
FanGraphsのtableデータをRで取得する

fangraphsのテーブルデータのDLが有料会員限定になったため、Rstudioを使って取得しようという内容です。
有料機能を見つけたので早速使ってますが、無料で全部読めます。
使うソフトは
・Rstudio
・tidyverseパッケージ
・rvestパッケージ
今回は、Teamスタッツの打撃部門・Dashboardデータをスクレイピングします。
Major League Team Stats » 2023 » Batters » Dashboard | FanGraphs Baseball
まえがき
htmlファイルの構造に関しては全くの無知です。下のwebサイトを参考に実行したら上手くいったというだけです。今から記す手順で他のwebサイトもスクレイピングできるかはわかりません。あくまでfangraphs限定ということでご理解ください。
まず、read_html関数を実行して、URLからwebページの情報を取得します。
url <- "https://www.fangraphs.com/leaders.aspx?pos=all&stats=bat&lg=all&qual=0&type=8&season=2023&month=0&season1=2023&ind=0&team=0,ts&rost=&age=&filter=&players=0"
html <- read_html(url)続いて、html_element関数でtableデータが収録されているノード(node)を抽出します。
tbl <- html_element(html, css = 抽出したいノード)抽出したいノードをcssセレクターで指定するのですが、これを探すのが少し面倒。Microsoft edgeの「開発者ツールで調査する」を用いて抽出したい部分を探します。
①右クリック
→「開発者ツールで調査する」をクリック
→ 画面右に英語の羅列が登場
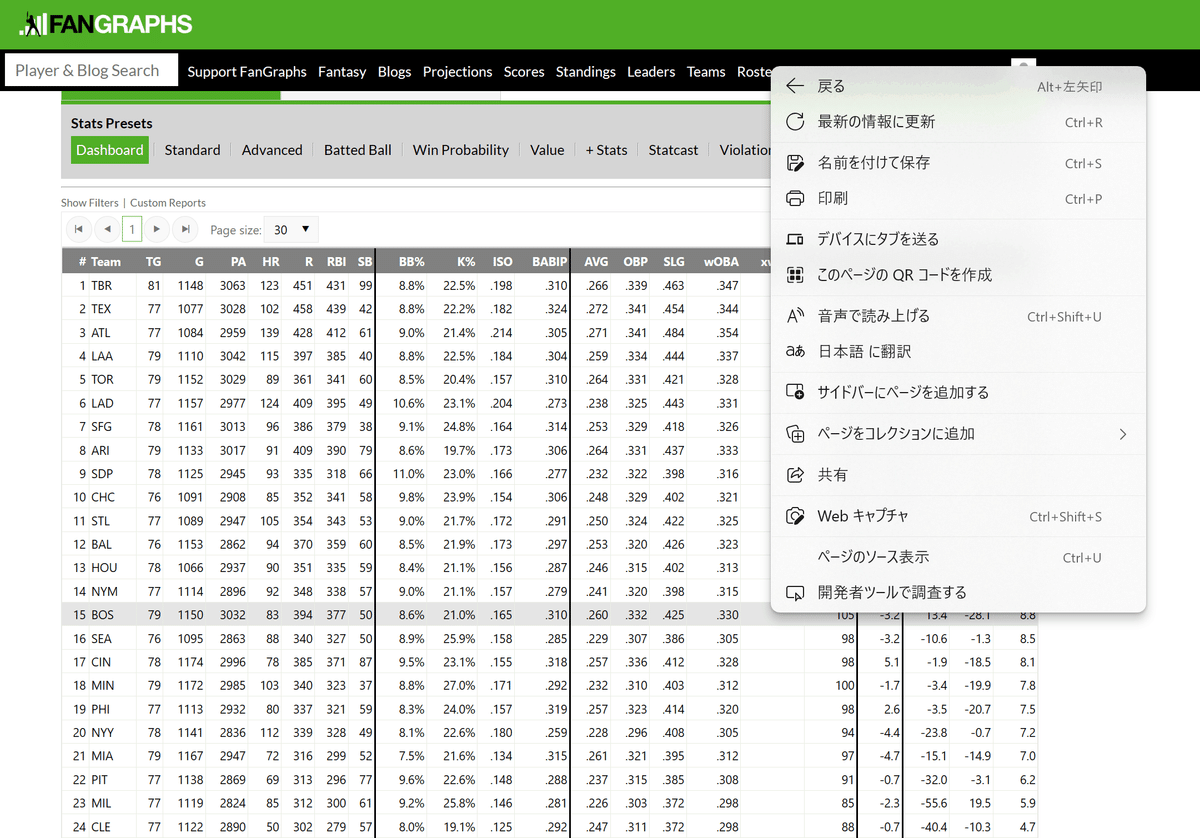
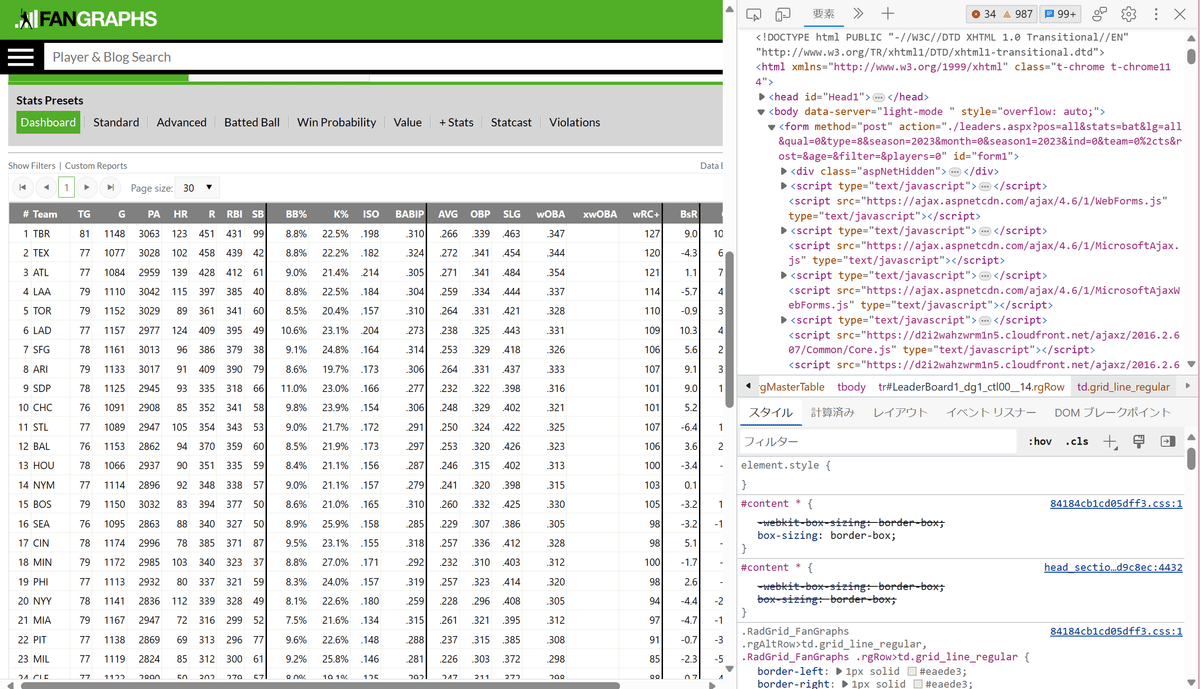
②tableデータが収録されてるノードを探す
→ 該当のタグを右クリック
→ コピー
→ Xpathをコピー
