7. Performance Best Practice

「Performance Best Practice」の受講完了致しました~^^
この問いに関しても備忘録として、問題の考え方を残しておきますので、
よろしればこちらの記事を参考に考えてみてください!
※注意:特に自分の中で感じたことをまとめているので、選択肢すべてを網羅しているわけではないです!色々な方の記事を参考に自分なりに考えてみてください…!
▶ パフォーマンスが悪いとなぜいけないのですか?
答えを得るのに時間がかかる
フローに乗れない
イライラする
本当のTaskを忘れる
<ポイント>
データはみたいときにみれて力を発揮します。
パフォーマンスが悪いと時間もかかりますし、フローにのれないばかりか、
本当のTaskを忘れてしまう原因にも…。
(データがくるくる回っていてはイライラもしますw)
▶ 表計算はどこで処理されますか?
データベース
Tableau
<ポイント>
表計算はTableau側で処理します。
(Tableau側で計算式書きますよね!)
▶ JOIN(結合)はどこで処理されますか?
データベース
Tableau
<ポイント>
JOINはデータベース側で処理します。
(元データはなるべくデータベース側で処理した方が都合が良い。)
▶ Tableau Desktopで表示が遅くてもTableau Serverで高速に表示できる
正しい
誤り
<ポイント>
Desktopで遅ければ、Serverで早くなることはない
→Serverでは様々な処理を同時に行っている為
▶ 次の内Tableauのシートで作業する前に件数を減らせるフィルターを選びなさい
ディメンションフィルター
抽出フィルター
コンテキストフィルター
データソースフィルター
<ポイント>
下記はフィルターの優先度の順番。(上に行くほど影響大)
コンテキストフィルター以下はワークシート上で働き、以上はワークブック(ワークシートの集まった1つのまとまり)全体に働く。
▶ データの集計が遅い場合、DBで事前にテーブルを準備してもよい
正しい
誤り
<ポイント>
DB上で事前にテーブルを準備しておけばTableau上での必要な処理が少なくなり、集計も早くなる。
▶ 売上のトランザクションデータと地域マネージャーのマスターデータのテーブルがある。これらのテーブルは同じスキーマ内に存在している。一般的に適切と思われる結合方法はどれか?
結合(JOIN)
ブレンディング
クロスデータベース結合
<ポイント>
同じスキーマ内というところがポイント。

▶ 売上のトランザクションデータと在庫のトランザクションのテーブルがある。これらのテーブルは別のデータベースに存在しており、異なる粒度でデータが格納されている。商品単位での売り上げと在庫とを比較したい場合、一般的に適切と思われる結合方法はどれか?
結合
ブレンディング
クロスデータベース結合
<ポイント>
別のDB上∧粒度が異なるというのがポイント。
粒度が異なる場合には集計して、粒度を揃えてから結合しないといけないですよね…?

