【論文紹介】NeRFとGaussian Splatting~アルゴリズムの理解編

ボリュームレンダリング界に革命を起こしたNeRF(Neural Radiance Field)とGaussian Splattingについて、論文・アルゴリズムの概要を説明します
細かいところは論文を読めばわかるので、それよりも全体感を大事に説明していきます
実際に手を動かすのは後の投稿にします
これらの技術を理解するには、ボリュームレンダリング方程式とStructure from Motion (SfM)の理解が大事です
概要
NeRFもGaussian Splattingも基本的には、大量のカメラ画像から三次元モデルを形成するStructure from Motionやフォトグラメトリと呼ばれる分野の技術です
三次元モデルの作成・描画に関する技術なので、コンピュータグラフィクス分野、より具体的にはAR・VR分野でしばしば話題に上がります
世間に流通している具体例としてはこんな感じです
Preferred Networks のオフィスの受付を3Dスキャンしました。会社設立10周年を記念していただいた胡蝶蘭も細部までバッチリ再現できています #GaussianSplatting pic.twitter.com/y6RfLfxyZb
— PFN 3D/4D Scan (@pfn_3d) April 11, 2024
(PFNさんのGaussian Splatting)
着想
ボリュームレンダリング方程式
NeRFもGaussian Splattingもボリュームレンダリング方程式に基づいています。ボリュームレンダリング方程式では画像が次のようなプロセスを経て形成されたものと考えます:
カメラに入るまでの過程で、光線群が物体を透過する際に光強度が減少したり(吸収率σ)、放射輝度特性c(r, d)が変化する。
カメラに入る大量の各光線に対して、カメラに入射するときの光強度を計算して足し算すれば三次元物体分布に対して撮像シミュレーションができる。
これを図示するとこんな感じです

実はボクセル群に対して吸収率σと放射輝度特性c(r, d)を定義すればこれだけでもCGをレンダリングできます。ですが、これらを真面目に表現するとものすごくファイル容量もメモリ容量も大きくなってしまいます
同時に、モデリングや描画段階での計算機負荷もかなり大きくなります
言ってしまえば、大きな三次元領域の複数種(吸収率と放射輝度特性)のボクセルデータに対してボリュームレンダリングをするから、こうした課題が出るわけです
この課題に対して次のようなアプローチで、吸収率と放射輝度特性をモデリングしたのが、NeRFとGaussian Splattingです
NeRF: 万能近似器であるニューラルネットワークを使い、関数として吸収率と放射輝度特性をモデリングしよう
表現しなければならない空間が莫大な時にニューラルネットワークを介して表現しなおすのはQ学習以来、広く使われているアイデアともいえますよね
Gaussian Splatting: ぼかした点群の集合体でボクセルデータを軽量化しよう
点群データはボクセルデータと比べて圧倒的に軽量です

