グラボなしのPCでSD.Nextを使ってローカル環境でのAI画像生成(OpenVINO編)

画像生成AIのSD.Nextをインストールして使ってみたので、備忘録です。
これまでStable DiffusionのOpenVINO対応版を使ってきましたが、アップデートやメンテンナンスがされておりませんので、グラボなしでもローカル環境で動作しそうな画像生成AIを探したところSD.Nextにたどり着きました。
CPUだけで画像生成するとトンデモなく時間がかかるので、今回もインテルのAI加速技術OpenVINOを利用してCPU+GPUで生成します。
ちなみにSD.NextはStable Diffusionのフォーク(派生版)で、Stable Diffusionのモデル(チェックポイント)を利用することができます。
使っているPC
モバイルPC
OS:Windows11 Home
CPU:Core Ultra 155H
メモリ:32GB
グラフィックボード:なし
GPU:Intel Arc Graphics(CPU内蔵)
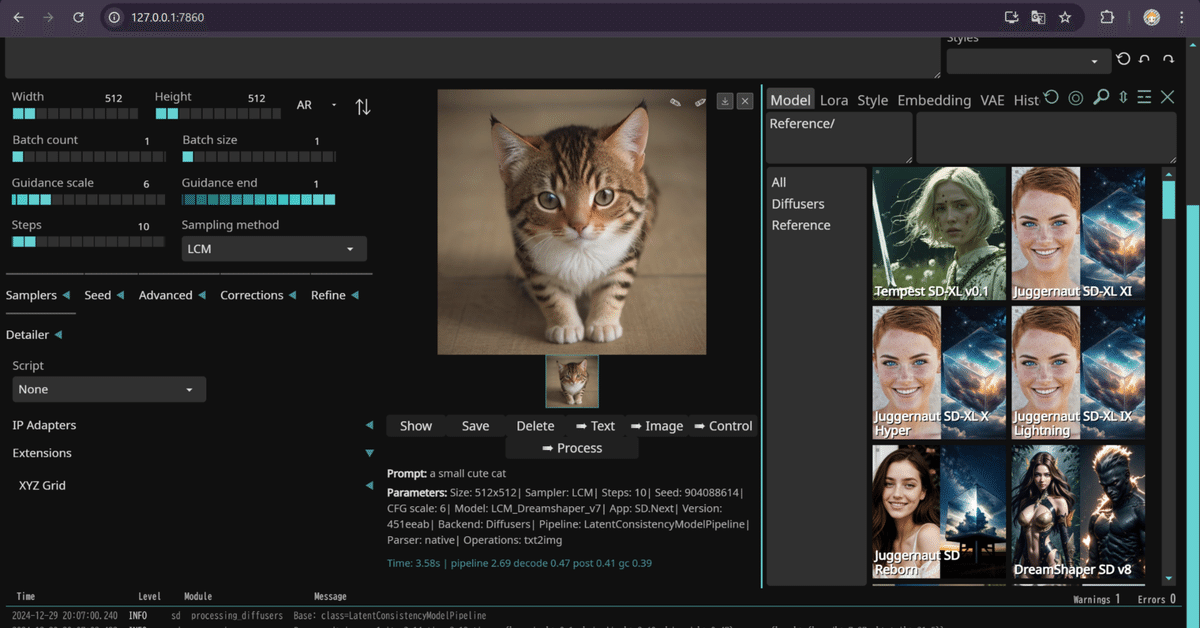
生成画像と生成時間
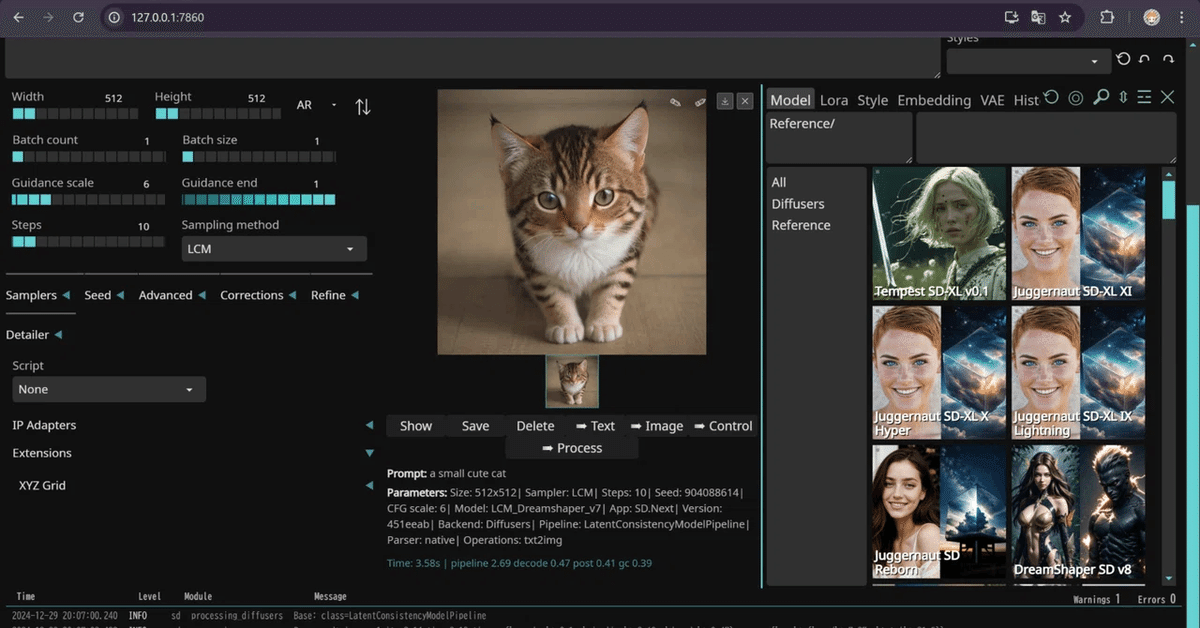
LCM_Dreamshaper_v7を使って猫画像を生成してみました。

