
LeapfusionからHunyuan Image-to-Videoがリリース ComfyUIで使う方法

動画生成AIのhow to記事です。
公式のi2vモデルではありませんが、Leapfusionという企業からHunyuan Videoのi2vモデルがリリースされました。
今回はこれについて紹介します。
Leapfusion Hunyuan Image-to-Videoとは?
Hunyuan Videoを元にLeapfusionという企業が開発したi2vモデルです。
リポジトリをクローンしてモデルをセットすればコマンドイランで動かせます。
ComfyUI用のワークフローが追加されているので、動かすだけならそっちの方が簡単かもです。
https://github.com/AeroScripts/leapfusion-hunyuan-image2video.git
ComfyUIで使う方法
ComfyUIをアップデート
いつも通り何らかのアップデートやバグ修正などが行われている可能性があるため、アップデートしておきます。
ComfyUI-Manager入れてる方は右上のManager→update allでカスタムノードとComfyUI本体をアップデートできます。
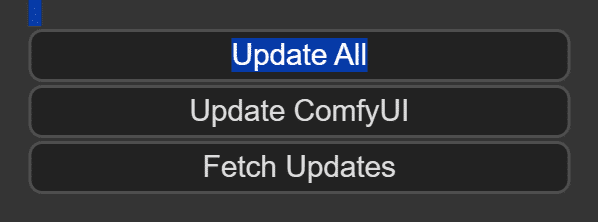
手動の場合はupdateフォルダにある「update_comfyui_and_python_dependencies.bat」を実行して、カスタムノードはgit pullなどで更新してください。
モデルとworkflowの準備
Hunyuan Image-to-Videoは元のt2vモデルやvaeだと動かない?ようです。
そのため、対応しているモデルを別途用意する必要があります。
・モデル(mp_rank_00_model_states.pt)
・パス
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\diffusion_models・LoRA(img2vid.safetensors)
・パス
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\loras・VAE(pytorch_model.pt)
パス
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\vae・LLMとCLIP
これは通常のHunyuanVideoと同じものです。
もしかしたら実行時に自動でダウンロードされるかもしれません。
手動の場合はリポジトリを指定のフォルダにクローンします。
・LLM
・パス
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\LLM・CLIP
・パス
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\clip・workflow
workflowの取り込みと設定
あとはworkflowを取り込み、上で用意したモデルをそれぞれのノードで指定します。
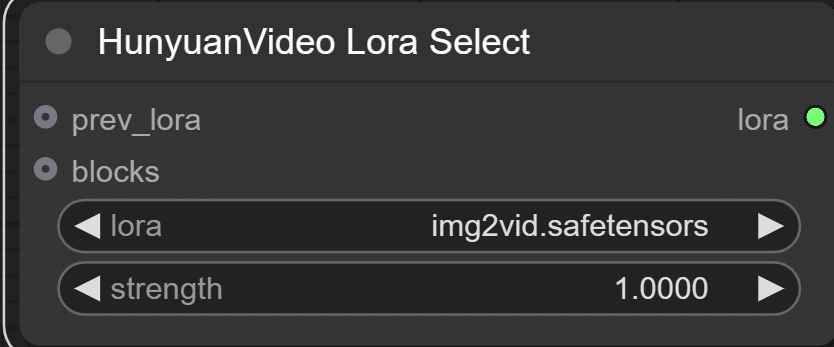
HunyuanVideo Lora Select
ここはLoRA(img2vid.safetensors)を指定します。
Load Image
動かしたい画像を指定します。

