【データ分析】構造方程式モデル (Structural Equation Modeling, SEM)

1.1 構造方程式モデルとは?(辞書的な説明)
構造方程式モデル (Structural Equation Modeling, SEM) は、統計モデリングの一種で、因果関係を含む多変量データの分析に用いられています。
SEM は、変数間の関係を方程式で表現することで、応答変数を説明する因子と、それらの因子の関連性を推定します。
相関分析や因子分析だけでは分からない、
観測変数と因果関係同士の相互関係が分かる。
イメージとしては以下のアウトプットで矢印が相互に引かれている。
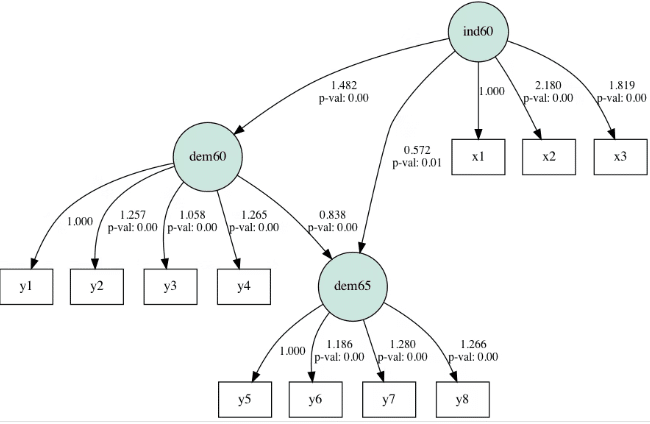
1.2 SEMのキモチ(噛み砕いた説明)
↓引用元
相関関係の背後に何か構造があるんじゃないか?
その”背後”を読み解きに行くのがSEM。
因子分析は全因子が全変数に影響していると見て分析する
また因子同士は無関係で独立していると考える。
SEMは・・
1. 特定の因子から特定のデータへの影響を見れる
2. 因子同士の関係も見れる
3. 相関も見れる

↓具体的に大学受験のテストで置いた場合のパス図

2. 構造方程式モデルのユースケース
以下のような事例で使われている
社会科学: 心理学や社会学などの研究で、因子間の関連性を調べたり、個人差や文脈的要因の影響をモデル化するために使われます。
マーケティング: 顧客行動やブランドイメージなどの調査結果から、顧客志向や購買意欲などを説明する因子を推定するために使われます。
健康科学: 健康行動や生活習慣と健康状態との関連性を分析するために使われます。
経済学: 経済指標や国内生産総額などの調査結果から、国内経済活動を説明する因子を推定するために使われます。
3. SEM の学習ステップは?
統計基礎: SEM の前提となる統計的知識 (多変量解析、回帰分析、確率分布など) を学ぶことから始めます。
論文の読解: SEM の適用例を含む研究論文を読むことで、実際にどのようにモデルが構築され、評価されているかを学ぶことができます。
ソフトウェアの使用: SEM を実際に構築して解析するためのソフトウェア (例: Mplus、LISREL、AMOS) を使用して実践的なスキルを身につけます。
専門書の習得: SEM の方法論や応用例を詳細に説明する専門書を読むことで理解を深めます。
セミナーやワークショップ: SEM のエキスパートによるセミナーやワークショップに参加することで、実践的なアドバイスや解決方法を学ぶことができます。
4. 実装方法
Python で SEM を使うためには以下の手順があります。
Python パッケージのインストール: SEM を実装するために必要な Python パッケージ (例: statsmodels、PySEM、pfnet) をインストールします。
データの準備: SEM の解析に使用するデータを準備します。これには通常の csv ファイル形式や Pandas DataFrame 形式などが使われます。
モデルの構築: Python で実装された SEM ライブラリを使ってモデルを構築します。このステップでは変数の定義や因子間の関係の定義などが行われます。
モデルの解析: 構築したモデルを使ってデータを解析します。このステップでは因子間の関係の推定や信頼区間の推定などが行われます。
結果の可視化: 解析結果を可視化するために Matplotlib、Seaborn、Plotly などの Python パッケージを使ってグラフを作成することができます。
5. 感想
プロダクトの成長戦略を立てるための、
日々の改善行動に有用な分析手法だと思った
なんとなくAを上げればBが上がると思っていても、
その因果関係にある矢印の向きは感覚でしかないし、
1変数で決まるなんてことはあり得ない
それを相互関係で図にしてくれるSEMは出来たら実用的だと思う。
ただ因果分析をスキップして良いのか~とか、
観測対象と因子の結びつきは任意になりそうなので、そこが肝になりそう。