
python 入門: webスクレイピング (すべてのイラスト屋を集まり)

データサイエンティストになるために、解析だけでなくて、データを収集しなければなりません。いろいろな手法があり、一般的にwebスクレイピングの技術を使用します。Pythonでは、webスクレイピングをというと、BeautifulSoupのモジュールは一般的です。 BeautifulSoupは、ウエブサイトのHTMLを簡単に分解して、希望の情報を取り抜けます。この記事では、BautifulSoupを使用し、イラスト屋の画像を収集しています。すべてのコードはGoogleColabのノートブックにあり、自由に参考してください。
ステップ 1 対象のページを確認する
スクレイピングを行う前に、対象のウエブサイトに、サイトのHTMLを検証しなければなりません。今回に、イラスト屋のサイトを使用し、ページで右クリックし、オプション画面を開くと、検証を押してください。右に検証画面を表示します

ページのHTMLの内容を見えますね。今回に、画像の情報が欲しいです。ページで画像の上で検証をすれば、この画像のHMLTの情報を移動できます。

このペースを確認して、それぞれの画像は、divのboxのclassに入れています。BeautifulSoupはその情報を読み込み、画像HTMLだけを収集します。そのために、最初にrequestというモジュールを使用し、サイトのURLを検索して、結果のデータをBeautifulSoupに入り込み、一般的にsoupという名を付けます。次に、「soup.find_all() 」という関数は、htmlの中でタブやクラスを検索して、情報を収集します。今回の場合は、「div」のタグと 「box」のクラスを記入して、イラスト屋のページの画像情報を集めります。下記のコードでは、これを行います。
import requests
from bs4 import BeautifulSoup
url="https://www.irasutoya.com/"
r= requests.get(url)
data=r.text
soup=BeautifulSoup(data)
boxs=soup.find_all('div', attrs={'class': 'box'})
print(boxs[0])例のboxのhtml

