
pdffontsの実行結果をサブテーブルに登録する(3)

こんにちは。サイボウズ株式会社 開発本部 People Experienceチームの貴島(@jnkykn)です。桜前線が一気に北海道に到達して、近所の桜も見頃を迎えました。先週も冒頭でちらっと触れたのですが、今週もMac初心者としてヨチヨチ歩き中です。USキーボードで日本語変換は「Control+Option+スペースバー」とタイプしていたのですが、昨日ふとキートップに地球儀がプリントされているキーを見つけました。押してみたら、日本語に切り替えができました。次から、これを使って切り替えます。JISキーボードで慣れ親しんだEnterの位置に、Returnとバックスラッシュが上下に並んでいるところも罠です。酒井(@sakay_y)さんに、TouchID付きの日本語キーボードの外付けをおすすめされたので、効率Upのために外付けキーボードを導入予定です。
幸せへの道のゴール
前回は、pdfのダウンロード、pdffonts実行、実行結果のkintoneレコード反映の3つのjobに分けてワークフローで実行するようにしました。しかし、ワークフローでpdffontsが実行できなかったので、pdffonts実行結果をもとにkintoneのレコードに反映するところの確認はできませんでした。今回は、pdffontsを実行できるようにするところから、再開します。
GitHub Actionsでpdffontsを実行できるようにしたい
前回、ランナーとして指定したubuntu-latestにはpdffontsが入っていなくて、実行できませんでした。手元のWSL2のUbuntu 20.04.6ではいきなり実行できたので、ランナーにもプリインストールされているものと思い込んでいたのです。ランナーでpdffontsが実行できるようにするには、pdffontsをインストールできれば良いと考えました。Ubuntuの場合pdffontsはpoppler-utilsに含まれているので、poppler-utilsをインストールできれば良いようです。ランナーにインストールする方法を調べたところ、Ubuntu ランナーへのソフトウェアのインストールという公式のドキュメントがあったので、これに従います。
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install pdffonts
