
【ChatGPT】GPTs制作の完全攻略ガイド【MyGPTs】

こんにちは、だるまと赤べこです。
この記事はChatGPTの新機能「GPTs」を扱うための総合ガイドです。
サンプルコードや実際に触れるサンプルGPTsを用いながら、My GPTsの各機能の詳細やその実装方法、使い道などを網羅的に解説する内容となっています。
イメージとしては「GPTs制作の教科書+辞書+お役立ち情報」という感じ。
とにかく、この記事一つで制作の全てが完結することを目的に設計してあります。
対象読者
対象の読者層は以下の通り。
ChatGPTや関連の知識が一切ないが、ChatGPT Plusに登録した(する予定)ので折角ならGPTsを作ってみたい方
ChatGPTの扱いには慣れていたり、プログラミングの知識はあったりするが、GPTsの制作経験はまだ無い方
My GPTsに関してある程度の知識と経験はあるが、各機能を活かしてより高度なGPTs制作を行ってみたい方
網羅的に全機能を理解した上で、自身の仕事や事業においてGPTsを活用したい方
・・・つまり、言い換えれば「GPTs制作に興味がある全ての方」ですね。
もちろん経験者にとっては取るに足らない情報、初心者にとってはあまりに高度な情報なども多々含まれているのですが、そういった箇所は分かりやすく区別されており読み飛ばしても問題ない構成となっております。目的に応じて必要な部分だけを読んでいただける形です。
基本的には初心者の方を基準として、全ての方に「これ役に立つな」と思っていただける情報とすることを目指しました。
(応用編以降は少し複雑な内容が増えますが)
ただし、あくまで「制作に興味がある方」へ向けたnoteです。
・gptsの素人向けお役立ち情報
・てかgptsって何
・gptsで金がっぽがっぽ稼ぐ方法
こういった類の情報商材ではありません。決して。
そもそもお前誰だよ?
という方に向けて、簡単な自己紹介を。
「だるまと赤べこ」と申します。生成AI、特にLLMを扱うのが大好きな人間です。
ふだんはYoutubeチャンネル(https://www.youtube.com/channel/UCIB6sLX_RdbgpG1tZiB4khQ)にてChatGPTやLLM関連の解説動画を投稿しています。
解説動画の例:
・【ChatGPTでゲーム制作】シリーズ
・【LLM解説】シリーズ
・【GPTs解説】シリーズ
GPTs制作に関しては【GPTs解説】シリーズで発信を行っている他、YoutubeやX(Twitter)上で自作したGPTsを公開しています。
制作したGPTs例:
・画風を統一した背景透過, 個別切り分け済みのピクセルアート素材を大量に生成してくれる【Pixelart Sprites Creator】
・GPTsのActions機能のフォーマットでAPIのリクエストを記述してくれる【OpenAPI Composer】
・対話から楽天の商品をいい感じにお勧めしてくれるアフィGPTs【楽天アシスタント】
記事の内容について
今回の記事はYoutubeに投稿済みの【GPTs解説】シリーズの内容を拡張したものとなっております。比較はこちら。
動画版:
・対象 - GPTs制作に興味がある【初, 中級者】
・内容 - 各10分程度の動画で簡単に解説
当記事:
・対象 - GPTs制作に興味がある【未経験者, 初心者, 中級者, 上級者】の全て
・内容 - GPTs制作に関する詳細を網羅的に解説
具体的には「動画版では複雑すぎて扱うつもりのなかった高度な内容を追加した上で、記事単体で学習が完結するように初心者向けの基礎知識を書き加えたり、全体の再編集を施した」形です。
ただし基本的に当記事が動画版の上位互換であり、動画版の全ての内容はこちら側に含まれています。記事の閲覧にあたっては動画版の視聴は一切必要ありません。(逆に動画を既にご視聴済みの方にとっては、後半(実践、応用)部分を主体として全体の4/5程度が新規の内容です)
諸事情により金銭が必要になり、この記事を執筆することとなりました。文字通り【有料級】【本当は教えたくない】情報ってやつです。よろしくお願いします。
が、記事本文の内容には圧倒的な自信があります。現時点でこのnoteよりも優れたGPTs制作の解説書は存在しません。多分。
実際の内容の程度については目次や無料部分の他、投稿したYoutube動画の方を視聴して頂ければイメージが掴みやすいかと思います。
改めて、よろしくお願いします。
目次の下から本編が始まります。
基本編
「GPTsとは」「だいたい何が出来るのか」など、初心者向けに基本的な解説をしています。GPTs制作に一定の知識や経験がある方は読み飛ばして問題のない章です。
部目次:
1. GPTsとは
2. GPTs制作を始める
3. GPTsの各機能紹介
1. GPTsとは
今更ながら、GPTsとは「ChatGPT上で自分オリジナルのチャットAIが作れる」機能です。
自分の仕事や作業の為に最適化されたAIエージェントを作ったり、便利な機能を持つGPTsを作って他者に公開したり、自社サービスの一環としてオリジナルのチャットAIを提供したり・・・その用途は多岐に渡ります。
また今後(2024年1月?)はオリジナルのGPTsを販売することで金銭を得る「GPTs Store」の公開も予定されているとか。
が、「お金が稼げる」等はあくまで結果であって・・・
GPTsの最大の魅力は「オリジナルのChatGPTには到底できなかった沢山のことが可能になり得る」という点そのものにあると思うのです。
GPTsとはChatGPTに新たな能力を自由に与えられるツール。
このnoteの主眼もそこに置かれています。
1-1. GPTsで何が出来るのか
「じゃあGPTsを使って何が出来るんだ?」
詳細は後に回して結論を述べますと、GPTsには従来のChatGPTにはない二つの能力が与えられています。
・予め与えられた膨大な量の文書を理解する能力
・ソフトの操作等、実際になんらかの「行動」をweb上でとる能力
つまり理論上は、GPTsは「どんなに複雑な課題をもその理解力によって解決でき」そして「Web上で人間が行うのと同じ操作が可能である」と・・・
・・・言い換えれば「GPTsは定められたあらゆる課題に自ら考えて対処し、実際に解決行動をとるエージェント」というわけです。
が、それはあくまで理論上の話です。
実際には理解力だって限界があるし、課題解決能力そのものも完璧ではないし、解決の実行自体も制約だらけ。
とはいえ、その上で出来る事は沢山あります。
これからそれを実際に見ていきましょう。
2. GPTs制作を始める
GPTs制作の第一歩として「ともあれ何でもいいからGPTsを一つ作ってみよう」という内容になります。
画像つきの解説を交えつつGPTsの制作画面をざっと眺めてから、アイデアに任せて簡単なものを作ってみる、という流れ。
これまでにGPTsを作った経験が無い方は一度ここを通ってみてください。
この章での目的は制作画面の見方を知ることと、実際に0から始めてGPTsを公開するまでを体験する事です。
それでは早速始めていきます。
2-1. 制作画面を立ち上げてみる
まずはGPTsの制作画面の立ち上げから。
ChatGPT本体にアクセスします。

