
img2imgとその他全部盛りのツールをローカルで動かそう[StableDiffusion]

2022/09/28追記。現在は色々アプデされて内容が結構変わってしまったので他の導入記事を参考にすることをオススメします。
こんにちは。前回StableDiffusionの単独動作版アプリを紹介しましたが、今回は、画像をベースに画像を生成するimg2img、テキストから生成するtext2img、顔補正、画像拡大など、全部盛りのローカル動作版ツールを紹介します。インストールは前回ほど楽ではありませんが、基本的にクリックして待ってるだけなのでまぁ。
必要になるもの
・VRAM5GB以上のNVIDIA製グラボ
・StableDiffusion 学習済みモデル v1.4
・Miniconda3
・HDD空き容量 20GB
・待ち時間 15分くらい
インストールの参考にしたこちらの「ULTIMATE GUI RETARD GUIDE」を和訳しながら解説します。(究極GUI知恵遅れ向けガイドってお前…。)
Step1:StableDiffusion学習済みモデルv1.4をhuggingfaceか、”リンク”からダウンロード。「sd-v1-4.ckpt」という4GBのこれがSDの脳味噌そのものです。(※一般公開されてるSDですが、リンクは無断転載ぽいのでここには貼りません。ULTIMATE GUI RETARD GUIDEのstep1辺りを見て下さい。)
Steo2:レポジトリをこちらからダウンロード。今回の全部盛りツールのソースコードです。DLしたらstable-diffusion-mainフォルダを好きなとこに解凍して下さい。そして、先ほどDLしておいた「sd-v1-4.ckpt」を「model.ckpt」に改名して、stable-diffusion-mainの「/models/ldm/stable-diffusion-v1」フォルダ内に入れます。
Steo3:stable-diffusion-main内の「environment.yaml」をテキストエディタか何かで開いて、一行目の「name: ldm」を「name: ldo」に変えます。
Step4:こちらのサイトからMiniconda 3をダウンロードします。AIを動かすプログラム言語をPCに分からせるのに必要なものです。64-bit版か32-bit版かはお使いのPCに合わせて選んで下さい。
Step5:Miniconda 3のインストール。恐らくインストール先はデフォルトから変更しない方がいいです。インストール対象を聞かれたら「all users」。「Register Miniconda as the system Python 3.9」のチェックは外します。
Step6:Miniconda 3のインストールが完了したら、最後にstable-diffusion-main内の「webui.cmd」を実行します。