run: |
sudo apt-get update
sudo apt-get install poppler-utils
- name: Install modules
run: npm ciさらにdebug用に、実行結果のtxt内容の出力を追加してみました。
- name: debug
run: cat temp/*.txtここまでを一旦実行してみます。
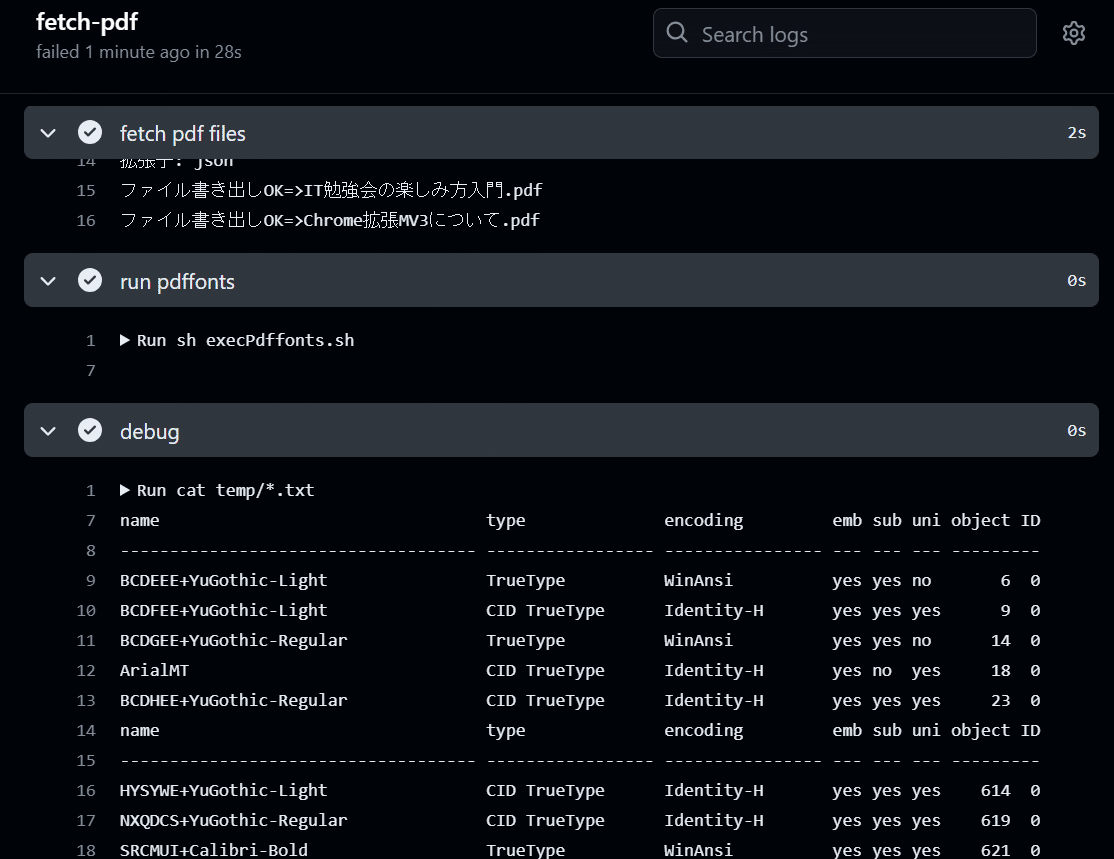
実行結果のレコード反映の確認
jobを分けるために処理を実行するJavascriptを分けた結果、それぞれのjobごとにデバッグできるようになったので、実行結果のレコード反映部分をローカル実行して確認してみます。jobを分けたことで、どこに問題があるか確認しやすくなりました。最初からこうすればよかったかも。
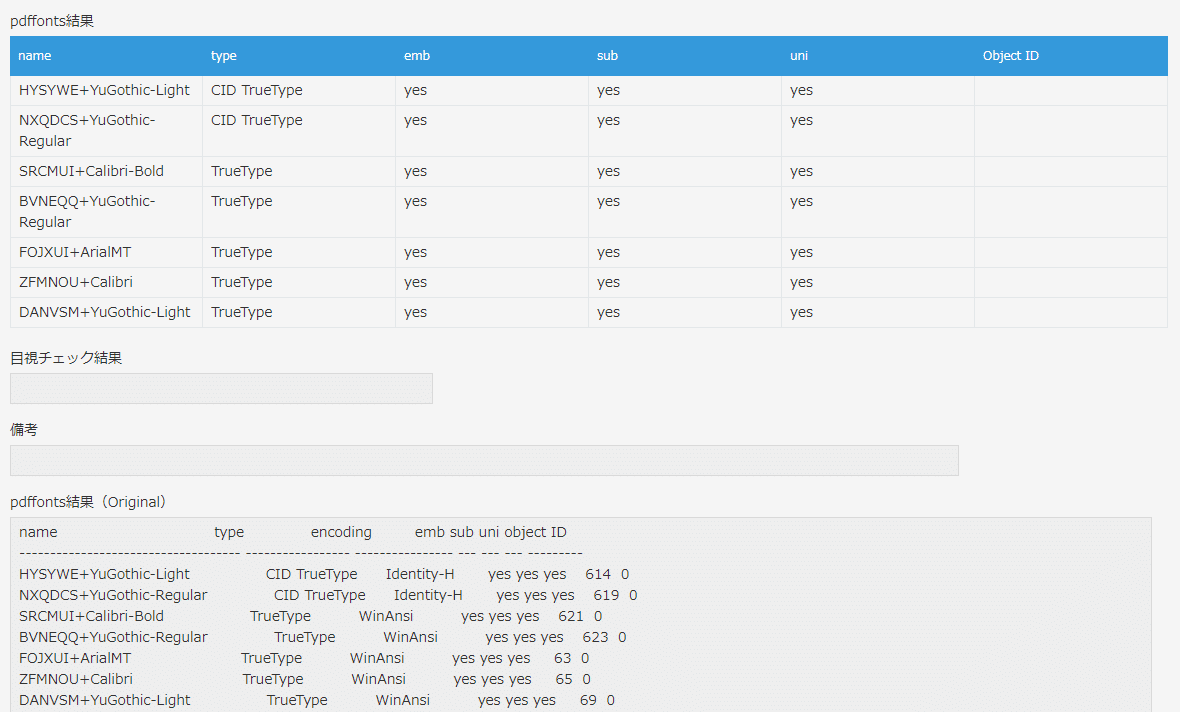
実行ログを見ると、Object IDだけ、valueではなく、objectプロパティに値を設定していました。
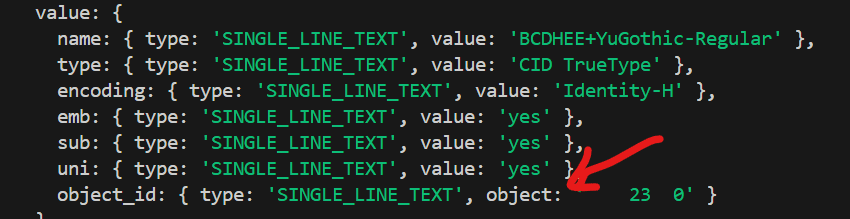
ソースを確認したところ、pdffonts実行結果ファイルのパース結果をサブテーブル用のオブジェクト化するところで、Object IDだけ、valueじゃなくてobjectに設定していました。
const result = {
value: {
name: {
type: 'SINGLE_LINE_TEXT',
value: name
},
type: {
type: 'SINGLE_LINE_TEXT',
value: fonttype
},
encoding: {
type: 'SINGLE_LINE_TEXT',
value: encoding
},
emb: {
type: 'SINGLE_LINE_TEXT',
value: emb
},
sub: {
type: 'SINGLE_LINE_TEXT',
value: sub
},
uni: {
type: 'SINGLE_LINE_TEXT',
value: uni
},
object_id: {
type: 'SINGLE_LINE_TEXT',
object: objectID ← ここ!!!