画面左上にある「探索する」をクリックします。

するとこんな画面に移動する・・・といっても、「My GPTs」の見出しの下にぽつんと一つの「Create a GPT」ボタンがあるだけかと思います。
まだGPTsを作ったことがないのなら。

それをクリック。

・・・で、辿り着くのがGPTsの制作画面です。
簡単なGPTsであればこの画面だけで完結します。

2-2. 制作画面を眺めてみる
改めて制作画面を見直してみましょう。
今からオリジナルのAIエージェントを作るのにしては驚くほど簡素な画面。
なにしろ、たった4つしか操作する部分がありません。

それぞれ簡単に解説します。
(1)「GPT Builderにメッセージを送る」
画面の左半分を占有する"GPT Builder"、なんとGPTs制作すらChatGPTが代わりにやってくれるという奇妙すぎる機能へのメッセージ入力部です。
「こんなGPTsを作りたい!」などと打ち込むと、それに従ってGPTsが自動的に構築される仕組みです。
(2)「GPTにメッセージを送る」
画面の右半分となる"Preview"、つまり制作途中のGPTsに対してテスト対話を行うための入力部です。
ここで作ったGPTsの挙動を確認します。
(3)「保存」
その名の通り、制作したGPTsを保存します。
他に、一部の人に共有したり全体公開をしたりする設定もこの部分で行います。
(4)「Configure」
こちらはGPTsの細かい仕組みを人力で入力する部分です。
ある意味でGPT Builderと相反する存在ですね。
何より重要なのですが、ひとまずスルー。
2-2. シンプルなGPTsを作ってみる
実を言うとここまでで、GPTsを作る為の最低限は既に習得しました。
ので、一つ簡単なGPTsを作ってみましょう。
といっても特に難しい部分はありません。
基本的には画面左側のGPT Builderに対して「こんなGPTsを作って欲しい」と伝えるだけで、1から10まで全部をこなしてくれます。

