
Baby AGIを日本語で使いたいメモ(2023/4/14)

気がづくと前回のメモから随分変わっていたのでメモをアップデート。
ちょっとbabyagiのリポジトリにアクセス。なんかファイル増えてる。
How to Useを翻訳しながら作業を進める

このスクリプトを使うには、以下の手順が必要です
git clone https://github.com/yoheinakajima/babyagi.git でリポジトリをクローンし、クローンされたリポジトリに cd します。必要なパッケージをインストールする: pip install -r requirements.txt
git clone https://github.com/yoheinakajima/babyagi.git pip install -r requirements.txt.env.example ファイルを .env にコピーします: cp .env.example .env ここで、以下の変数を設定します。
cp .env.example .envちょっと、「.env」を見てみる。
設定をまとめてできるようになって便利そうだけど、、次ヘ進む。
OPENAI_API_KEY、OPENAPI_API_MODEL、PINECONE_API_KEYの変数をセットします。
PINECONE_ENVIRONMENTの変数にPineconeの環境を設定します。
ということで、次の赤枠の部分を設定。
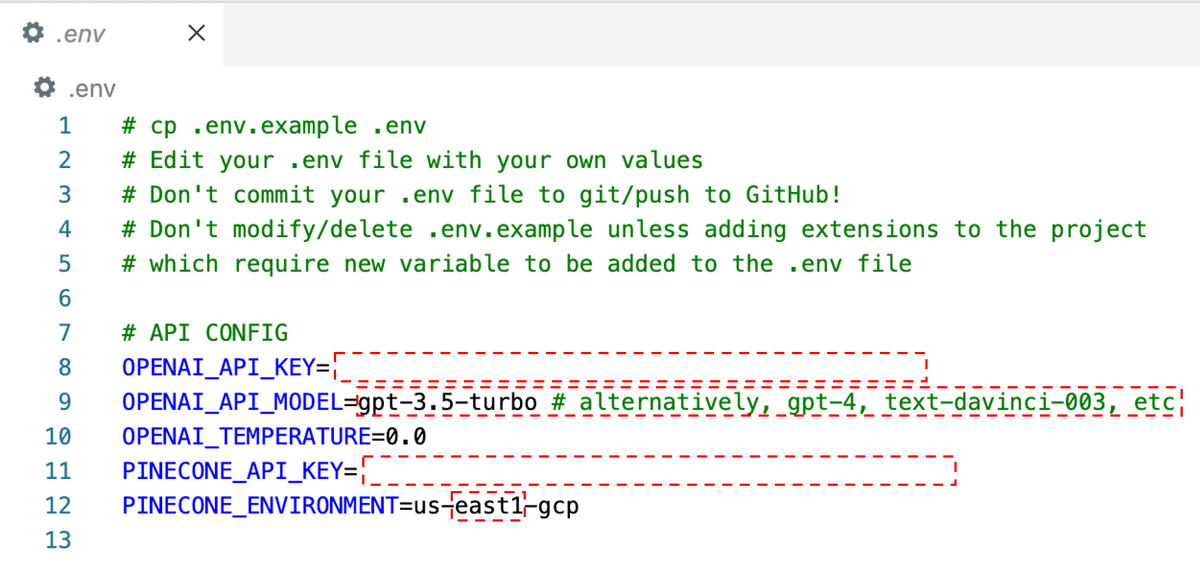
補足(API KEYはどこで入手?)
さて、OPENAI_API_KEY、PINECONE_API_KEY、PINECONE_ENVIRONMENTですが、Masayuki Abeさんのこの記事の「事前準備編」を見ていただけると良いと思います。
手元に次の3つが準備できれば大丈夫です。
「sk-」ではじまるOPENAI API KEY
「********-****-****-****-************」という書式の5つに分割された数字列のPINECONE API KEY
「us-east1-gcp」こんな感じのPINECONEのEnvironment設定
※ east1のところは、east2とか、west1だったりします。
TABLE_NAME変数にタスクの結果が保存されるテーブル名を設定します。
とあるけど、もともと書いている「baby-agi-test-table」のままで。

