
Google Cloud Platformでデータを扱えるようにする(BigQuery)#06

はじめに
こんにちは、今回は、Google Cloud Platform(GCP)のBigQueryの利用開始までの手順について説明します。AIチャットボットのサービス開発では、データ分析のためにデータベースの利用が不可欠で、そのためにBigQueryの利用を開始しました。基本操作として、申し込みからBigQueryの一般公開データセットを使用してクエリを実行するまでのプロセスを紹介します。
今回の結果:BigQueryでGoogle検索のトレンドを知る
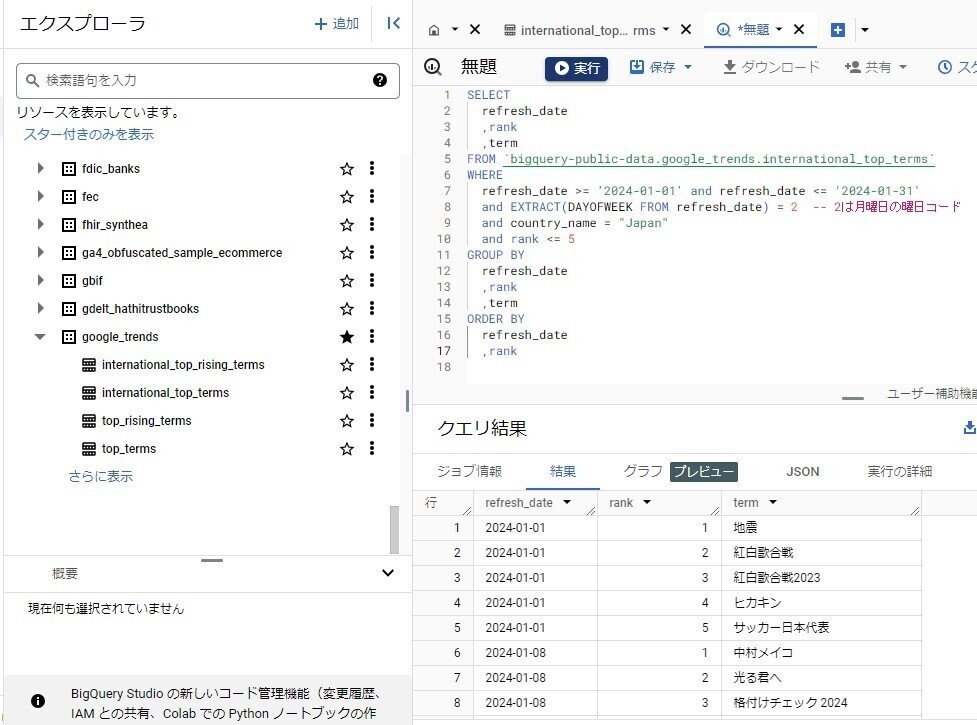
まずは、今回経験した内容を説明します。BigQueryのコンソールを使用して、今年の1月から毎週月曜日のGoogle検索トレンドワードのランキングを出力してみました。下の画面は、BigQueryのコンソールです。
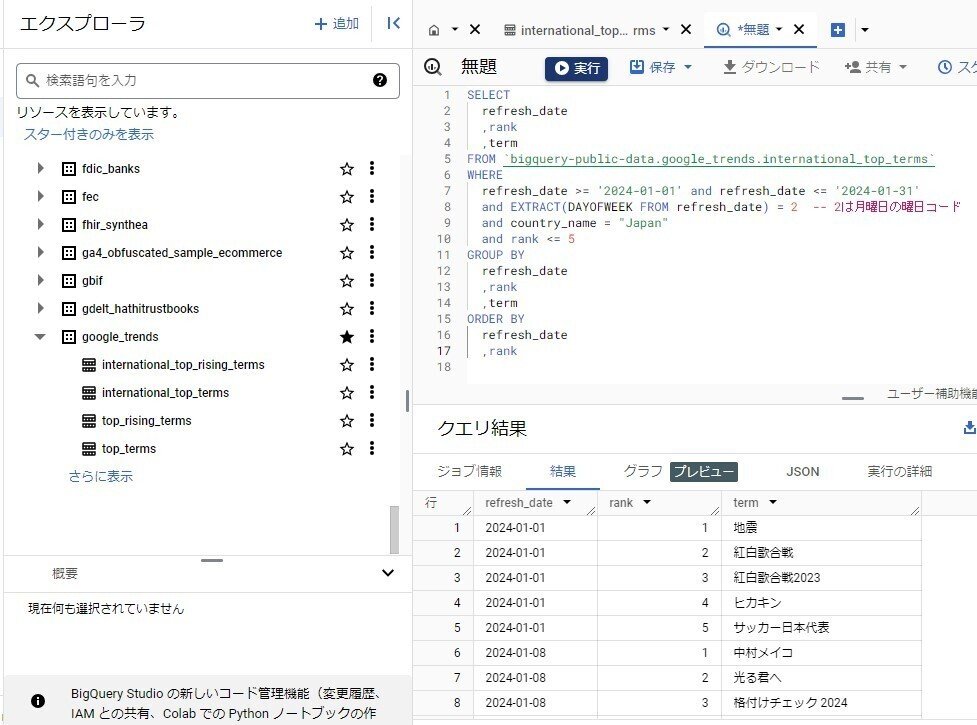