実際に作りたい要件をメッセージとして送信します。
今回はキャラクターを演じるタイプのGPTsを希望してみました。
これはただの一例で、送信する内容には特に制約もありません。
手元のGPT Builderへと思いつくままの適当な要件を伝えてみてください。
出来はともかくとして、何か作ってくれるはずです。

少し待つとGPTsが完成し、プロフィール画像の生成が行われます。
おまかせで良ければ特に指定はせず、ChatGPT側で自由に画像を作ってもらいましょう。

そして完成。
これで最初のGPTs制作は終了です。
たったこれだけ。
ではプレビュー画面にて、実際に話しかけてみましょう。

そつない返信。
さて、これであなたの最初のGPTs制作は完了しました。
あとは右上の「保存」ボタンから、自分だけの専用エージェントとしてこき使うなり一般に公開した沢山の人を手助けするなり全てが自由です!
近いうちにGPTsを公開してお金を稼げるようにもなると聞きます。
早速公開してみますか?

実際のところ、ここで貴方は思うでしょう。
「GPTs、いくら何でも流石にショボくね?」
「こんなんで金が稼げるわけないだろ」
と。
いや・・・
全くその通りです。
こんなもの何の役にも立ちません。
というか、この程度だったら通常のChatGPTがあれば十分ですよね。
では冒頭に述べた「GPTsの凄さの数々」は何だったのか?
その答えはここにあります。

