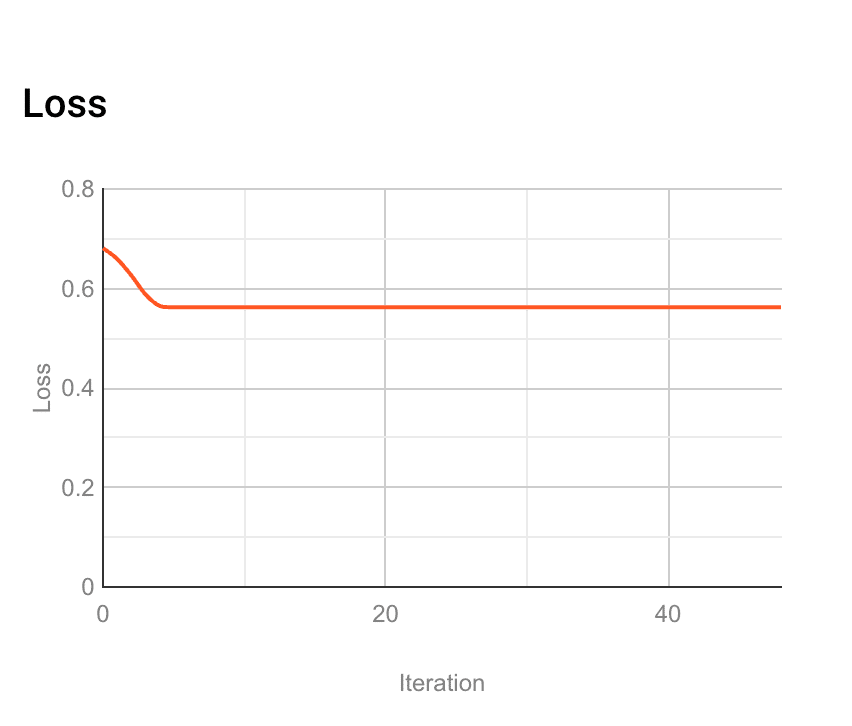
素早く loss が下がりきっており、学習後半では loss が全く減っていません。
そりゃ、ML (機械学習)をやりたいのだったら、最初の数回で iteration 打ち切りますよね。
現実的な例での loss curve も以下の通り同様です。

Loss が減らないということは、機械学習モデルとしての予測精度が変わらないことを意味します(※1)。なので、これ以上計算資源を投入して係数の update をしても意味がありません。そのため、BQMLでは係数が不偏推定量に近づいていなくとも、早めに計算が打ち切られてしまうのです。
一方、statsmodels 等の統計ライブラリは不偏推定量(※2)の計算を目指しています。なので、正しい値に収束するまで計算が実行されるのです。
この思想の違いは学習法にも現れています。
BQML では勾配降下で係数が学習されています。これは、予測精度の向上には充分ですが、不偏推定量の計算に用いるには収束が遅すぎます(1次収
束)。
(※2024/06/21 時点では、ロジスティック回帰分析に対しては、勾配降下(`"BATCH_GRADIENT_DESCENT"`)のみが選択可能です。)
statsmodels の場合、デフォルトなら Netwon-Raphson 法(2次収束)が用いられているので、同じような iteration 回数でもちゃんと不偏推定量に収束するのです。

議論の本筋に影響を与えない補足
※1 ほんとは loss が下がったあとも学習続けたらいいことあったりします。LLM とか大規模モデルでは特にそうです。
※2 厳密に言えば、logistic regression で最尤推定をやっている場合、漸近不偏推定量とかになるのかな。