SELECT
refresh_date,
rank,
term
FROM
`bigquery-public-data.google_trends.international_top_terms`
WHERE
EXTRACT(DAYOFWEEK FROM refresh_date) = 2 -- 2は月曜日の曜日コード
and refresh_date >= '2024-01-01' and refresh_date <= '2024-01-31'
and country_name = "Japan"
and rank <= 5
GROUP BY
refresh_date,
rank,
term
ORDER BY
refresh_date DESC,
rank
GCPの概要や利用開始方法、Google社が無料公開しているデータセット使って、BigQueryで検索するための手順を、これから記載します。
Google Cloud Platform(GCP)の概要
GCPは、Googleが提供するクラウドサービスです。Webサイトの運営、データ分析、AI開発など、様々な用途で利用するサービス群です。ネットには多くのドキュメントがあり、無料トライアルやチュートリアルも充実しているので、始めやすいと思います。
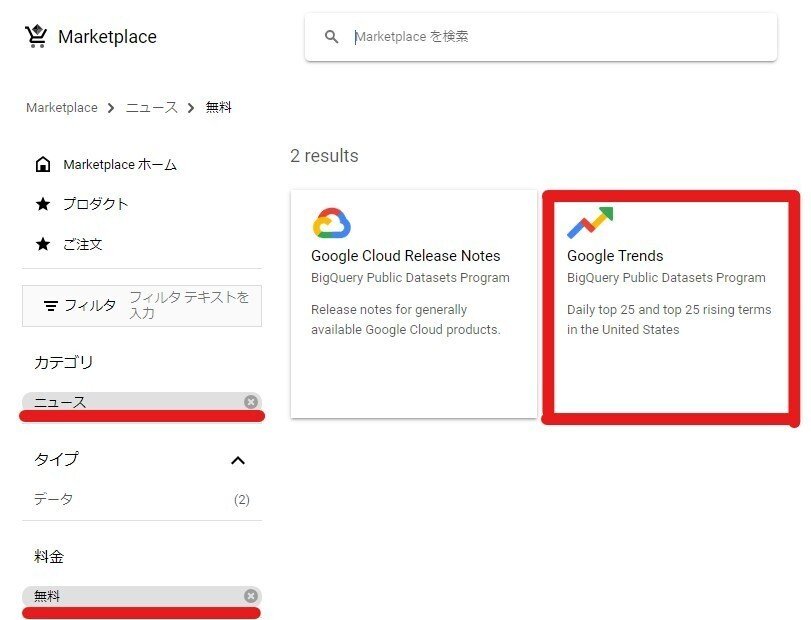
BigQueryの一般公開データセット
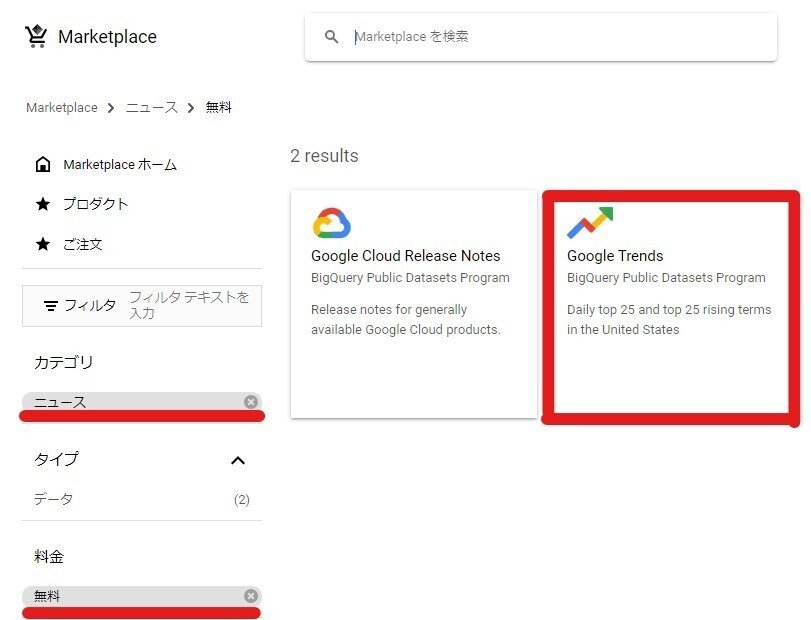
今回使用したGoogle検索トレンドワードのランキングは、Google社が提供している285種類以上の一般公開データセットに含まれているものです。これらはすべて無料で利用できます。様々なサンプルデータがあるので、データ分析のスキルを磨くのに良いサービスだと思います。
スタートガイド
GCPとBigQueryの利用を開始するには、まず、GCPアカウントを作成し、BigQueryの一般公開データセットにアクセスします。次に、利用したいデータセットを選択し、クエリを実行するだけです。詳細は、巻末に画面キャプチャを用意しましたので、よかったら見てください。