AI動作環境構築に必要なアレコレをオンラインでせっせとDLしているので10~15分くらいかかります。途中何回か「これ止まってんじゃねーの…?」って思うと思いますがちゃんとインストールしているので待ちましょう。あと途中でpythonをインストールするか聞かれた気がするので、聞かれたらインストールしておいてください。
Running on local URL: http://localhost:7860/ To create a public linkなんとかかんとか…、が表示されたら動作準備完了です。ではこの「http://localhost:7860/」をお使いのネットブラウザのURL欄にコピペしてみましょう。
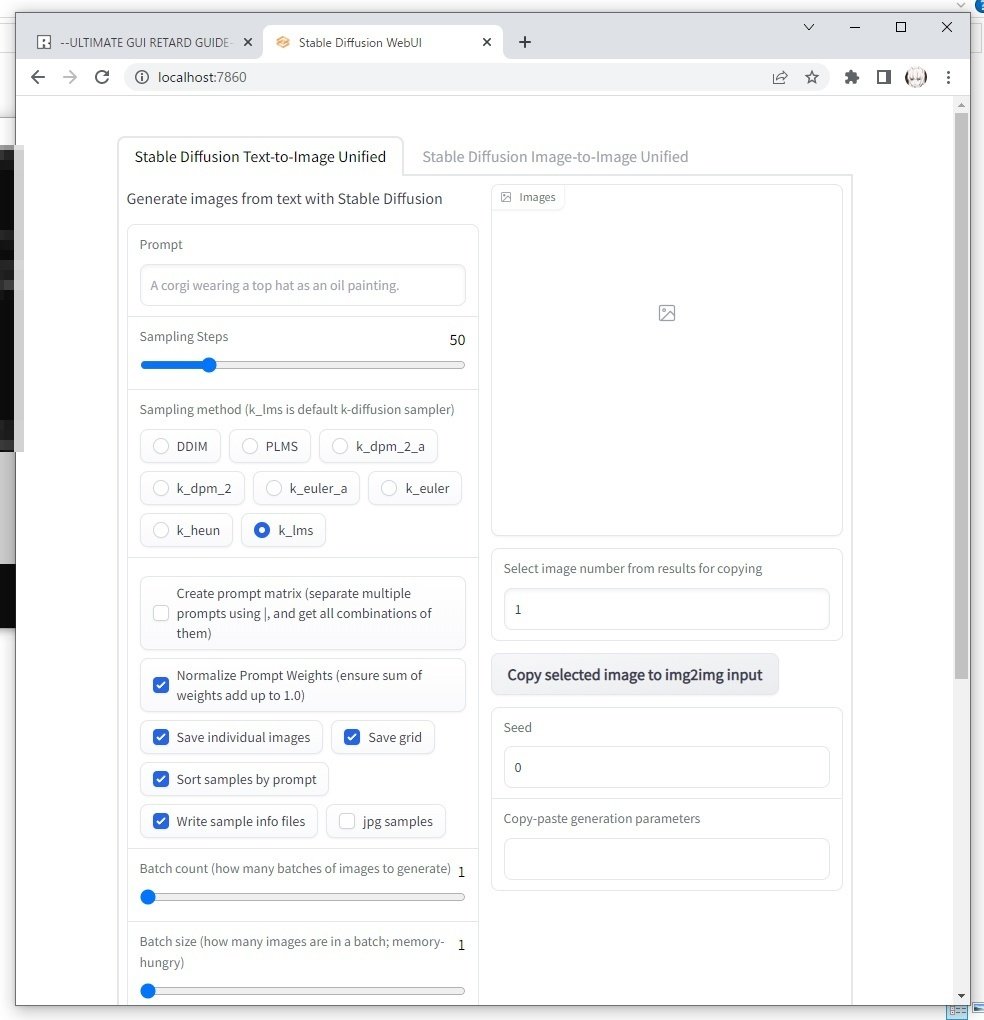
はい、StableDiffusionがローカル動作しましたね。2回目以降も「webui.cmd」を実行して起動しますが、以降は1分くらいで起動します。GPUスペックに応じた解像度上限や設定項目については、前回解説したアプリケーションと基本的に同じなので、そちらを参考にしてみて下さい。
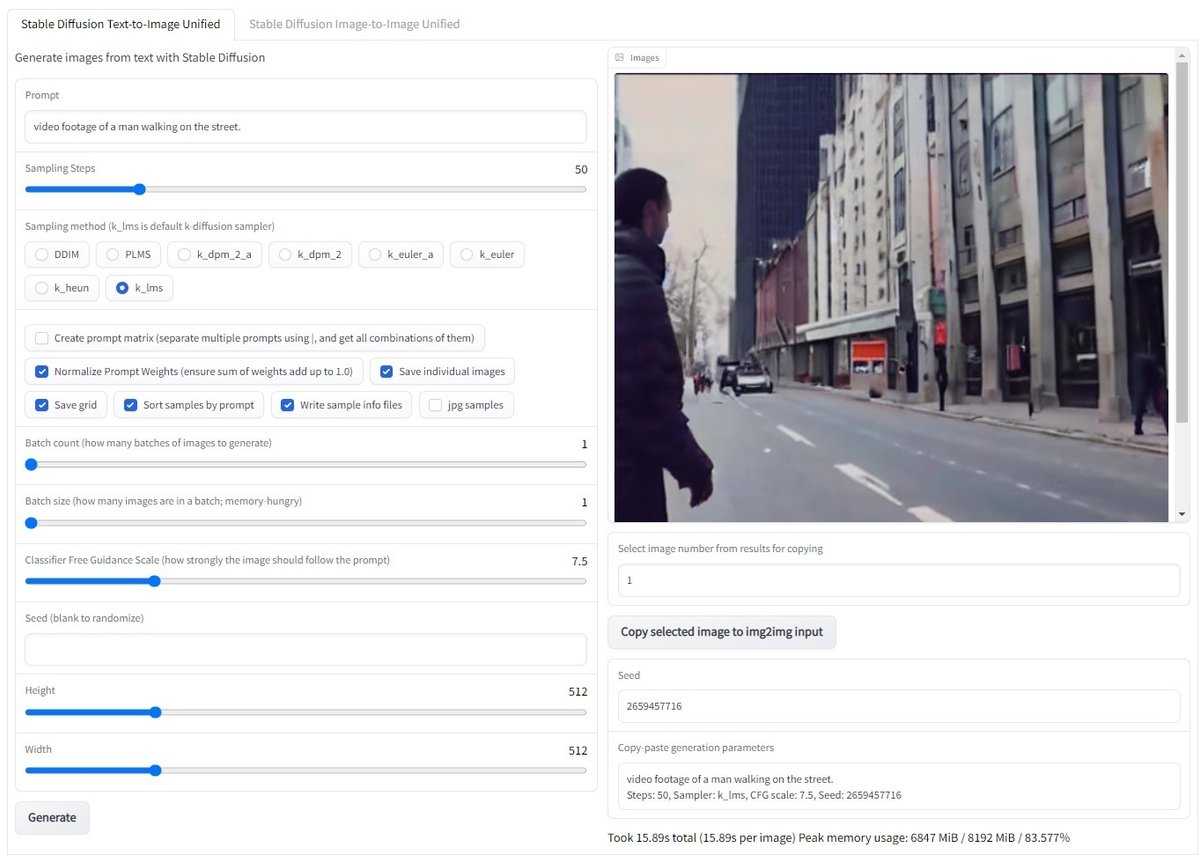
■img2imgを動かしてみよう。
では画像をベースに画像を生成するimg2imgを試してみましょう。画面上部のimage to imageのタブに切り替えて、ベースとなる適当な画像をドラッグ&ドロップして、プロンプトを入力します。