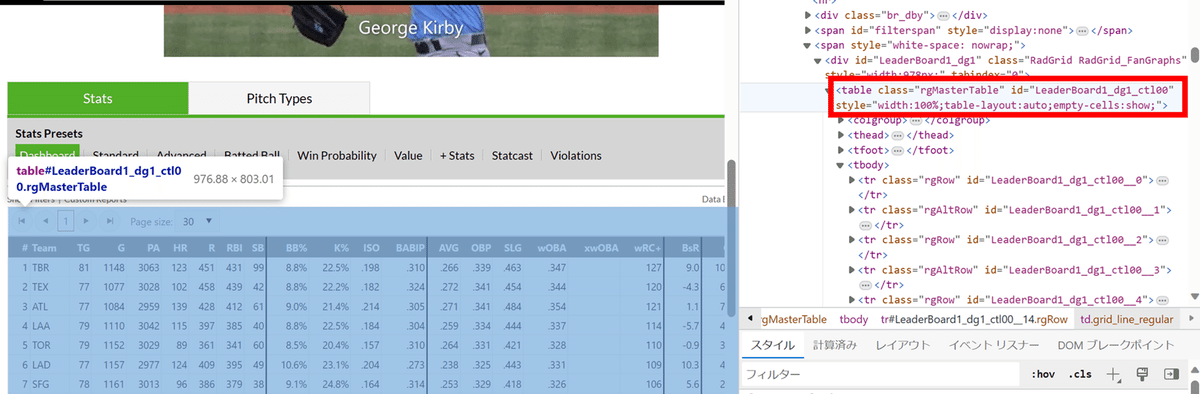
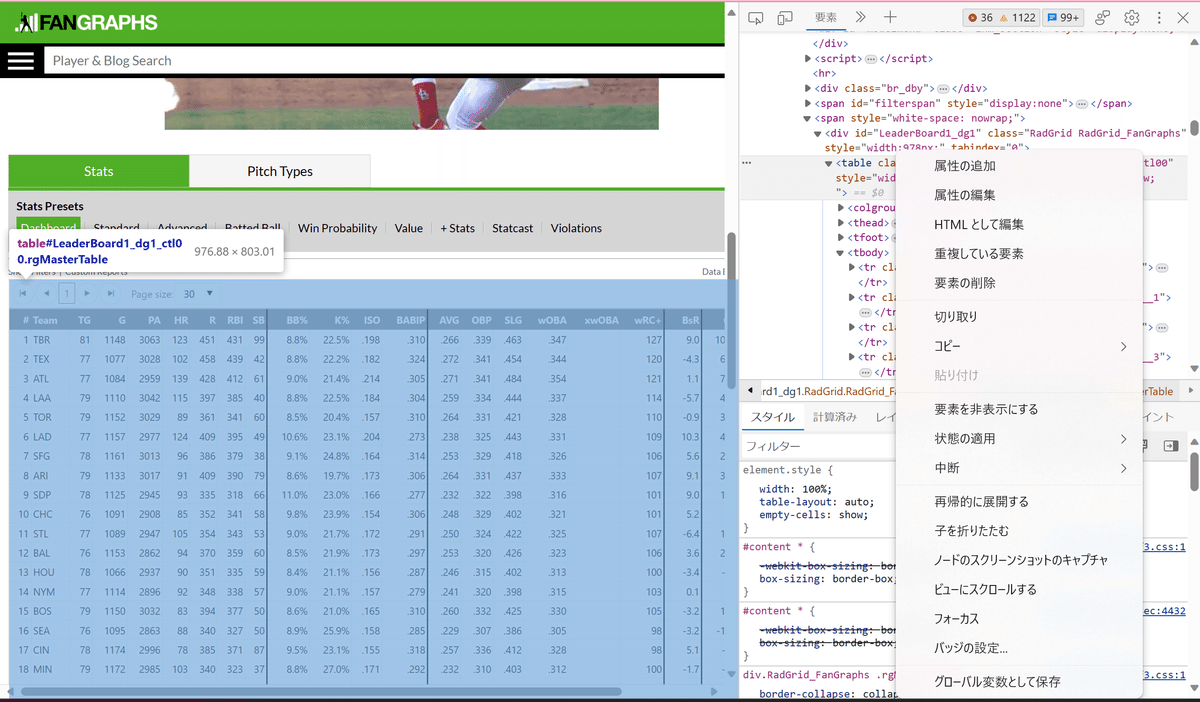
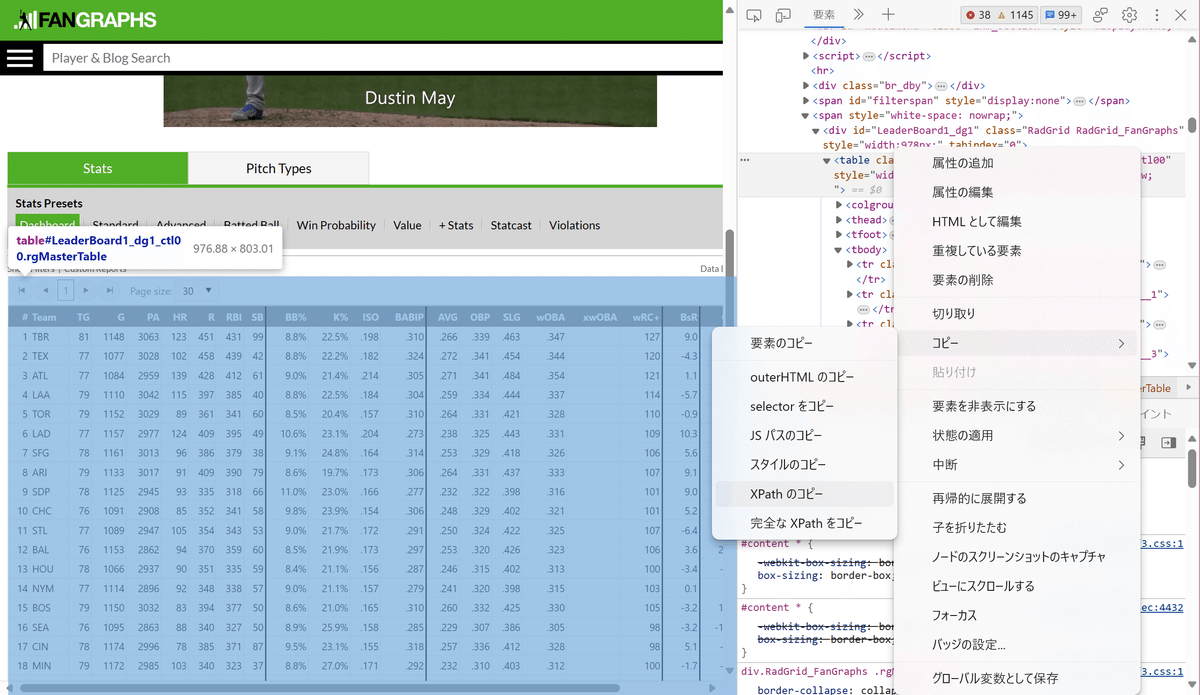
以上の手順を踏むとcssセレクタを取得できます。
#取得したcssセレクタ
//*[@id="LeaderBoard1_dg1_ctl00"]そしてhtml_element関数に貼り付けますが、そのまま貼り付けると上手くいきません。

" / "と"@"は予期しない文字と判断されます。
なので少し手直し。
#実際に貼るコード
*[id=LeaderBoard1_dg1_ctl00]
tbl <- html_element(html, css = "*[id=LeaderBoard1_dg1_ctl00]")最後に、html_table関数でhtmlの表をデータフレーム形式で抽出します。
df <- html_table(tbl)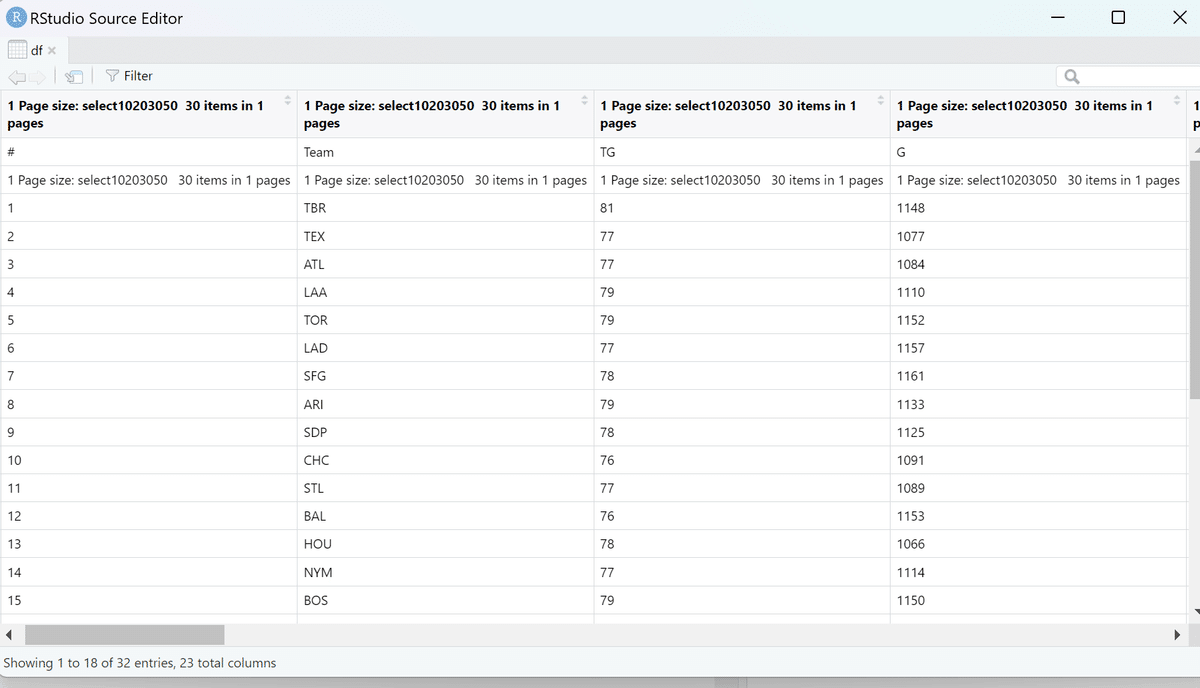