まとめ
GCPは、サービスの申し込みからサンプルデータセットの準備までが非常にスムーズ。面倒なことはないので、ぜひ皆さんもトライしてみてください。
申し込み手順からBigQueryでQuery実行するまで
最後に、GCPの申し込みからBigQueryでのクエリ実行までのプロセスを画面のキャプチャーと補足をつけます。これで今日の投稿は終わりです。この記事が皆さんの何かのお役に立てば幸いです。
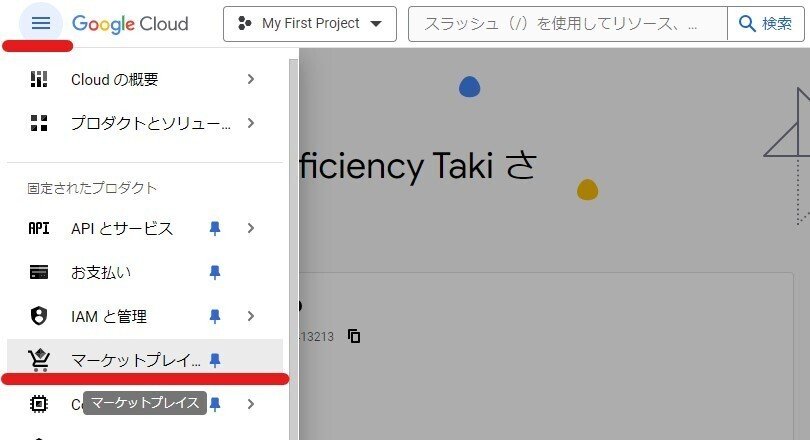
1.GCPアカウントの作成
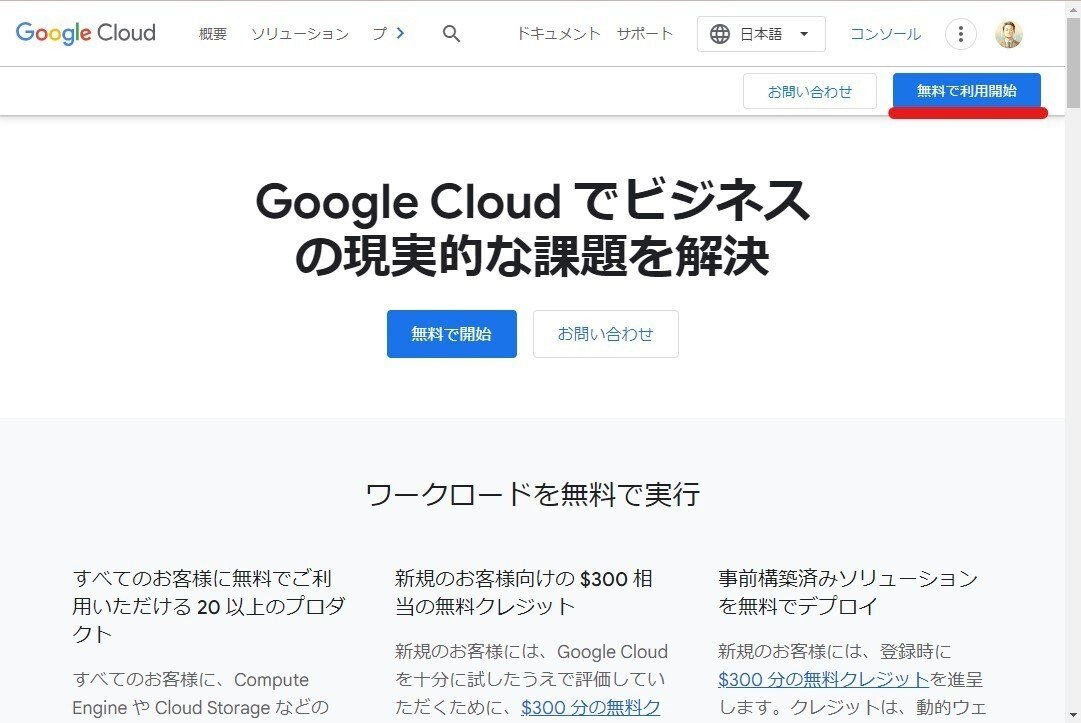
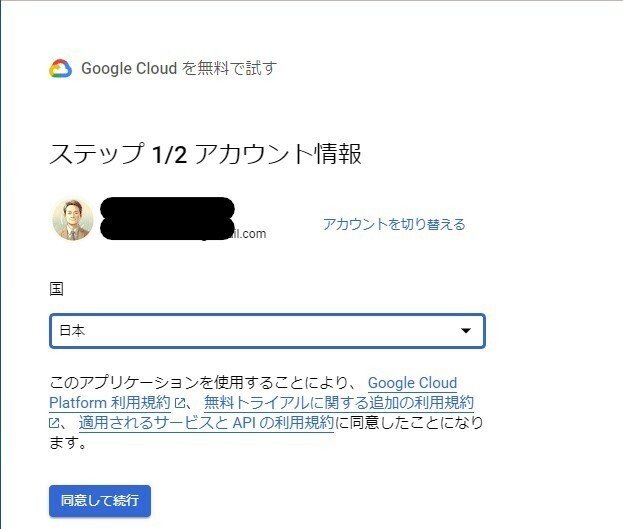
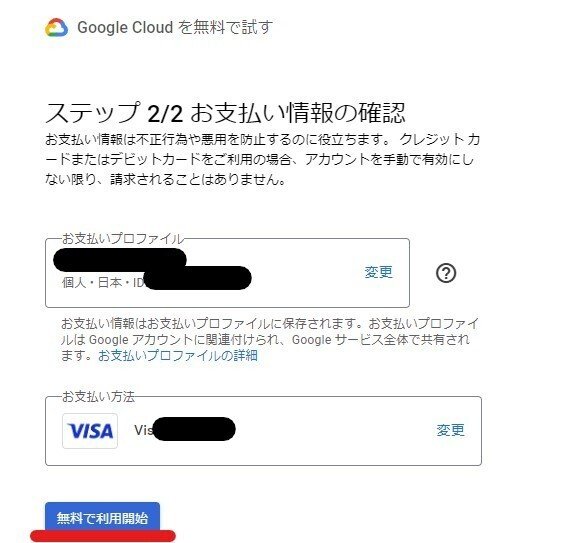
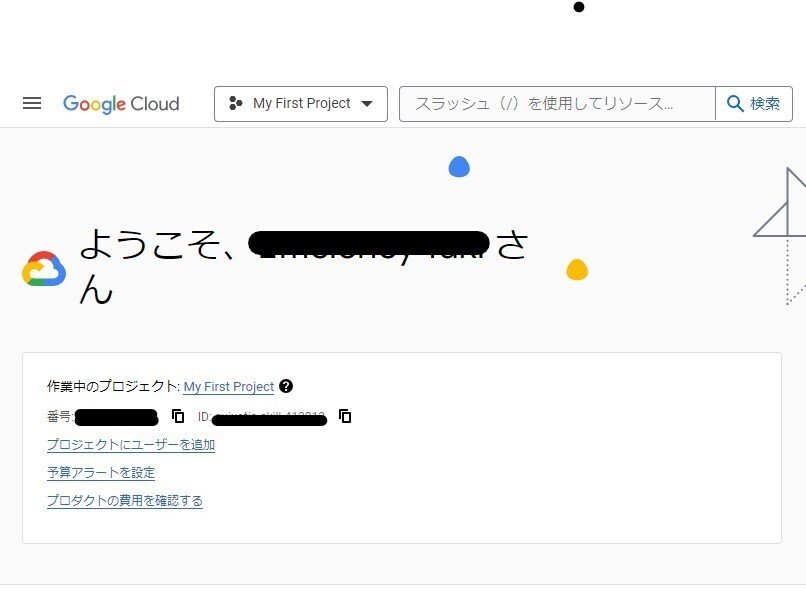