画像サイズ:512x512
サンプラー:LCM
ステップ数:10
CFGスケール:6
生成時間:3.58秒
画像サイズはデフォルトで1024x1024ですが、エラーが出るため、512x512で作成しました。生成時間は3.58秒でした。

インストールするにあたって
SD.Nextのインストールには以下のインストールが必要となります。
グラボ搭載している場合はOpenVINOなしで動くはずです。
(このあともグラボなしを想定した記事になっています)
・Python 3.9.0~3.12.3(こちらのバージョンなら対応)
・Git
・OpenVINO
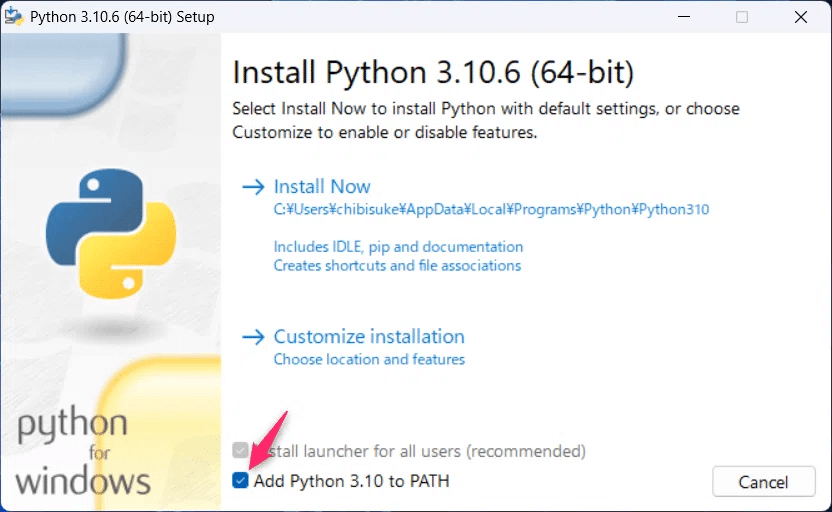
Pythonのインストール
ちょっと古いですがStable Diffusionで利用しているPython3.10.6のリンクを張っておきます。Stable Diffusionも利用したいという場合はこちらをどうぞ。
SD.Nextは3.9.0~3.12.3のバージョンならなんでも良いみたい。
注意
インストールの際、Add Python 3.10 to PATH(パスを通すところ)に必ずチェックを入れておいてください。
Gitのインストール
Gitのバージョンは最新のもので大丈夫です。
以下からダウンロードしてインストールを行ってください。
OpenVINOのインストール
コマンドプロンプトを開いて以下のコマンドを実行します。
python -m pip install openvinoこれでOpenVINOがインストールは完了です。
一応以下のコマンドを実行してOpenVINOで利用できるデバイスを確認してみてください。
python -c "from openvino import Core; print(Core().available_devices)"私のPCで上記を実行した画面