}
}
}ここを修正すればOKです。
value: {
name: {
type: 'SINGLE_LINE_TEXT',
value: name
},
type: {
type: 'SINGLE_LINE_TEXT',
value: fonttype
},
encoding: {
type: 'SINGLE_LINE_TEXT',
value: encoding
},
emb: {
type: 'SINGLE_LINE_TEXT',
value: emb
},
sub: {
type: 'SINGLE_LINE_TEXT',
value: sub
},
uni: {
type: 'SINGLE_LINE_TEXT',
value: uni
},
object_id: {
type: 'SINGLE_LINE_TEXT',
value: objectID ← 修正!!!
}
}
アプリのサブテーブルのカラムにencodingを追加して、もう一度実行すると、対象レコードのサブテーブルのすべてのカラムに値が反映できました。
ステータスも次の「マニュアルチェック中」に進んでいます。
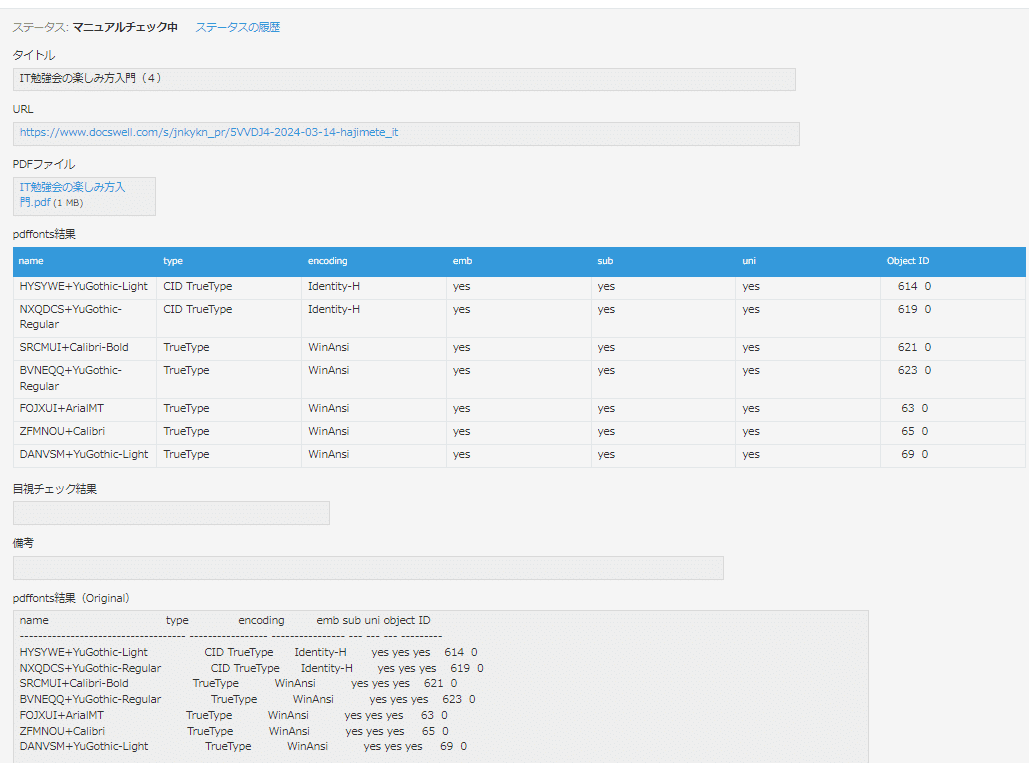
ワークフローの確認
修正をpushして、テスト用データを追加します。
ワークフローを実行して結果を確認したところ、ワークフローは成功していました。