最初の実行時に、次のコードでPINECONEにIndexが作成される。

こんな感じで、PINECONEに「baby-agi-test-table」ができた。

(オプション) OBJECTIVE変数にタスク管理システムの目的を設定します。
(オプション) INITIAL_TASK変数にシステムの最初のタスクを設定します。
「.env」の次の部分を、

ここをまず日本語にする。

で、
スクリプトを実行する。
まあエラーが出たので、プログラムを変更。変更した方針は次のとおり。
GPTへのプロンプトを英語から日本語に
英語プロンプトのままでリストを日本語で返すように指示する(「Return the tasks as an array in Japanese」みたいに)より、全部日本語にするほうが安定した。
PINECONEのnamespaceに渡すOBJECTIVEを文字列リテラルに
Line:25 - 30
if "gpt-4" in OPENAI_API_MODEL.lower():
print(
"\033[91m\033[1m"
# + "\n*****USING GPT-4. POTENTIALLY EXPENSIVE. MONITOR YOUR COSTS*****"
+ "\n*****GPT-4は使用料が高いので注意してね!*****"
+ "\033[0m\033[0m"
)Line:99 - 103
# Print OBJECTIVE
# print("\033[94m\033[1m" + "\n*****OBJECTIVE*****\n" + "\033[0m\033[0m")
print("\033[94m\033[1m" + "\n*****解決すべき目標*****\n" + "\033[0m\033[0m")
print(f"{OBJECTIVE}")
# print("\033[93m\033[1m" + "\nInitial task:" + "\033[0m\033[0m" + f" {INITIAL_TASK}")
print("\033[93m\033[1m" + "\n初期タスク:" + "\033[0m\033[0m" + f" {INITIAL_TASK}")Line:186 - 194
# prompt = f"""
# You are a task creation AI that uses the result of an execution agent to create new tasks with the following objective: {objective},
# The last completed task has the result: {result}.
# This result was based on this task description: {task_description}. These are incomplete tasks: {', '.join(task_list)}.
# Based on the result, create new tasks to be completed by the AI system that do not overlap with incomplete tasks.
# Return the tasks as an array."""
prompt = f"""
あなたはタスク作成AIです。目標 {objective} に基づいて、実行エージェントの結果を使用して新しいタスクを作成します。
最後に完了したタスクは結果が {result} で、このタスクの説明は {task_description} です。これらは未完了のタスクです:{', '.join(task_list)}。
結果に基づいて、未完了のタスクと重複しない新しいタスクを作成し、AIシステムが完了するようにしてください。
タスクを配列として日本語で返してください。"""Line:201 - 207
# prompt = f"""
# You are a task prioritization AI tasked with cleaning the formatting of and reprioritizing the following tasks: {task_names}.
# Consider the ultimate objective of your team:{OBJECTIVE}.
# Do not remove any tasks. Return the result as a numbered list, like:
# #. First task
# #. Second task
# Start the task list with number {next_task_id}."""
prompt = f"""
あなたはタスクの優先度を決定し、フォーマットを整えるタスク作成AIです。以下のタスクを優先度順に並べ替え、整えてください:{task_names}。
チームの究極的な目標:{OBJECTIVE}を考慮してください。
タスクを削除しないでください。番号付きリストで結果を返してください。例えば:
#. 最初のタスク
#. 次のタスク
最初のタスクの番号は{next_task_id}です。"""Line:219 - 227
def execution_agent(objective: str, task: str) -> str:
# """
# Executes a task based on the given objective and previous context.
#
# Args:
# objective (str): The objective or goal for the AI to perform the task.
# task (str): The task to be executed by the AI.
#
# Returns:
# str: The response generated by the AI for the given task.
#
# """
"""
前提条件として与えられた目的と前文脈に基づいてタスクを実行します。