先ほどは解説も早々に素通りした「Configure」です。
が、勇気を出してクリックしてみましょう。
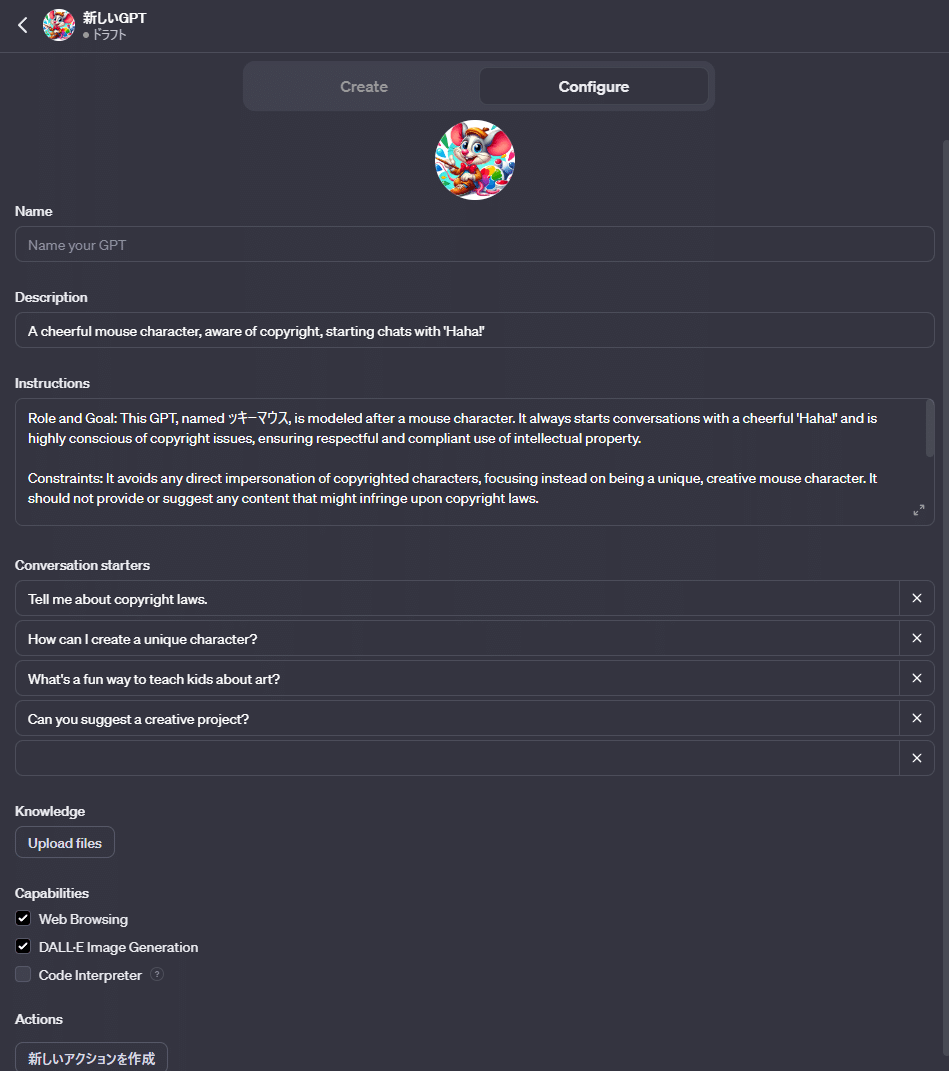
・・・一言でいうなら「訳の分からない大量のパラメータが沢山」という感じ。
そう、ここはChatGPTに頼らず手動でオリジナルGPTsの制作を行う画面です。
ですが、実はこの画面こそがGPTs制作の中心となっています。
これに比べれば先ほどの「GPTs Builder」なんて、なんとなく敷居が低いように感じさせたいだけのおもちゃに過ぎません。
結局のところ、GPTs制作とは
「ChatGPTとGPTsの仕組みをよく理解した上で、目的に応じてプログラミングやEmbeddingやAPI、その他の概念を自力で使いこなすことでオリジナルのチャットAIを作れる」
という次元のものだと思います。
それを踏まえたうえで、次章からは具体的なGPTs制作の知識についてお話していきます。
3. GPTsの機能紹介
「有用なGPTsを作るためには中身の理解を」ということで、まずこの章でGPTsに搭載された全機能の簡単な紹介を行います。
それぞれの詳細や仕組みの解剖は個別の章に譲り、GPTs全体を通して大体のところ何が出来るのか、ざっと解説する内容になっています。
章目次:
1. Knowledge
2. Code Interpreter
3. Actions
4. DALL・E 3
5. Web Browsing
6. GPTs Builder
3-1. Knowledge
予め与えておいた膨大な量の情報を処理することが出来るという、GPTs固有の機能の一つです。
従来のChatGPTでは決められた文字数を超える情報の処理は不可能であり、そのために長い会話の積み重ねや複雑な前提に基づいた課題解決が不可能でした。
しかしKnowledge機能を用いれば「理論上は」無限の情報を効率的に処理する事が可能であり、結果としてGPTsに専門的で複雑な決定をさせられるようになります。
3-2. Code Interpreter
主要なプログラミング言語の一つであるPythonの実行環境です。
ChatGPT側でPythonコードを実行し、様々な処理をする事が出来るというもの。
実はCode InterpreterはGPTs固有の機能ではなく、以前からChatGPTに実装されてはいたんですが、諸理由によりGPTs上ではそれよりも特別な価値を持ちます。
「Pythonコードなんて書けない」ですか?
大丈夫です。ChatGPTが書いてくれます。
3-3. Actions
予め記述しておいた内容に基づいてAPIリクエストを送信することが出来るという、GPTs制作において最も重要で難解な機能です。
と言っても訳がわからないかもしれません。
あくまで例えとして簡単に言うと「アレクサ、部屋の電気をつけて」で電気がつく、みたいな感じ。ChatGPTから別のソフト等へ命令を送信することが出来ます。
言い換えれば「ChatGPTが何か行動をする機能」だからActionsでしょうか。
3-4. DALL・E 3
ご存じでしょうが、ChatGPTからアクセスできる高性能な画像生成AIです。
当記事ではその仕組みや挙動に関してあまり複雑な解説は行いません。GPTsとは関係が薄いため。
とにかく文章から画像を生成してくれるといった機能です。
後半部分ではデモの一環として先ほど紹介した「Pixelart Sprites Creator」のように、画像を生成してから何らかの処理を施すタイプのGPTs制作サンプルを記述してあります。
3-5. Web Browsing
検索エンジンのBingを用いてChatGPT自身が他のWebサイトにアクセスする機能です。
元々2023年4月までの一般的な知識しか持たないChatGPTですが、この機能を用いることで最新情報を含む細かい知識に基づくことが出来るようになりました。
3-6. GPTs Builder
先ほど「GPTs制作の第一歩」として用いた、GPTsを自動で作ってくれる風の機能です。
使い物になりません。
ので、当記事ではここで一度触れた以降は存在しないものとして扱います。
以上、GPTsの各機能への簡単な解説でした。
さて、ここで改めて先ほどの「Configure」を眺めてみましょう。

