
Stable Diffusionで高クオリティ―動画生成、zeroscope_v2の使い方

zeroscope_v2とは?
Stable diffusionの動画生成のzeroscope v2での動画クオリティーがすごいと話題になっています。
zeroscope XLは、ModelScopeベースのstable diffusionの拡張機能で、
ModelScopeがtext2videoで動画生成できるのに対し、その生成した動画をvid2vidで高画質にアップスケールして、映像を修正します。
New open source text to video AI model
— AK (@_akhaliq) June 24, 2023
576x320 model: https://t.co/fhN2cw2tOn
1024x576: https://t.co/OK7IutR1tF
zeroscope_v2_576w, A watermark-free Modelscope-based video model optimized for producing high-quality 16:9 compositions and a smooth video output. This model was… pic.twitter.com/2w6eYBtUUD
こんな感じの動画が作れます。
zeroscope_v2 XL, A watermark-free Modelscope-based video model capable of generating high quality video at 1024 x 576
— AK (@_akhaliq) June 24, 2023
Model on @huggingface : https://t.co/OK7IutQtE7
This model was trained with offset noise using 9,923 clips and 29,769 tagged frames at 24 frames, 1024x576… pic.twitter.com/K2jJS9N9KB
動画見てみてください。
例に出ている動画のクオリティーは確かにすごく高いです。
zeroscope_v2 XLの設定
stable diffusionのwebuiが必要です。
ここではwebuiの初期設定は省くので、持ってる前提で進めますが、
例えば↓とかにインストール方法が載っています。
webuiを起動したら、
まず、Modelscopeの拡張機能をstablediffusionにインストールします。
https://github.com/deforum-art/sd-webui-modelscope-text2video.gitこのURLをExtensionsの欄のURLに入れてインストールをクリック

installedのタブに移動すると、
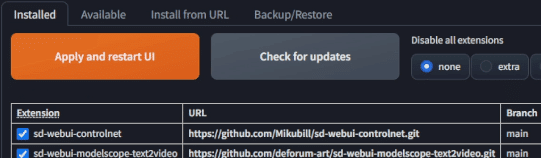
インストールされているのが確認できる。
次に、
このURL上から
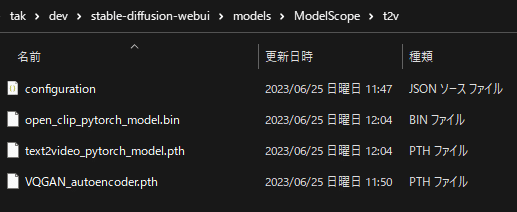
configuration.json
VQGAN_autoencoder.pth
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
の4つのファイルをダウンロードして、
models/ModelScope/t2vに保存してください。
「ModelScope」「t2v」のディレクトリも自分で作成しましょう。
webuiを再起動すると
txt2videoのタブがあるので、

何か適当にプロンプトを書き、
「Generate」ボタンをクリックすると、コンソールでしばらく待つと、txt2videoの初期処理のためにしばらく待ちます。
その後、
「Click here after the generation to show the video」を押すと動画を作れるようになっています。
ここまでで通常の動画生成はできるようになります。
試してみるとクオリティーが低いのが分かると思います。
zeroscopeを使うと高クオリティ―化します。
次にやっと、zeroscopeの動画生成に入ります。
使い方はmodelscopeとほぼ同じで簡単です。
このURLから、
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
この2つのファイルをまずダウンロードします。
models/ModelScope/t2vにその2つのファイルを移動させて、
元あった
open_clip_pytorch_model.bin
text2video_pytorch_model.pth
を置き換えてください。
これで準備完了です。
zeroscope_v2 XLの使い方
プロンプトのところに、作りたい動画の内容を英語で書いて

アスペクト比をwidth/heightで設定してください。
frameも大きくするとなめらかな動画になります。
推奨は、1024x576のようです。
GPUのサイズがある程度必要です。
設定できたら、オレンジのGenerateボタンを押せばしばらく待つと、
コンソールでdoneと書かれるので、
doneとなったら、
Click here after the generation to show the videoをクリックすると動画が作られます。
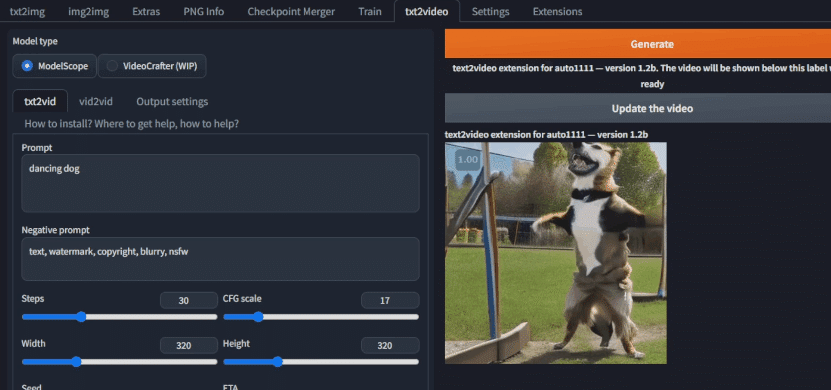
動画できたら、動画をダウンロードしてください。
次にタブを移動して、vid2vidのタブに移動します。
先ほどダウンロードした動画をドラッグアンドドロップで追加しましょう。
ここで、ダウンロードされたファイル名に日本語が入っているとエラーが出るので、ファイル名を英語にしておいてください。
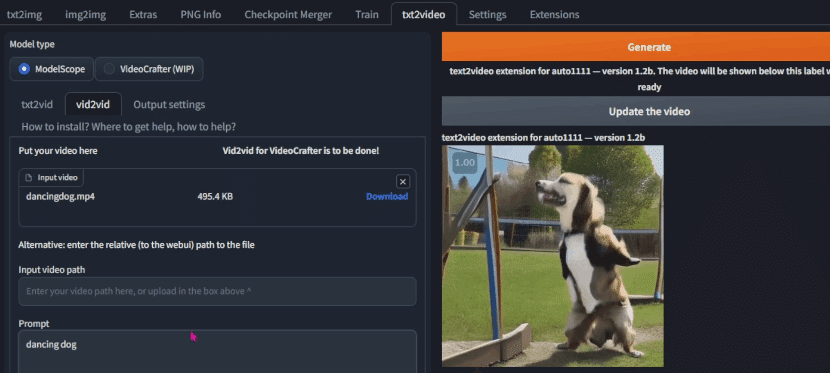
ここで、先ほどと同じ設定をして、
プロンプトとアスペクト比など同じにすること
また、denoising strengthはノイズ除去の強度らしいですが、
0.66 ~ 0.85が良いようです。
再度、Generateを押し、しばらく待つとコンソールでdoneと表示されるので、
Click here after the generation to show the videoをクリックすると動画が作られます。
現在、低解像度または 24 フレーム未満でレンダリングすると、出力が最適化されないイシューがあるようです。
なので、ある程度のGPUパワーがないと使えないです。推奨高解像度でやるならVRAM12GB以上は最低でも必要そうです。
公式情報だと、1024x576 で 30 フレームをレンダリングするときに 15.3gb の vramいるそうです。
text2video、video2videoの動画生成技術も随分向上しているようです。
Twitterも是非フォローお願いします。
noteのメンバーシップでほぼ毎日AIのニュース配信もしています。
この記事が気に入ったらチップで応援してみませんか?