Args:
objective (str): AIがタスクを実行するための目標またはゴール。
task (str): AIによって実行されるタスク。
Returns:
str: AIによって生成された、与えられたタスクに対する回答。
"""Line:232 - 235
# prompt = f"""
# You are an AI who performs one task based on the following objective: {objective}\n.
# Take into account these previously completed tasks: {context}\n.
# Your task: {task}\nResponse:"""
prompt = f"""
あなたは、この目標のために1つのタスクを実行するAIです: {objective}\n.
これまでに完了したタスクを考慮してください: {context}\n.
あなたのタスク: {task}\n回答:"""Line:240 - 247
# """
# Retrieves context for a given query from an index of tasks.
#
# Args:
# query (str): The query or objective for retrieving context.
# top_results_num (int): The number of top results to retrieve.
#
# Returns:
# list: A list of tasks as context for the given query, sorted by relevance.
#
#"""
"""
与えられたクエリに対して、タスクのインデックスからコンテキストを取得します。
Args:
query (str):コンテキストを取得するためのクエリまたは目標。
top_results_num (int): 取得する上位結果の数。
Returns:
list:クエリに対するコンテキストとして関連性に従ってソートされたタスクリスト。
"""Line:249
# results = index.query(query_embedding, top_k=top_results_num, include_metadata=True, namespace=OBJECTIVE)
results = index.query(query_embedding, top_k=top_results_num, include_metadata=True, namespace="OBJECTIVE")Line:265 - 278
# Print the task list
# print("\033[95m\033[1m" + "\n*****TASK LIST*****\n" + "\033[0m\033[0m")
print("\033[95m\033[1m" + "\n*****タスクリスト*****\n" + "\033[0m\033[0m")
for t in task_list:
print(str(t["task_id"]) + ": " + t["task_name"])
# Step 1: Pull the first task
task = task_list.popleft()
# print("\033[92m\033[1m" + "\n*****NEXT TASK*****\n" + "\033[0m\033[0m")
print("\033[92m\033[1m" + "\n*****次のタスク*****\n" + "\033[0m\033[0m")
print(str(task["task_id"]) + ": " + task["task_name"])
# Send to execution function to complete the task based on the context
result = execution_agent(OBJECTIVE, task["task_name"])
this_task_id = int(task["task_id"])
# print("\033[93m\033[1m" + "\n*****TASK RESULT*****\n" + "\033[0m\033[0m")
print("\033[93m\033[1m" + "\n*****タスクの結果*****\n" + "\033[0m\033[0m")
print(result)Line:290
# namespace=OBJECTIVE
namespace="OBJECTIVE"一応、動きますね。ただ、ちょっとgpt-3.5だとstableな感じはしない。
テキスト推論から、タスク推論になるわけだから現実世界の理解が高くないとダメなわけで、するとcommon sence(common senceについてSebastien Bubeckの動画を見てね)のあるGPT-4.0だともう少し安定するかしらね。
と思って、GPT-4.0で試したけどスピードが遅すぎて試行回数が増えない。1回の思考ルーチンに、5倍から10倍時間がかかってる感じ。
自己改善モデルは、GPT-3.5-turboの方が向いていそう。
1回の精度は低くても試行回数を5倍から10倍増やせるので、結果、精度があがりそう。PDCAは、質より量。
生成AIは氷山の一角
Open AI イリヤ・サツケバーが描くAI未来
Sparks of AGI:GPT-4を用いた初期実験
マイクロソフトリサーチでML Foundationsチームをリードしている、Sebastien Bubeckの講演。
GPT-4が、常識を理解しているという話。
特別なスキルを持っていても常識がないと社会や環境には受け入れてもらえない。そういう意味で、GPT-4のすごさは「common sense(常識)」なんだよね。
8:20 – example demonstrating GPT4’s common sense
GPTはサム・アルトマンのビジョンのほんの一部
追記
動作がだいたい見えたので、今後は英語で使う。