レコードのステータス、サブテーブルも更新できています。今回のpdfは、サブテーブルにたくさんの行が登録されています。これは先週、西原(@tomio2480)さんから共有してもらった、同じフォントが複数検出されるケースに該当しているようです。
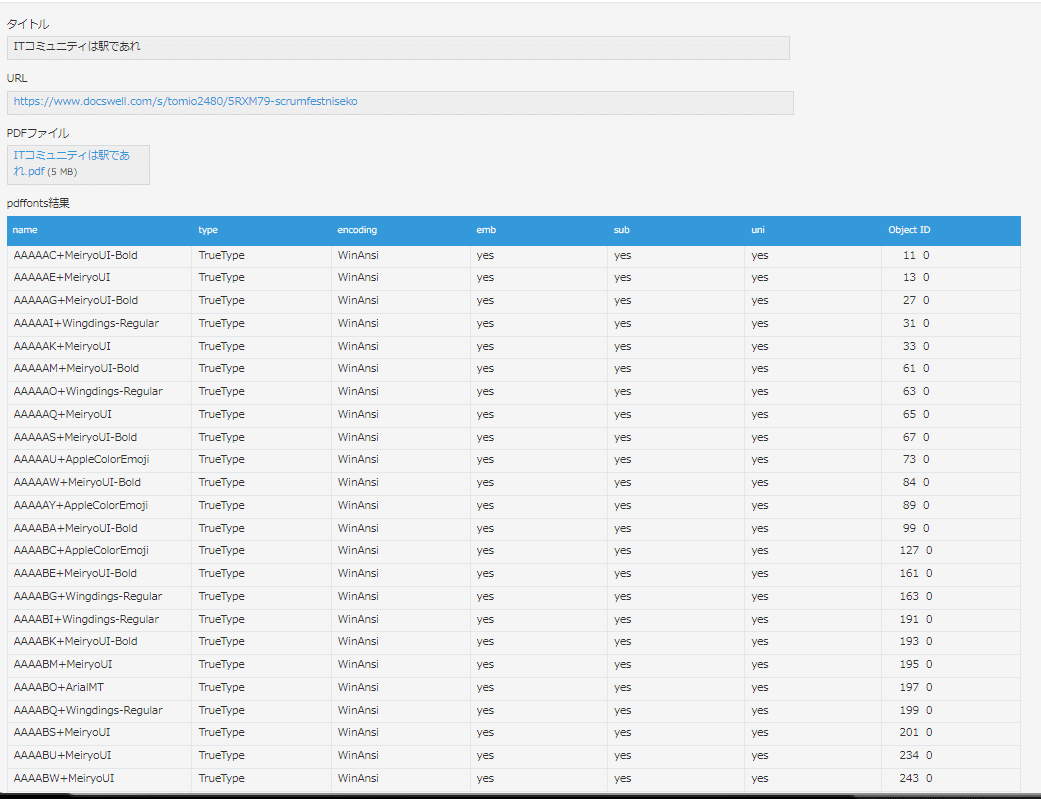
西原(@tomio2480)さんによる、「同じフォント名かつ同じフォントタイプが複数検出される場合に太字フォント以外を太字として使用している可能性があり、太字のかすれが発生すると判断できそう」という仮説が成り立たないケースがあり、太字のかすれを自動検出する方法を再検討しなければならなくなりました。(詳しくは西原(@tomio2480)さんの、「スライドの見た目なおしプロジェクト - PDF に含まれるフォント情報からスライドアップロードサービス上で適切に文字が解釈されるかを知りたかった」をご一読ください)それでも、ひとまず自動チェックのための仕組みができたので、社内用のワークフローに反映して、アプリに粛々とレコードを登録して、シュッとデータを集めたいと思います。データがたくさん集まれば、そこから自動判定のヒントが見つかるかもしれません。
幸せ気分のまま、次のネタに思いを馳せる
めちゃくちゃ時間がかかってしまいましたが、幸せのもとができたので満足です。さて、今週はここまでにします。試したいことや学習したいことはいろいろあるので、GW期間中にどれかに絞り込んで取り組みたいと思います。