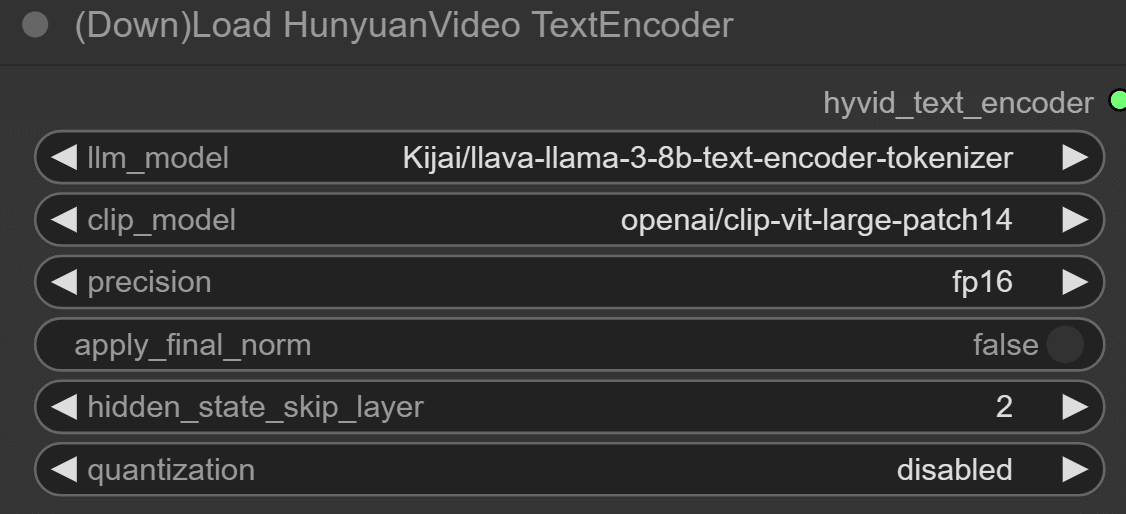
(Down)Load HunyuanVideo TextEncoder
LLMとCLIPモデルを指定します。
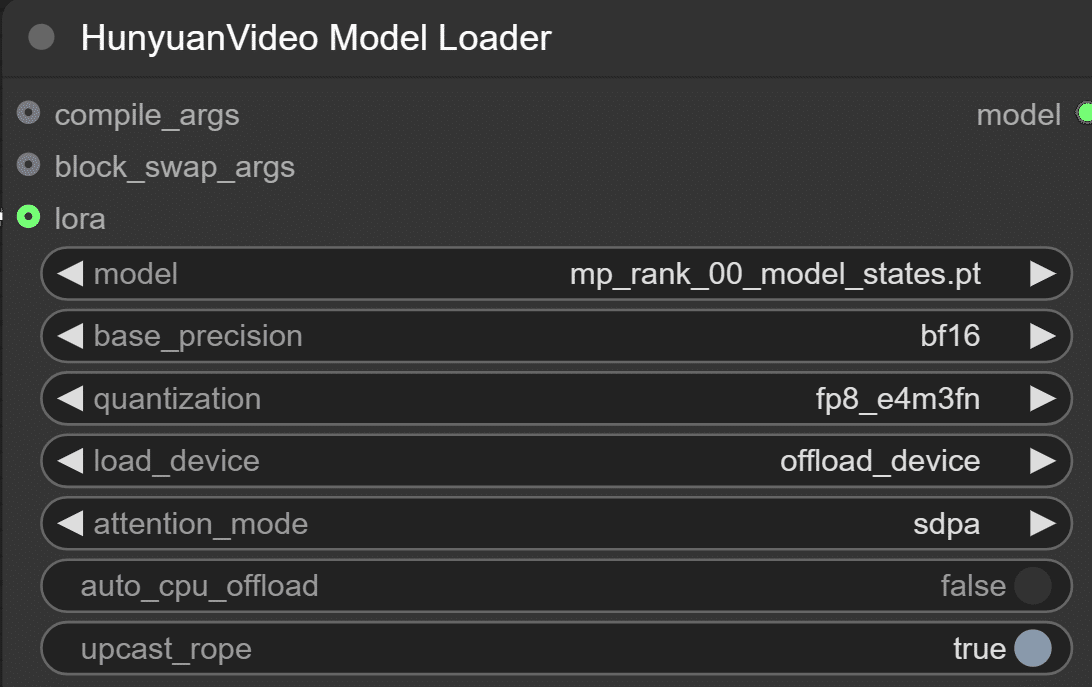
HunyuanVideo Model Loader
モデル(mp_rank_00_model_states.pt)を指定します。
HunyuanVideo TextEncode
画像からどういう動画を生成したいかプロンプトを入力します。
最後に処理後の動画を載せますがプロンプトなしだとよくわからない出力になったため、ちゃんと入れた方がいいかもです。
HunyuanVideo Sampler
動画の長さなどを指定できます。
OOMエラーは出ませんでしたが、デフォルトの129フレームだとRTX4060(VRAM16GB+RAM32GB)で二時間くらいかかりました。
なので最初は短くして出力確認してから徐々に伸ばした方がいいかもしれません。
あとschedulerで結果が変わるというレビューもありました。
RedditではSDE~にすると良好だったという方がいるようです。

実行
これで実行すると動画生成が始まります。
デフォルトかつプロンプトなしで処理すると動画とは言えないものになってしまいました。
デフォルトのままだと何が何だかわからない pic.twitter.com/rvfFO8ZqEV
— AI愛create (@aiaicreate) January 26, 2025
処理が長いのでガッツリフレーム数下げてますが、schedulerをSDEにしてプロンプトを入れたら犬は動きました。
プロンプト入れるとちょっとマシになる pic.twitter.com/gJc6pCG1K8
— AI愛create (@aiaicreate) January 26, 2025
正直少し実用性は低い気がします。
redditでも賛否両論な感じで、公式からのモデルが期待されているようでした。
処理が長くてもちゃんと出力されたことを考えると以前紹介したNvidia Cosmosの方がいいかもしれません。
ただLTXなどを組み合わせて高クオリティな動画を作っている方もいるので、やり方次第な部分もあります。
このくらいのクオリティがローカルでも作れれば、有料動画生成ツールを使わなくても済むかもしれません。
以上Leapfusion Hunyuan Image-to-Videoについてご紹介しました。
当サークルではこのようなAIに関するさまざまな情報を発信しています。
メンバーシップに加入して頂くと一部の有料記事は読み放題です。
AI技術の向上、マネタイズ方法などに興味がある方は、ぜひご検討ください。
もしこの記事が少しでも役に立った場合は、いいねやフォローして頂けると励みになります。
最後まで読んでいただき、ありがとうございました。
いいなと思ったら応援しよう!