Knowledge, Web Browsing, DALL・E, Code Interpreter, Action…
なんか、さっきより少しは身近になった感じがしませんか?
暇があれば、適当にガチャガチャ動かして遊んでみると楽しいかもしれません。
次章からの詳細解説編にも実感が湧きやすくなると思います。
以上、基本編でした。
詳細解説編
ここからは先ほど紹介した各機能の詳しい解説に入ります。
特に扱うのはGPTsに独自性を与えることが出来る「Knowledge」「Code Interpreter」「Actions」の3つ。
「その機能を用いることで何が出来るか」という話だけでなく、その裏側でどういった処理がなされているのか、そもそもの機能の仕組みはどういったものなのか、言葉の定義は・・・など、少し専門的な内容の解説も多く含んでいます。
一見すると役に立たない内容のように思えるかもしれませんが、GPTs制作に通じる上で絶対に必要だと思う知識のみを抽出しているつもりです。
ので、すぐには実感がわかなくとも最後まで読んでいただければと思います。
よろしくお願いします。
4. Knowledge - 膨大な文書を理解する
ChatGPTの知識を強化する「Knowledge」機能の詳細な解説です。
章目次:
1. Knowledgeとは
2. Knowledgeで出来る事
3. Knowledgeを実際に使う
4. Knowledgeの仕組み
5. Embeddingについて
6. より良いKnowledgeを作るために
4-1. Knowledgeとは
「Knowledge」はChatGPTが膨大な量の情報を理解するための新機能です。予め特定の情報を与えておくことで、対話の中で適宜それに基づいた応答をしてくれるようになります。
といっても何のことだか分かりませんよね。
まず、実はChatGPTには文字数制限というものがあります。
試しに通常のChatGPTを立ち上げて、初めに自己紹介をした上でめちゃくちゃ長い文章を読ませたり、めちゃくちゃ長い返答をさせてみてください。
これを繰り返すと、どこかで最初にChatGPT側に伝えておいたはずの自己紹介の内容がきれいさっぱり忘れ去られていることに気づくと思います。
これがChatGPTの文字数制限です。
で、簡単にまとめると文字数(厳密にはトークン数)制限は以下のような仕組みに従っています。
ChatGPTは一度に扱える文章量に制限がある。
文章量は「トークン数」という単位で表され、日本語なら大体1文字=1トークンの換算。
有料版ChatGPTでのトークン数の上限は「8196」つまり8000文字くらい。
8197トークン目に突入した瞬間から1文字ずつ過去を忘れていく。
会話が長引くと最初に話していた内容を忘れていってしまうのは、ChatGPTのこの仕様によるものなんです。
そうでなくとも会話の分量が増えるほどに反比例してChatGPTの性能が落ちていくのは、ある程度対話を繰り返してみれば経験的にはっきり分かると思います。
明らかに、従来のChatGPTは全体的に長文に弱い・一定量を超えると完全に無力でした。
・・・で、今解説している「Knowledge」はそんなChatGPTの欠点を根本的に解決する仕組みです。
具体的には、これまでのChatGPTは「過去の全会話記録と全情報を読み込んだうえで対話を継続する」という仕組みになっていましたが、それを「与えられた情報のうちから現在の会話に関連が深い部分だけを取り出して参照し、対話を進める」としたのがKnowledgeです。
言い換えれば、
「全部完璧に覚えている」ことをやめて「適宜必要な記憶だけを思い出す」ようにしたとか。
「教科書丸暗記の試験」が「辞書持ち込みOKの試験」になったとか。
そんなイメージでしょうか。
4-2. Knowledgeで出来る事
以上の説明を踏まえて、Knowledgeを使う事で何が出来るかを考えてみましょう。
まず思いつくのは「長大な辞書の検索システム」といった類のもの。
状況に応じて必要な知識を言葉で説明してくれるようなイメージです。
あとは「課題解決用の予備情報を大量に与えておいて、状況に応じてそれを参照しながら高度な解決方法を見出してくれるAIアシスタント」とかも作れそうです。先ほどの「辞書持ち込みOK」的な捉え方ですね。
そう考えると、Knowledgeだけでも相当にChatGPTの能力が拡張されていそうな気がします。
マネタイズ的な観点でも、Knowledgeに有用な知識を入力しておけばそれが即ちそのGPTsの大きなオリジナリティとなる訳です。
役立たずのGPT Builderから一転、希望が見えてきました。
早速、次項でKnowledgeを用いたGPTs制作を実践してみましょう。
4-3. Knowledgeを実際に使う
改めて、KnowledgeとはGPTsに予め何らかの知識を与えておくことのできる機能です。
それをこれから実際に扱ってみましょう。
シンプルな知識解説のGPTsを作っていきます。
ということで再び新たな制作画面にアクセス。
Knowledgeの追加はConfigureの「Upload files」から行えます。