これで抽出完了。ただ、列名が2行目に入ってたりして見栄えが悪いので整えます。
colnames(df) <- df[2, ]
df1 <- df %>% slice(-c(1:3))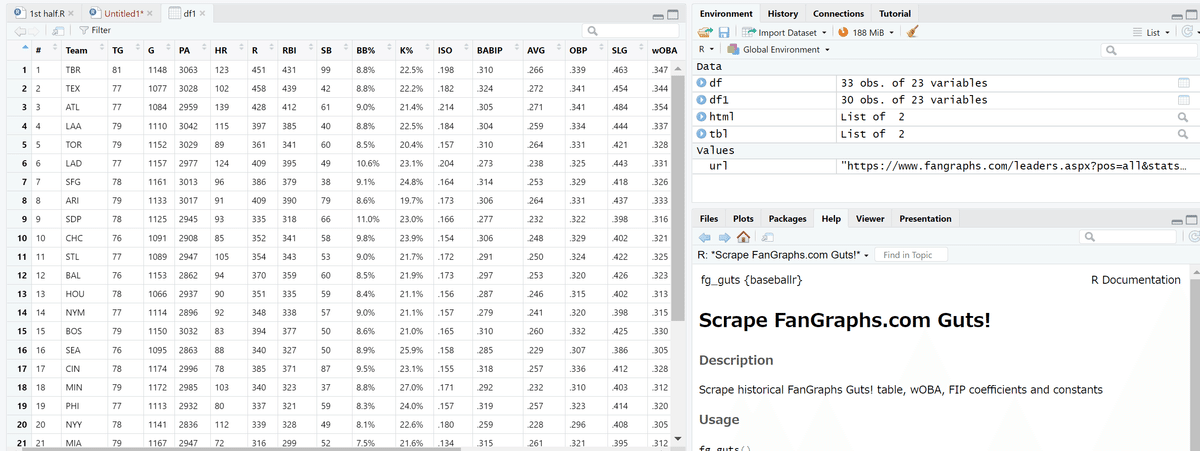
おしまい。
あとはwrite_csv()で保存すればOK。
library(tidyverse)
library(rvest)
url <- "https://www.fangraphs.com/leaders.aspx?pos=all&stats=bat&lg=all&qual=0&type=8&season=2023&month=0&season1=2023&ind=0&team=0,ts&rost=&age=&filter=&players=0"
html <- read_html(url)
tbl <- html_element(html, css = "*[id=LeaderBoard1_dg1_ctl00]")
df <- html_table(tbl)
colnames(df) <- df[2, ]