ステップ2画像をダウンロード
次に、画像のデータを集まりたい。前のコードの入力では、hrefがあり、それを押し、Thumbnailの画像を表示されます。しかし、もっと大きな画像が欲しい場合は、画像のページに移動して、そこで画像のhrefを取り抜け、ダウンロードを行います。下記にその通りをしましょう。
hrefを取り抜くために、beatufullsoulの「.find()」と「.get()」の関数を使用します。最初に、「find()」はタグを検索した後で「.get()」は希望の情報を取り抜く。
#ホームページから画像のページの取り抜く
Ilra_URL=boxs[0].find("a").get("href")
print(Ilra_URL)次に、新しいページでは、boxsを収集することをもう一度に行うが、今回に、大きな画像のhrefとalt(画像の名前)の情報を取り抜く
r= requests.get(Ilra_URL)
soup_I=BeautifulSoup(r.text)
img_html=soup_I.find("div", attrs={'class': "entry"} ).find("a")
href=img_html.get("href")
print(href)
alt=img_html.find("img").get("alt")
print(alt)この情報があれば、requestsのモジュールとPythonの標準の「open().write()」の機能を使用し、画像をダウンロードできます。下記のコードでは、画像をダウンロードして、結果をも表示します。
#ダウンロード
r = requests.get(href, allow_redirects=True)
open(f'{alt}.png', 'wb').write(r.content)
#プロット
import cv2
import matplotlib.pyplot as plt
img=cv2.imread(f'{alt}.png')[:,:,::-1]
plt.imshow(img)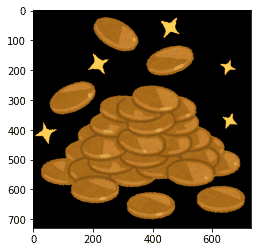
ステップ3 複数のペースを扱い
ヨッシー、画像をダウンロードできます。しかし、それぞののページは、枚数の限界があり、イラスト屋の場合は、25枚です。25枚以上の画像をダウンロードしたいなら、次のページのURLを取り抜けなければなりません。イラスト屋の場合は運があり、ページの後ろに「次のページ」のバートンを存在します。前のように、タグの名とクラスの名を検証画面で検索して、下記のコードで、新しいURLを取り抜きます
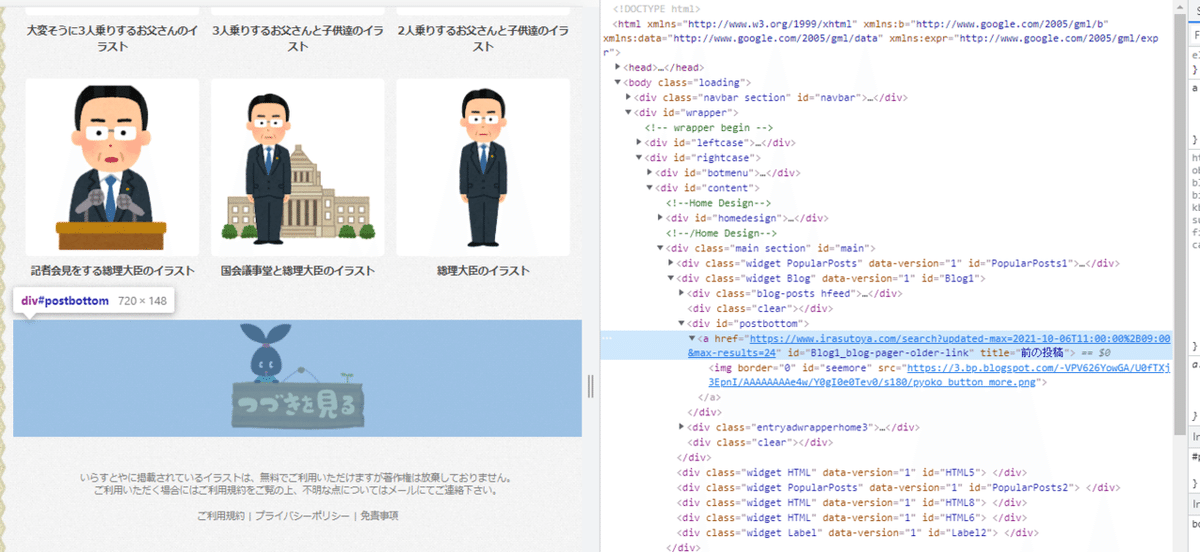
#ホームページの場合
bottom_html=soup.find("div", attrs={'id': "postbottom"})
nextpage_url=bottom_html.find("a").get("href")
print(nextpage_url)
#新しいページの場合は、
r= requests.get(nextpage_url)
soup_np=BeautifulSoup(r.text)
soup_np.find("span", attrs={"id":"blog-pager-older-link"}).find("a").get("href")すべての画像を収集をしましょう
たくさんな画像をダウンロードするために、コードをちょっと整えるべきです。それをしないと、コードは汚くなります。汚いコードは使いにくいですね。それを避けるために、画像のHMTLと画像のダウンロードを関数を作りましょう。
def GetIYImage(img_url,saveloc):
r= requests.get(Ilra_URL)
soup_I=BeautifulSoup(r.text)
img_html=soup_I.find("div", attrs={'class': "entry"} ).find("a")
href=img_html.get("href")
#print(href)
alt=img_html.find("img").get("alt")
#print(alt)
r = requests.get(href, allow_redirects=True)
open(f'{saveloc}/{alt}.png', 'wb').write(r.content)
def GetImageBoxes(url):
r= requests.get(url)
data=r.text
soup=BeautifulSoup(data)
boxs=soup.find_all('div', attrs={'class': 'box'})
return boxs, soupすべての画像をダウンロードするために、For文( For loop)を使用します。そして、無限に実行しないように、while文 (While Loop)を利用して、希望の枚数を設定しましょう。下記のコードには、残っている説明するべきのことは、「Firstpage」という変数です。イラスト屋の最初のページと普通のページの「次のページのバートン」がちょっと違いますので、特別の扱いしなければなりません。
url="https://www.irasutoya.com/"
r= requests.get(url)
data=r.text
soup=BeautifulSoup(data)
boxs=soup.find_all('div', attrs={'class': 'box'})
#保存策
saveloc="irasuoya"
#os.makedirs(saveloc) #ない場合は新しいFolderを作ります
#最初のページの設定
Firstpage=True
#ダウンロードの限界
totaldownload=100
i=0
while i <=totaldownload:
boxs,soup=GetImageBoxes(url)
print(i,url,len(boxs))
#First page
if Firstpage:
#Update URL
bottom_html=soup.find("div", attrs={'id': "postbottom"})
url=bottom_html.find("a").get("href")
Firstpage=False
else:
#Update URL
r= requests.get(url)
soup_np=BeautifulSoup(r.text)
url=soup_np.find("span", attrs={"id":"blog-pager-older-link"}).find("a").get("href")
for box in boxs:
#エラーがあれば、停止しないために、tryとexcpetを使用します。
try:
Ilra_URL=box.find("a").get("href")
GetIYImage(Ilra_URL,saveloc)
i+=1
except:
print("Error")
print(Ilra_URL)
pass #停止しなくて、次のLoopを行う