NeRF (Neural Radiance Field)
NeRFは「ニューラルネットワークを使って吸収率と放射輝度特性をモデリングしてしまおう」という手法です。
ライトフィールドカメラの提案でも知られるRen Ngらが提案しました
元論文はこれです
詳細は次節で説明しますが、NeRFでは撮影した各画像を再現するように吸収率と放射輝度特性を学習することで三次元モデルを形成します。
提案当時はかなり画期的なアイデアで、NeRFのおかげで複雑な三次元モデルを現実的な計算機&現実的な計算時間で形成できるようになりました。
ちなみにライトフィールドカメラは画像撮影した後に画像処理でフォーカスを調整できるカメラです。
現在主流のRGB+D像を取って、被写体との距離に応じて画像をぼかすのではなく、光強度と一緒に各画素に入射した光線の角度を記録してフォーカシングを調整しています。
NeRF論文も「光線がどのように画像を形成するか?」について理解の深いRen Ngらしい論文だな、とつくづく感じています
https://graphics.stanford.edu/papers/lfcamera/lfcamera-150dpi.pdf
3D Gaussian Splatting
NeRFは数学的にもかなりいい感じなのですが、レンダリングにニューラルネットワークを使っている以上、描画時に何度も推論しなければなりません。ほかにも巨大なモデルを生成するのだと、生成するのに必要なコストが大きくなってしまいます。
Gaussian Splattingでは物体データをとしてボクセル状の3次元データではなく、Gaussianでぼかした点群的な3次元データとして表現します。各点群に吸収率と放射輝度特性の値を持たせれば、点群(のような)データからでもボリュームレンダリング方程式を利用したレンダリングができますよね。
NeRFと比べると、推論時にニューラルネットワークが不要であるため、計算機負荷もかなり軽量になっています。
そうした背景により、Gaussian Splattingがスマートフォンでもレンダリングできる手段として注目されているわけです。
3次元モデルの構成(深層学習器の学習)
NeRF, 3D Gaussian Splattingそれぞれの基本的アイデアを理解できたところで、どのように三次元モデルを構成するかを見ていきます。
Structure from Motion (SfM)
大量のカメラ画像をもとに三次元モデルを構成する技術をフォトグラメトリといいます。Structure from Motionはその中の一連のアルゴリズム群の名称です。
SfMでのモデリングを行うアルゴリズムでは各画像の対応点を取りながらカメラの姿勢推定を行い、モデルを精緻化して…を繰り返します
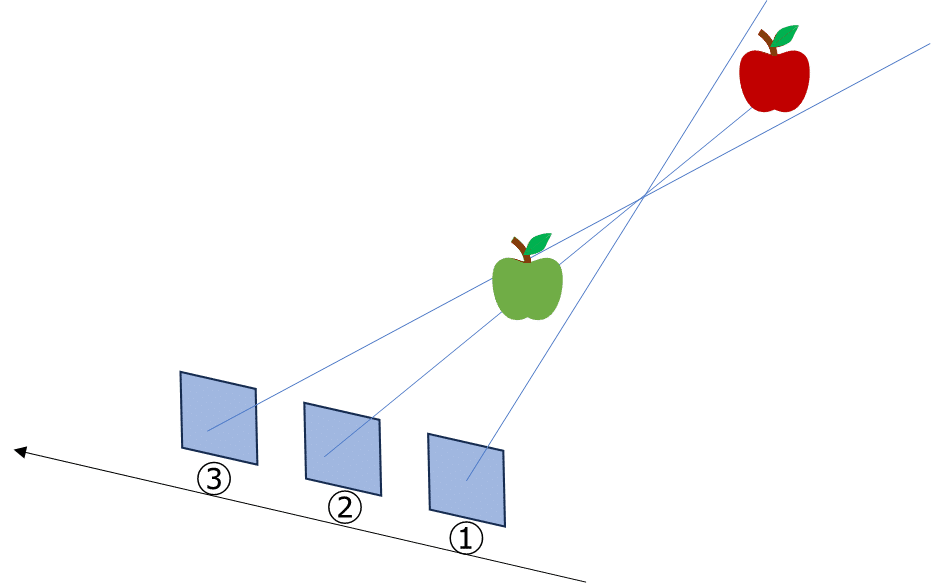
下図を例に挙げて説明します。①→②→③と撮影したとしましょう
青リンゴは左から右に動いているように見える一方で、赤リンゴは右から左に動いているように見えるはずです。
なので、①~③のカメラでの撮影像をもとに、カメラの位置・姿勢情報と物体の位置関係を推定できそうです
結論として、SfMを行うと、
・各入力画像を撮影した時のカメラの姿勢がどのようになっていたか
・被写体の三次元モデル
の二つを推定できます。
SfMを行う代表的なソフトウェアに3DF ZephyrやCOLMAPがあります
NeRFもGaussian SplattingもSfMを前提にしていて、実際に、カメラの姿勢推定まではCOLMAPを使っていたりするわけです
NeRF
SfMで各画像を撮影した時のカメラの姿勢情報がわかりました
あとは、吸収率と放射輝度特性をモデリングできれば、ボリュームレンダリング方程式をもとに3Dモデリングできそうです
NeRFはこのモデリングにニューラルネットワークを使っているのでした
実際には光線をもとに(吸収率、放射輝度特性)を推論するニューラルネットワークを構成し、このニューラルネットワークをもとにレンダリングした画像がカメラでの出力像と矛盾がなくなるように学習を行います
NeRFではそのほかにもモデルのディテイルを再現するための工夫周りもされていてそこもかなり大事なのですが(positional encoding)、いったんこれくらいで説明を切り上げます
Gaussian Splatting
Gaussian Splattingでも同じような発想で学習します
つまり、3Dモデルからカメラで撮影した像をシミュレートし、それとカメラ撮影像の差分が小さくなるように学習を行います
論文図で示されているフレームワークはこのような感じです
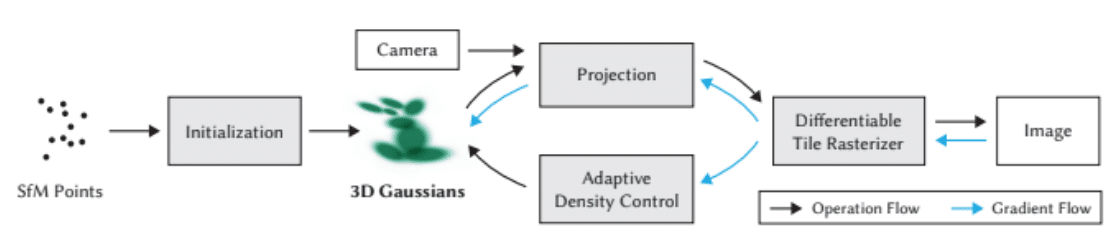
点群は微分不可能ですが(δ関数のようなものですし…)、Gaussianは微分可能ですよね
そして各光線からの画像への寄与も各点群中からの寄与の和なので、撮像シミュレーション像と実際の撮影画像との二乗和誤差が微分可能になります
そのため、Gaussian Splattingはニューラルネットワークを仮定していないものの、勾配法で放射輝度特性などをを学習できるのです
Gaussian Splattingは点群のような性質を持ちますが、点群のモデリングは勾配法だけだとあまりうまくできません
そのため、モデル構成のタイミングで一点だったものを二点に分けたりマージしたりといった処理も入りますが、ざっくりというとこんな感じになっています
まとめ
NeRFもGaussian Splattingも多量の撮影画像から3Dモデルを作る技術だよ
どちらの技術もボリュームレンダリング方程式とStructure from Motionをその基礎においているよ
NeRFは3Dモデルを深層学習器で再現するよ。モデルの再現能力はすごいけど、その代わりに描画のタイミングで推論が必要になってしまうよ
Gaussian Splattingは厳密には深層学習器ではないけど、数理的なトリックでモデル作成に確率的勾配降下法をうまく使っているよ。深層学習器ではないから、かなり軽量に描画ができるよ
すごく簡単な記事でしたが、以上です!!
この記事が気に入ったらサポートをしてみませんか?