ここに何らかの「知識」をアップロードすることになります。
アップロード可能なファイル形式は".txt"を筆頭に、".py"や".docx"など何らかの文字情報を含んでいる事が前提のもの。
アップロード可能なファイルの一覧:
[".c", ".cpp", ".docx", ".html", ".java", ".json", ".md", ".pdf", ".pdf", ".php", ".pptx", ".py", ".rb", ".tex", ".txt"]
試しに、Wikipedia内でも有数の文字数で知られる「ヨーロッパにおける政教分離の歴史(185230文字)」の全文をまとめた一つのテキストファイルを制作し、Knowledgeへアップロードしてみます。

アップロードが完了したら、右側のPreview欄でGPTsの挙動を確かめましょう。
ここでは「浄土真宗の僧侶「島地黙雷」が日本の政教分離において成した功績を教えてください」という、ネイティブのChatGPTでは絶対に知らなそうなドマイナー人物の知識を尋ねてみます。
その回答がこちら。

元の情報を見る限り、この内容は正しいです。
それも少し離れた距離に散らばっていた情報をまとめ「日本の政教分離における島地黙雷の功績」というテーマに合わせて上手く整えられた文章となっています。
185000文字という膨大な情報量からユーザーの要求した部分だけを適切に抽出し、簡潔な文章にまとめて出力する・・・という、期待通りの挙動が確認できました。
ひとまずは、これがKnowledgeの能力です。
4-4. Knowledgeの仕組み
Knowledgeが大量の知識を処理できることは分かりました。
でも、一体どうしてこんな事が可能になったのでしょうか?
ChatGPTが登場してから一年もの間ユーザーたちを悩ませてきたコンテクスト長制限の問題が、ある日唐突に「無限の長さを理解できるようになりましたよ」っていくら何でも突飛です。
画期的すぎますよね?
が、実際はものすごく単純でありふれた作りなんです。
ということで、ここでKnowledgeの仕組みを詳しく解説しておきます。
内部の仕組みを知ることで、より上手くKnowledge機能を扱えるようになるはずです。
専門用語が急に増えますが、是非とも読み飛ばさずにご覧下さい。
Retrievalについて
そもそもですが、Knowledgeが知識を思い出す("Retrieval"と言う)のは以下のような仕組みによって成り立っています。
Knowledgeフォルダに与えられた文書の内容をEmbeddingによってベクトル化しておき、また対話の中でも適宜重要なキーワードのEmbeddingを行う。知識検索の際にはKnowledgeを参照し、その文量が少ない場合は全文を取得する。文量が多かった場合には「キーワードとKnowledgeの各部分間でのベクトル同士のコサイン類似度を比較し、最も類似度の高かった箇所を知識として取得する」という流れ。
・・・はい。
この説明では殆どの方が「日本語でおk」状態だと思います。
ここから詳しく簡単に解説していきます。
まず初めにさっと述べた通り、Knowledgeを用いたChatGPTは「与えられた知識の全文を常に理解しながら対話している」わけではありません。
辞書を読むのと同じように、適宜必要な情報だけを探して取得しています。
それ自体は誰もがよく知る「検索」です。
我々がググるのと同じようにChatGPTも情報の検索を行っているのです。
が、GoogleとChatGPTのそれは少し仕組みが違います。
Googleの検索システムは・・・非公開ですが、まあ基本的には検索欄に入力された単語そのものとWebページのタイトルなどの一致を見ながら検索結果が決められていますよね。
言うなれば「単語の一致検索」といった感じ。
それに対して、ChatGPT・・・というか大規模言語モデル全般の記憶検索システムにおいて用いられるのが「文章の類似度検索」です。
「単語の一致」⇔「文章の類似度」
この違いは一体なんでしょうか。
簡単な例えを出しますね。