簡単な編集を行えるAdvanced Editer、マスクモードでの必要/不要部分のマスク、ベース画像をズームやトリミングして画像生成するなど、機能や設定項目が色々あって説明しきれないのですが、img2imgで重要なのは下の二つです。
・Classifier Free Guidance Scale:どのくらいプロンプトに従わせるか。低いと表現の多様性が上がるが、勝手なものを生成しがち。
・Denoising Strength:デノイズ強度。高いと元絵からの変化も大きい。逆にあまり変えたくない場合は低くする。
正直これは微調整しながら何回も生成して良い感じの値を見つけるしかないですね。設定できたらGenerateをクリック。

おー、クソみたいな元画像が大幅に変わりましたね。生成された画像はデフォルトではoutputsフォルダに保存されます。
前回も言いましたが、img2imgの優れている点は、text2imgでは指示し辛い構図や色味をAIに的確に分からせることができる点です。生成させたい画像のイメージが固まっている場合は、img2imgを活用するのが正しいアプローチと言えるでしょう。

■顔補正や画像拡大機能
本ソースコードを配布しているgithubのこちらのページの中ほどに、GFPGAN(顔補正)とRealESRGAN(画像拡大)の項目があります。
そこから「GFPGANv1.3.pth」をDLし、stable-diffusion-mainの「/src/gfpgan/experiments/pretrained_models」フォルダに入れます。
「RealESRGAN_x4plus.pth」「RealESRGAN_x4plus_anime_6B.pth」もDLし、同じくstable-diffusion-mainの「/src/realesrgan/experiments/pretrained_models」フォルダに入れて下さい。次回のwebui.cmd実行時にインストール処理がされ、以降UIに顔補正と画像拡大の項目が表示されるようになります。ただこれはオプション機能なので、特に必要無い人はインストールしなくても良さそうですね。
あとgithubにあるUI画面がカッコイイダークトーンなのでバージョンが違うのかちょっと混乱しましたが、単にwindowsがダークモードなだけみたいっす。
■アンインストールについて
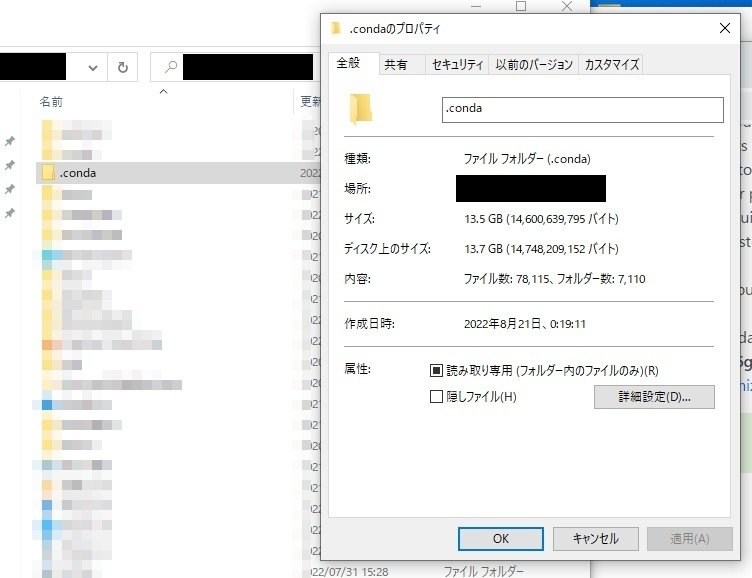
今回クリック一つでインストールしてくれたのは良かったですが、AIを動かす環境構築の為に作られたファイルのサイズは13GB以上で、Cドライブのユーザーフォルダ内にあります。Minicondaをアンインストールしただけではこれらは消えなかったと思いますので、不要になったら手動削除をお忘れなく。
大体そんな感じです。統合型UIは使い易くてありがたいですが、前回紹介したStable Diffusion GRisk GUIもアプデでimg2imgを実装するんじゃないかと思ってるので、インストールや環境構築が面倒臭い場合はそちらを待った方が良いように思いますね。
なんか面倒くせぇ!もっと手軽にimg2imgを試したいぜ!って方はこちらのcolab版か、Artbreaderがimg2img機能を実装したらしく、登録しなくてもデモを触れましたのでどーぞ。

この記事が気に入ったらサポートをしてみませんか?