▶ ライブ接続と抽出接続について正しいものを答えなさい
ライブ接続は抽出接続より必ず早い
抽出接続はライブ接続より必ず早い
ライブ接続が早いか、抽出接続が早いかはケースバイケースである
<ポイント>
接続方法以外にも様々な要因に依存するためどちらが必ず早いということは言えないのでは…?
▶ 抽出は必要な粒度で集計した状態で作成することができる
正しい
誤り
<ポイント>
抽出時に条件でフィルターをかけたり、サンプリングしてデータ量を少なくしたりすることが可能。
→必要な粒度で集計可能
▶ 行レベル計算を内包する集計計算を作成するときは
計算式を分けて記載する
一つの計算式にまとめる
<ポイント>
計算式を再利用しやすい∧長い計算式はわかりにくくなるので、分けて記載した方が良い。
行レベル計算と集計計算を分割
→行レベルの計算を1つ目の計算フィールドに、集計計算を2つ目の計算フィールドに
▶ 地域項目の中に入っている値「北海道」と「東北地方」を表示上「北日本」エリアとしてまとめたい。適切な方法はどれか?
元データの「北海道」と「東北地方」を「北日本」に置換する
グループ化して別名をつける
右のような計算式を作成: IF [地域]="北海道" OR [地域]="東北地方" THEN "北日本" ELSE [地域] END
<ポイント>
計算式を書くよりも、Tableauのネイティブ機能(既存で使える機能)を使った方が処理速度が速い。
計算式でしか対応できない場合に計算式を書くようにする。
▶ 最も速く処理できるデータ型を選びなさい
※一般的なプログラミング言語やシステムについてではなく、Tableauの計算フィールドのパフォーマンスについて回答してください。
ブール型
整数型
文字列型
<ポイント>
速い順に【整数型】>【ブール型】>【文字列型】
▶ 日付の列に「2019年06月06日」という形式でデータが入っており、文字列として取り込まれた。日付型に直す方法として最初に試すべきことは?
計算式を作成する:DATE(LEFT(STR([日付]),4) + “-“ + MID(STR([日付]),5,2) + “-“ + RIGHT(STR([日付]),2))
計算式を作成する: DATEPARSE("yyyy年MM月dd日",[日付])
文字列型になっているデータ型をそのままDate型に変更する
<ポイント>
まずはそのままDate型に変更してみる
→8桁の数字等であればこれで出来る可能性が高い
▶ 日付のフィルターを作成したい。一番パフォーマンスがいいのは?
不連続フィルター
連続型の範囲フィルター
相対日付フィルター
<ポイント>
パフォーマンスの良い順に【相対日付フィルター】>【連続型の範囲フィルター】>【不連続フィルター】
※不連続は一つ一つデータを取得、範囲フィルターは範囲をまとめてとってくるため、決め打ちの相対日付にパフォーマンスが最も良い。
▶ フィルターを自由に選べるように表示しておくことにした。パフォーマンスがよいのは?
複数の値(ドロップダウン)
複数の値(カスタムリスト)
<ポイント>
表示する必要のある項目をすべて取得する必要がある為、ドロップダウンは遅い。一方、項目がデータに依存しないクイックフィルター(カスタム)は速い。
▶ 表示されたフィルターの「関連値のみ」オプションを使用すると
表示項目が減るため早くなる
クエリが増えるため表示が遅くなる
<ポイント>
関連値のみにするために必要な処理が必要になるため遅くなる。
見た目や使い勝手は良いが…。
クイックフィルターは必要最低限に!
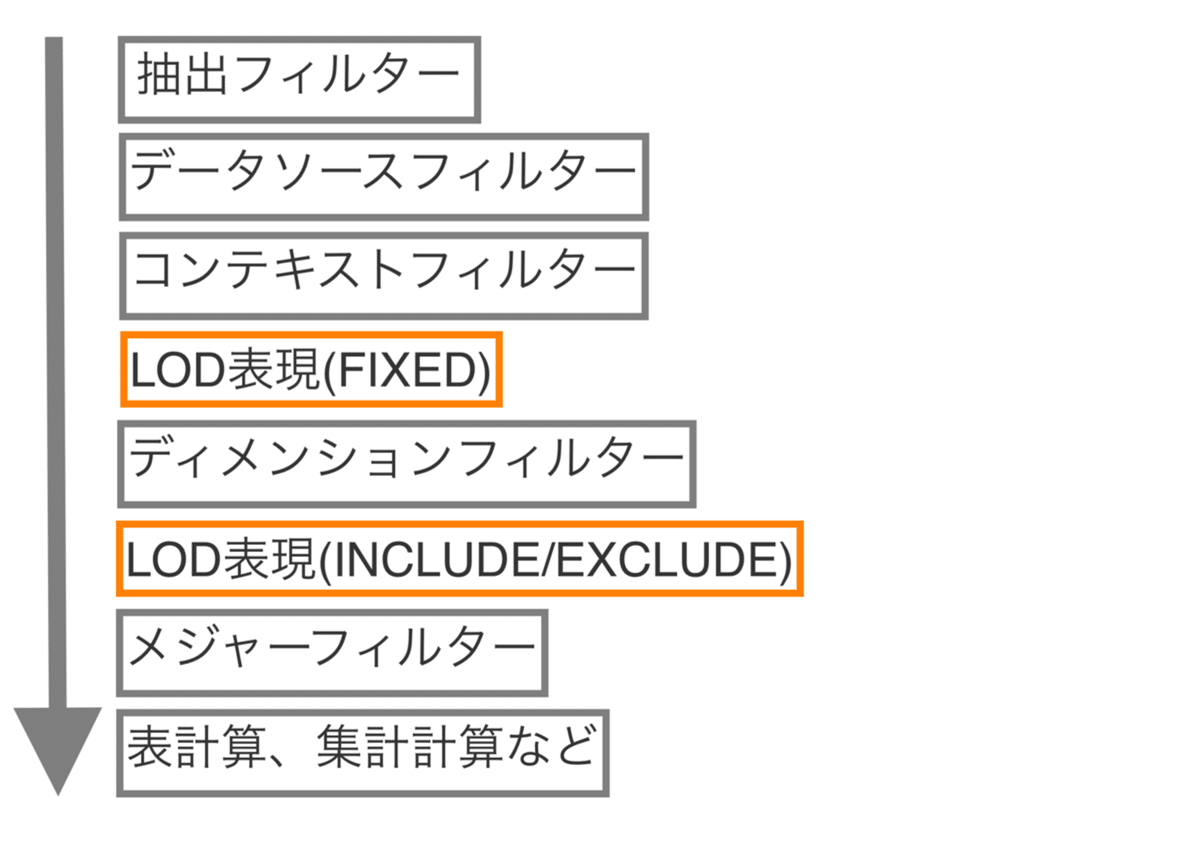
▶ クエリパイプラインとして正しいものを選びなさい
抽出フィルター、データソースフィルター、コンテキストフィルター、FIXED、ディメンションフィルター、EXCLUDE/INCLUDE、メジャーフィルター、表計算フィルター
データソースフィルター、抽出フィルター、コンテキストフィルター、ディメンションフィルター、FIXED、EXCLUDE/INCLUDE、メジャーフィルター、表計算フィルター
抽出フィルター、データソースフィルター、コンテキストフィルター、FIXED、ディメンションフィルター、EXCLUDE/INCLUDE、表計算フィルター、メジャーフィルター
抽出フィルター、データソースフィルター、コンテキストフィルター、FIXED、EXCLUDE/INCLUDE、ディメンションフィルター、メジャーフィルター、表計算フィルター
<ポイント>
下記はフィルターの優先度(上のフィルターの方が優先される)
▶ Tableauは表示できるデータ量に制限がないため、数万行のテキストテーブルを表示するのが得意である
正しい
誤り
<ポイント>
パフォーマンスを維持するためにもなるべくデータ量は必要量にとどめる。
▶ ダッシュボードのサイズは
表示されるべき形にしっかり固定する
ユーザーが好きな大きさで見られるよう、自動にしておく
<ポイント>
見え方によって誤認を生む可能性あり。
こう見えてほしいという状態で固定しておくべき。
▶ パフォーマンスのよいダッシュボードデザインは結果的に人が見たときにもわかりやすいデザインに通じている
正しい
誤り
<ポイント>
シンプルな(パフォーマンスの良い)ダッシュボードは主張が伝わりやすくわかりやすい。
以上、Ord7の備忘録終了です!
ここまで見ていただきありがとうございました!
どなたかの参考になりましたら幸いです。