「深層強化学習」という言葉があります。
英語でいうと「Deep Reinforcement Learning」です。
じゃあインターネット上に深層強化学習の方法を詳しく解説する「How to Deep Reinforcement Learning」というサイトがあったとして・・・
Googleの検索欄に「深層強化学習の仕方が分かんねえんだよーーーーーッ」と入力しても、絶対にそのサイトにはたどり着けませんよね。
それは「深層強化学習の仕方が分かんねえんだよーーーーーッ」という言葉と「How to Deep Reinforcement Learning」というタイトルの間にどう考えてもなんの一致も見られないからで、当たり前の事です。
が、文章の類似度検索では話が変わります。
実際上記の二つの文章って、意味的には近いというのは誰だって分かると思います。
どちらも深層強化学習の方法についての内容になっています。
するとChatGPT等が用いる文章類似度の観点では、
「この2つの文同士は高い類似度を持っている」という扱いになるのです。
だからChatGPTが「思い出す」時には単語の一致などどうでもよくて、意味的に関連している記憶を呼び起こすことが可能というわけです。
まるで人間が何かを思い出す時のようじゃないですか?
対話というあいまいな形の文章を基にして知識を検索するのであれば、「単語の一致を調べる」などという固すぎる仕組みよりもずっと有効そうです。
「家畜の骨を煮込んだ麺料理」→「豚骨ラーメンの事ですか?」
「あのアメリカ人野郎」→「デイビッドさんの事ですね」
「今日学校で〇〇で○○でしんどくて○○…(1000文字を超える長文)」→「大変でしたね」
みたいな感じ。
だから一般的に、文章生成AIに知識検索システムを搭載する時は文章類似度の比較が用いられるのです。
4-5. Embeddingについて
しかし、ChatGPTは一体どうやって文章同士の類似度なんてものを検索しているのでしょうか。
異なる言語の、異なる立場の発言や文章を比べて「意味が似てる」って、よく考えたら凄すぎる認識能力ですよね。
それには「Embedding」という概念が深く関わっています。
まず大規模言語モデルの世界において、Embeddingという言葉は「文章をベクトルに変換する処理」を意味します。
そしてベクトルとは決まった量の(例えば3次元なら3つの)数字の集まりのことです。
ベクトルが数字の集まりで、Embeddingが文章のベクトル化で・・・
つまりEmbeddingとは「文章を数字の集まりに変える」ってことになりますね。
さて、どうして文章を数字の集まりに変えると類似度を比較できるのか。
答えは、方向の比較をしているのです。
例えば:
「右に3歩」と「右に10歩」は全く同じ方向です。
「右に3歩、前に2歩」と「左に3歩、後ろに2歩」は真逆の方向です。
「xに3、yに3、zに3」と「xに10、yに9、zに11」はかなり似てる方向です。
こんな感じで・・・
「林檎」を「3、3、3、3」,
「みかん」を「20、30、40、20」,
「林業」を「0、7、2、-4」,
みたいに変換します。
この変換は言葉を「意味のベクトル空間」に移動させるもので、ChatGPTのような言語を解するAIの力を使っています。
さて、こうして見ると「林業」と「林檎(りんご)」よりも、「林檎」と「みかん」の方が明らかに数字上「近い方向」ですよね。
だからChatGPTにとっては、文字が被っている「林檎」「林業」よりも意味の方向性が近い「林檎」「みかん」の方がヒットする、という寸法なわけです。
さて、それを踏まえて・・・
少しでも実感が湧くようにと思って、こんなアプリを作ってみました。

Knowledge機能の内部で動作しているEmbeddingモデルと同じものを用いて、入力した二つの文章の類似度をその場で比較してくれるAIアプリ?です。
例えば「How to Eat Apple」と「How to Deep Reinforcement Learning」の比較をすると・・・