['CPU', 'GPU', 'NPU']となっておりますが、ここは環境によって異なります。
['CPU', 'GPU']だけでも表示されていればOKです。
SD.Nextのインストール
SD.Nextをインストールするためのフォルダを作ります。(どこでもいいです)
そのフォルダに入って何もないところを右クリック→ターミナルで開くを選択します。

以下のコマンドを実行します
git clone https://github.com/vladmandic/automaticSD.Nextのファイルがダウンロードされ、automaticというフォルダが作成されます。
SD.Nextの起動方法
早速起動・・・といきたいのですが、OpenVINOでの起動の場合、ちょっと細工が必要になります。起動オプションというやつです。
①automaticのフォルダに入りwebui.batというファイルを探します。
②webui.batをマウスの右ドラッグでデスクトップにでも落とします。
③ショートカットをここに作成を選択します
④作成したショートカットを右クリックしてプロパティを開きます
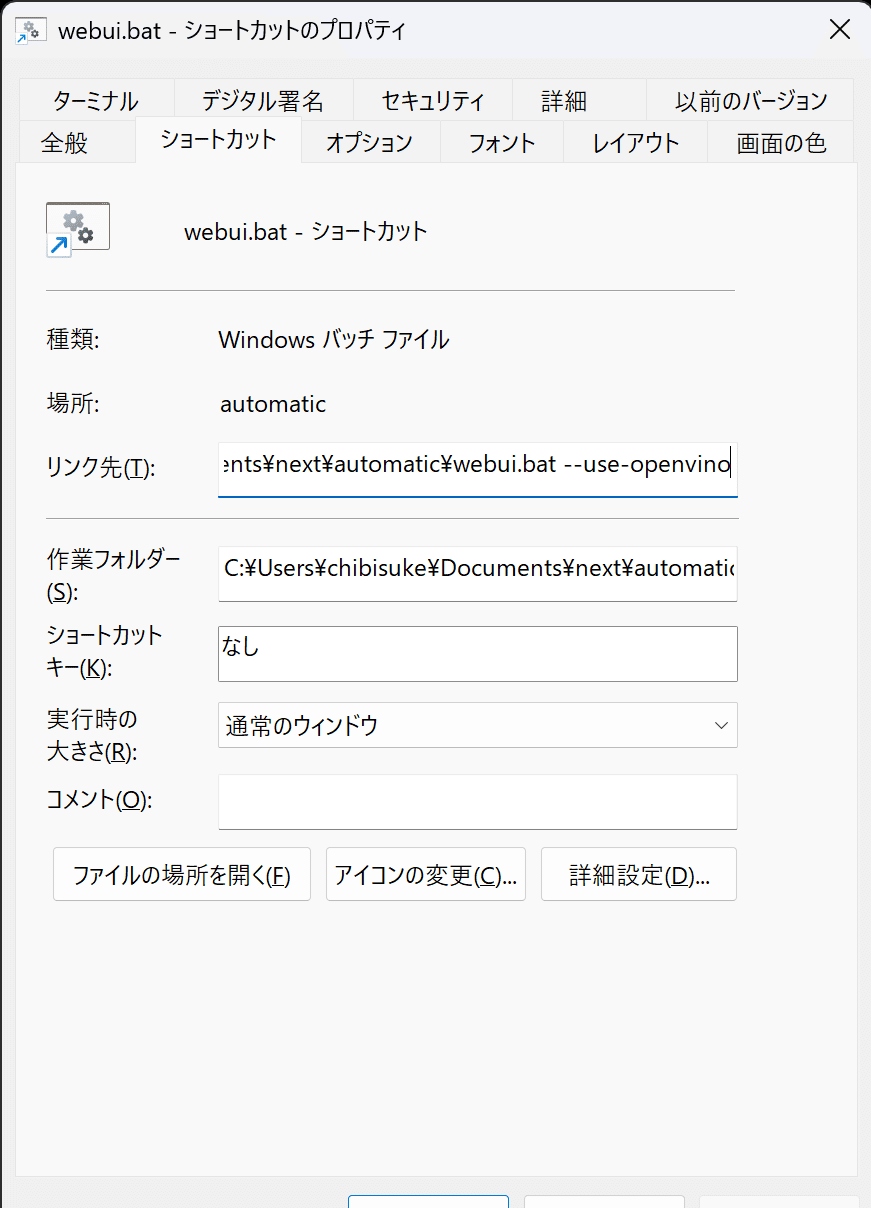
リンク先のwebui.batの後に半角スペースと以下のコマンドを入力
--use-openvinoOKを押して完了です。
起動する場合は今回作成したショートカットから起動します。webui.batを直接起動するとOpenVINOが有効になりませんので注意。
初回の場合は結構時間がかかります。
しばらく待っていると
Local URL:http://172.0.0.1:7860/
と表示されて起動が完了するので、ブラウザを開いてアクセスします。