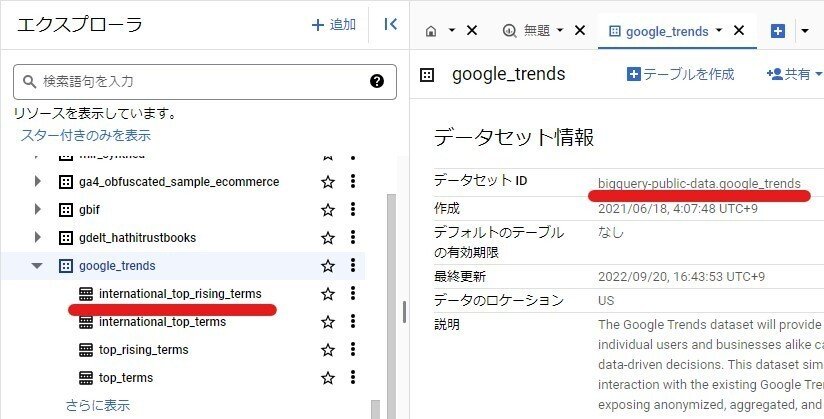
2.データセットの選択
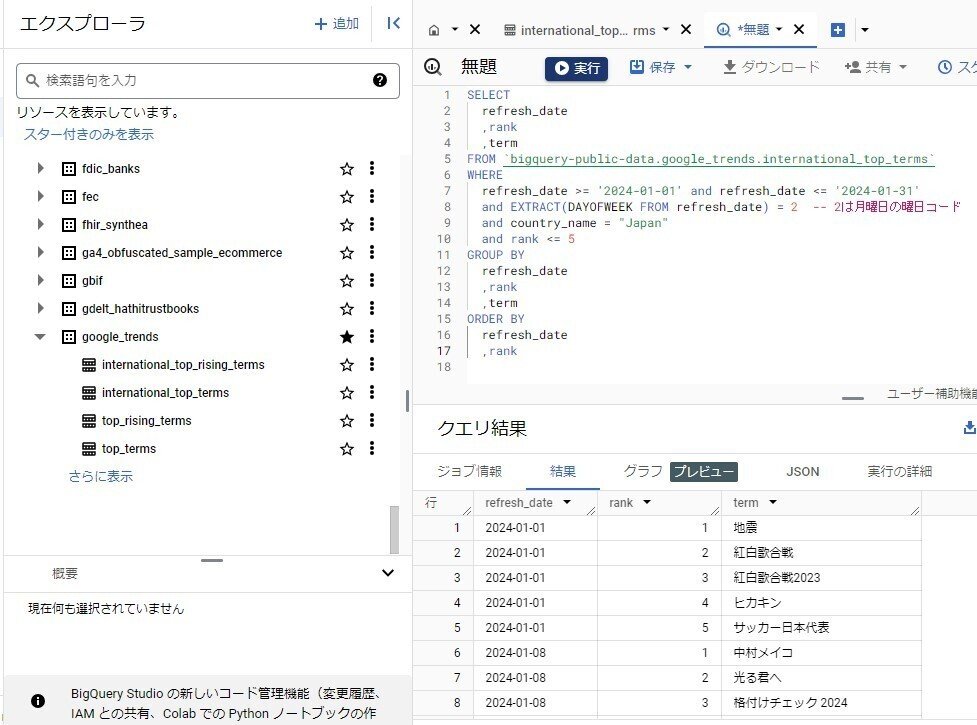
SQLクエリの実行
SELECT
refresh_date,
rank,
term
FROM
`bigquery-public-data.google_trends.international_top_terms`
WHERE
EXTRACT(DAYOFWEEK FROM refresh_date) = 2 -- 2は月曜日の曜日コード
and refresh_date >= '2024-01-01' and refresh_date <= '2024-01-31'
and country_name = "Japan"
and rank <= 5
GROUP BY
refresh_date,
rank,
term
ORDER BY
refresh_date DESC,
rank