
HunyuanVideoをComfyUIで動かしてみる

動画生成のhow to記事です。
最新の動画生成モデルHunyuanVideoをComfyUIで動かす方法について解説します。
■プロフィール
自サークル「AI愛create」でAIコンテンツの販売・生成をしています。
クラウドソーシングなどで個人や他サークル様からの生成依頼を多数受注。
実際に生成した画像や経験したお仕事から有益となる情報を発信しています。
詳細はこちら(🔞コンテンツが含まれます)
➡️lit.link
HunyuanVideoとは?
HunyuanVideoは、文章での指示やキーワードから新たな動画を自動的に作り出す、最先端のAI技術を用いた動画生成システムです。
例えば「花が咲く様子をゆっくり映した動画」や「街角の夕暮れ風景」というような簡単な文章を与えると、それをヒントに動画を生成できます。
以前紹介したLTXVideoよりクオリティが高いようで、既にComfyUI用のノードもリリースされています。
HunyuanVideo
https://github.com/Tencent/HunyuanVideo
※動作環境
RTX4060Ti(VRAM16GB)で動かしたところ、通常のworkflowだとOOMで実行できませんでした。
lowvram用のworkflowなら動きますが、すれなりにスペックは求められるかも知れません。
ComfyUIをまだインストールしていない方はこちらの記事を参考にしてください。
HunyuanVideoの事前準備
ComfyUI-HunyuanVideoWrapperのクローン
どこでもいいので右クリックなどからターミナルを開いてカスタムノードのパスに移動します。
cd C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\custom_nodesComfyUI-HunyuanVideoWrapperをクローンします。
git clone https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.gitComfyUIのアップデート
基本的に新しい技術やノードなどが公開されたとき、最新の状態にしておくことが推奨されます。
新機能・新ノードへの対応やバグ修正などが行われている可能性があるからです。
ComfyUI-ManagerをインストールしていればManager→Update Allで本体とカスタムノードどちらもアップデートできます。

手動だと「update_comfyui_and_python_dependencies.bat」を実行して、カスタムノードは1つ1つgit pullでやる必要があります。
なので基本はComfyUI-Managerのアップデートを推奨します。
モデルの準備
・diffusion_models
以下のリンクからどちらかをダウンロードします。
hunyuan_video_720_cfgdistill_bf16.safetensors
hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors
データは以下のパスに置いてください。
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\diffusion_models・VAE
VAEも同じリンクからダウンロードできます。
hunyuan_video_vae_bf16.safetensors
hunyuan_video_vae_fp32.safetensors
どちらかをダウンロードして以下のパスに置いてください。
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\vae・LLM&CLIP text encoder
これらは初回実行時に自動でダウンロードされます。
一応以下のリンクから事前ダウンロードも可能です。
・LLM
以下のパスにクローンします。
LLMフォルダがない場合は作成しておいてください。
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\LLMgit lfs install
git clone https://huggingface.co/Kijai/llava-llama-3-8b-text-encoder-tokenizer・CLIP
以下のパスにクローンします。
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\clipgit clone https://huggingface.co/openai/clip-vit-large-patch14t2vの使い方
カスタムノードのフォルダにworkflowがあるのでD&Dで取り込みます。
一般的なt2vはhyvideo_t2v_example_01.jsonです。
VRAM足りない人はhyvideo_lowvram_blockswap_test.jsonで試してみてください。
hyvideo_lowvram_blockswap_test.json
hyvideo_t2v_example_01.json
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-HunyuanVideoWrapper\examples次にノードの設定をしていきます。
・HunyuanVideo VAE Loader
VAEフォルダに置いたファイルを指定します。

・HunyuanVideo Model Loader
diffusion_modelsに置いたファイルを指定します。

・HunyuanVideo TextEncode
生成したい動画のプロンプトを入力します。とりあえず動かしたい人はそのままでも問題ありません。

・実行
デフォルトのままで良ければこのまま実行すれば問題なく動画が生成できます。
HunyuanVideoテスト pic.twitter.com/wBdPvJyUPa
— AI愛create (@aiaicreate) December 6, 2024
v2v
v2vも同じt2vと同じフォルダにworkflowがあります。
hyvideo_v2v_example_01.json
C:\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-HunyuanVideoWrapper\examplesD&Dでworkflowを取り込んでください。
もし赤くて使えないノードがあったらManager→Install Missing Custom Nodesで表示されているもののインストールが必要です。
またモデルやVAEの指定はt2vと同じです。
次にLoad Videoで元となる動画をセットします。
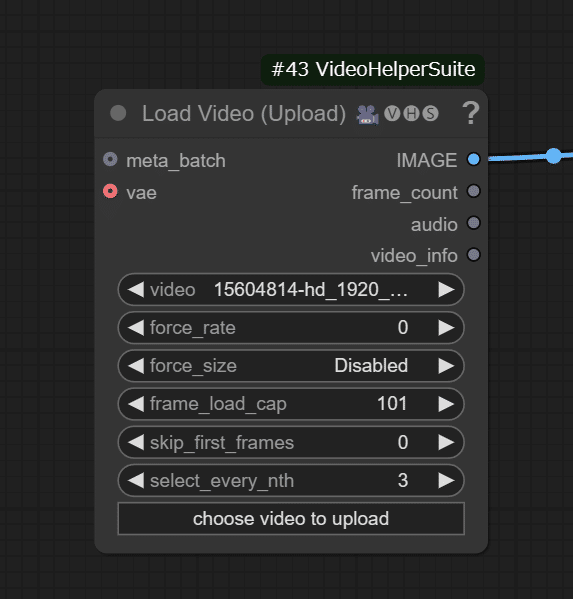
HunyuanVideo TextEncodeで変化を与えたいプロンプトを入力します。

私の環境だと実行できなかったので公式の紹介になりますが、デフォルトだと車がクマに変換されています。
・通常の動画
https://www.pexels.com/video/a-4x4-vehicle-speeding-on-a-dirt-road-during-a-competition-15604814/
・処理後の動画
Thank you once again, dear Kijai. https://t.co/kDFIRuJwq6@xodroc made a very good example. Have you made any interesting videos through hunyuanvideo? @ me! pic.twitter.com/Z9mL1K9sbn
— Hunyuan (@TXhunyuan) December 5, 2024
あとは生成したい内容に合わせてパラメータやプロンプトを変えれば、自分の好きな動画を生成することができます。
以上ComfyUIでHunyuanVideoを使う方法について解説しました。
当サークルではこのようなAIに関するさまざまな情報を発信しています。
メンバーシップに加入して頂くと一部の有料記事は読み放題です。
AI技術の向上、マネタイズ方法などに興味がある方は、ぜひご検討ください。
もしこの記事が少しでも役に立った場合は、いいねやフォローして頂けると励みになります。
最後まで読んでいただき、ありがとうございました。
いいなと思ったら応援しよう!