なんか起動画面がカッコイイ

起動完了です。
SD.Nextの使い方
はじめての方向けの簡単な使い方になります。
まずはモデルを選択します。
モデルにはアニメやイラスト向きなものから実写に近いものなどさまざまなものがあります。今回はDreamShaperという実写に近いモデルで練習してみます。
モデルによって、商用などの使用が制限されている場合がありますので、利用するモデルのライセンスをご確認ください。
右下のところでLCM_DreamShaper V7をダブルクリックしてみてください。
左上にBase Modelと書かれていますが、ここがLCM DreamShaper V7になればモデルの選択が完了です。初回はダウンロードがあるため、結構時間がかかります。
つづいて生成する画像の情報を入力します
以下のように指定してみてください。
Width(画像の幅):512
Height(画像の高さ):512
Steps(ステップ数):10
Sampling Method(サンプリングメソッド):LCM
画像の大きさですが、大きな画像を作ろうとすると高いスペックが必要となります512x512くらいから始めて、大丈夫な大きさを探してみてください。
ステップ数は多くすればクオリティが上がります。
今回利用するLCMというサンプラーは比較的少ないステップ数でもクオリティの高い画像が生成ができます。

つづいてプロンプトを入力します
Prompt(プロンプト):作りたい画像の説明を入力します
Negative Prompt(ネガティブプロンプト):こんな画像は嫌だということを入力します
プロンプトについてはあまり詳しくないので検索して調べるか、AIにでも聞いてください。
今回は練習なのでPromptに「a small cute cat」と入力しました。
右にあるGenarateを押すと生成を開始します。

しばらく待つと猫の画像が生成されました。
あとはCivitaiやTensor.artなどからお好きなモデルをダウンロードして試してみてください。
まずはSD1.5系をお試しください。
SD.Nextの各フォルダ
生成した画像はどこに保存される?
automatic\outputs\text
CivitaiやTensor.artなどからダウンロードしたモデルはどこに入れる?
automatic\models\Stable-diffusion
お疲れ様でした。