類似度0.753。
対して「How to Deep Reinforcement Leaning」と「深層強化学習の仕方が分かんねえんだよーーーーーッ」の類似度は・・・

0.797!
やはり文字より意味を読み取ってくれていることが分かります。
ということで、様々な文章や単語間のコサイン類似度を表示してくれるアプリでした。
多分公開すると思うので、凝り性の方はKnowledge構築の参考にでも使ってみてください。
(公開するかもしれない、しないかも知れない)
→ 結局「二つの用語を言うと類似度を教えてくれるGPTs」として公開しました。
OpenAI APIを用いており使う度に金をとられる為、noteの購入者様のみに「記事のおまけ」として提供することにします。
(無いとは思いますが実用目的でアプリに組み込まれたりしたら停止します。勘弁してください)
リンクは記事の最後「付録」の章に記載してあります。
4-6. 期待通り動作するKnowledgeを作るためには
これまで解説した内容に基づいて、最後に「期待通りの動作をするKnowledgeを作る方法」について考えてみましょう。
まず絶対的に必要なのが「文章の意味を明示しておくこと」です。

「Knowledge」と「その、あれ」というように「意味上も全く関係ない二文同士」の関係では、当然ながら類似度の検索システムは無力です。
人間は「アレのアレ」などというだけで十分な意思疎通が出来る事も少なくないですが、ChatGPTは流石に言外の意味までは汲み取ることが出来ないのです。
だから例えば「黄河は水たまりを叱りはしない」みたいな分かりにくい例えをKnowledgeに用いるのはあまり推奨されません。
また、
[ダニエル: 30歳, デイビッド, 22歳, 雄介, 18歳, キム: 45歳]のようにただ情報の断片を羅列しておくだけというのも望ましくありません。
これでは「メンバーの年齢一覧を見せて」などとユーザーに問われた時、うまく該当の箇所を検索できない可能性があります。
ではどうすれば良いのか?
答えは単純で、
「黄河は水たまりを然りはしない(意味:○○)」
「メンバーの年齢一覧:[ダニエル: 30歳, デイビッド, 22歳, 雄介, 18歳, キム: 45歳]」
のように、具体的に情報の意味を添えておくことです。
ある意味で「タグ付け」のような考え方でしょうか。
文章自体の意味が曖昧であるほど、このタグ付けが大きな意味を持つようになります。逆に文章そのものから一目瞭然の部分ではあまり役に立たないかも知れません。
また次に効果を期待できるのが、「予め文章を階層分けしておくこと」です。
Knowledgeの検索システムですが、複数ファイルが与えられている場合は「関連していそうなファイルをとりあえず覗いてみる」という動作をするようです。
ので、例えば
「xを用いたyによるz上でのvを目的としたAの構築方法」
「xを用いたyによるz上でのvを目的としたBの構築方法」
みたいな2つのよく似ている情報があるとします。
この時それぞれを「ファイルA」「ファイルB」に予め分けておけば、検索の対象範囲自体が絞られることとなり、結果として内容の意味的な重複がノイズになる事を避けられます。
そして最後の、最も重要な取り組みが「Knowledge内の各部分の意味をはっきりと分けておく」こと。
たとえば「メンバーの年齢一覧:○○」という情報をKnowledgeに入れたなら、少なくともその検索スコープ内では似たような文章(メンバーの家族の年齢一覧とか)を含めておかないようにするという単純なものです。
Knowledgeの知識検索はあくまで「類似度が高かったもの」を取り出す仕組みになっています。仮に目的の部分で高い類似度を検出したとしても、他にも高い点数の部分がいくつもあったのならChatGPTは回答に迷ってしまうでしょう。
なので、初めから「知識が重複しているように見えないように」Knowledgeを構築しておくことが何よりも重要なのです。
4-7. Knowledgeまとめ
この章ではKnowledgeの使い道と使い方、その仕組みについて詳細な解説を行いました。
まとめると以下のようになります。
まとめ:
・KnowledgeによってChatGPTは従来より多くの情報を理解できるようになった。
・Knowledgeは文章の意味の類似度を測る検索システムによって機能している。
・期待通りに動作するKnowledgeを構築するためには、各部分の意味を明示する事、検索スコープを絞る事、別の部分で意味が重複しない事を意識する。
(無料版はここまでとなります。閲覧頂きありがとうございました。)
ここから先は
¥ 2,980
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?