df1 <- df %>% slice(-c(1:3))
write_csv(df1, "team23_dashboard.csv")今回はTeamスタッツのBatting_Dashboardをスクレイピングしてきました。上述の手順を踏めばStandardやAdvancedのtableデータ、Pitching/Fieldingも取得できます(検証済)。個人成績(Leaders)も同様です。ただ、選手ページのtableデータを取得できるかは不明です。
余談
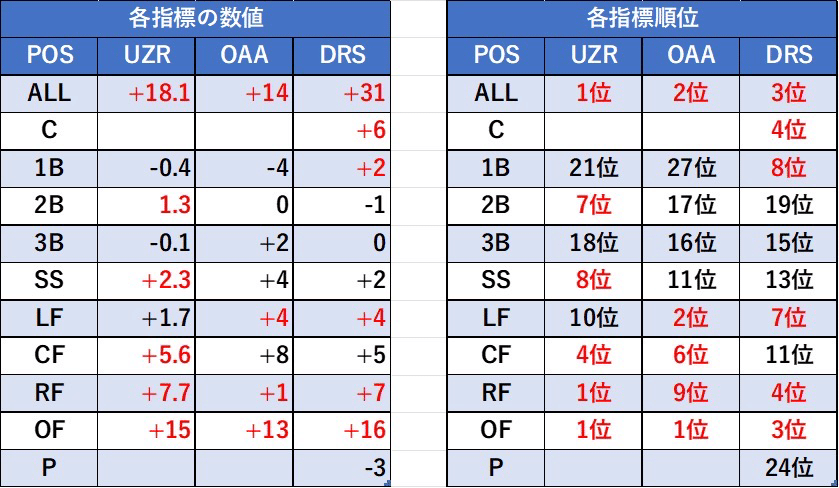
URLが意外とシンプルなので、map関数を活用して、複数の年やスタッツタイプ(Standard/Batted Ballなど)をひとつのdata.frameにまとめることもできます。
前半戦振り返りpart1に載せたこの表は、map関数で各ポジションのFieldingデータを一括取得→rank関数で順位づけという手順で作成してます。excelとfangraphsの行き来は手間ですからね。
ここから先は
¥ 770
この記事が気に入ったらチップで応援してみませんか?