
はじめてのKeras 2層Affine構造のAIモデルで回帰を行うPythonソースコードの解説

Kerasの日本語ドキュメント
Kerasの日本語ドキュメントを探していたら、下記を見つけました。
ファイルの拡張子が"md"となっているものを左クリックすると、ドキュメントを参照することができます。
ドキュメントの本体は、sourcesディレクトリ以下にあります。
GitHubは、プログラムのソースコードを管理するものだと思い込んでいましたが、ドキュメントの管理にも使えるとは驚きました。
2層Affine構造のAIモデルで回帰を行うPythonプログラムのソースコード
2層Affine構造のAIモデルで回帰を行うPythonプログラムのソースコードを下記に示します。
import numpy as np
import pandas as pd
import argparse
import time
import matplotlib.pyplot as plt
import os
import keras
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint
# Data format converter
# Label: 'x' or 'y'
# Data: Neural Network Console training/validation data(DataFrame形式)
def DataFormatConv(Label, Data):
# Labelで指定された文字を含む列を抽出
OutData = Data.filter(like = Label, axis = 'columns')
# DataFrameをndarrayに変換
OutData = OutData.to_numpy()
return OutData
def main():
# 下記のエラー対応
# OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5 already initialized.
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# コマンドライン引数の処理
parser = argparse.ArgumentParser(description = '2 Affine neural network training and validation program')
parser.add_argument('--e', type = int, default = 10, help = 'Number of Epoch(Default: 10)')
parser.add_argument('--b', type = int, default = 64, help = 'Batch size(Default: 64)')
parser.add_argument('--t', required = True, default = 'training.csv', help = 'Training data file name(Default: training.csv)')
parser.add_argument('--v', required = True, default = 'validation.csv', help = 'Validation data file name(Default: validation.csv)')
parser.add_argument('--m', default = 'Best_model.h5', help = 'Minimum val_loss model name(Default: Best_model.h5)')
parser.add_argument('--o', default = 'Result_model_validation.csv', help = 'File name for best model evaluation results(Default: Result_model_validation.csv)')
args = parser.parse_args()
print('Training data: ', args.t)
print('Validation data: ', args.v)
# csvファイルのデータをDataFrameに入力
TrainData = pd.read_csv(args.t, encoding = 'utf-8')
ValidData = pd.read_csv(args.v, encoding = 'utf-8')
# 学習データをKeras用に成形
TrainDataX = DataFormatConv('x', TrainData)
TrainDataY = DataFormatConv('y', TrainData)
# 評価データをKeras用に成形
ValidDataX = DataFormatConv('x', ValidData)
ValidDataY = DataFormatConv('y', ValidData)
# 2層Affine構造のニューラルネットワークを構築
TestNN = keras.models.Sequential()
TestNN.add(Dense(100, input_dim = 4, activation = 'relu')) # 入力層(4) + Affine_1(100) + ReLU_1
TestNN.add(Dense(4, activation = 'linear')) # Affine_2(4)
TestNN.summary()
# 学習プロセスの設定
TestNN.compile(loss = 'mean_squared_error', optimizer = 'adam', metrics = ['mae']) # 損失関数
# 学習時間の計測開始
FitTimeStart = time.perf_counter()
# コールバックの設定
CheckPointPath = args.m
CallBack = ModelCheckpoint(filepath = CheckPointPath, monitor = 'val_loss', verbose = 1, save_best_only = True, mode = 'min', save_weights_only = False, save_freq = 'epoch')
# AIモデルの学習
Epochs = args.e
BatchSize = args.b
History = TestNN.fit(x = TrainDataX, y = TrainDataY, batch_size = BatchSize, epochs = Epochs, validation_data = (ValidDataX, ValidDataY), shuffle = True, callbacks = [CallBack])
# 学習時間の計測終了
FitTimeEnd = time.perf_counter()
# 学習時間
print()
print('学習時間: ', '{:.2f}'.format(FitTimeEnd - FitTimeStart), '[s]')
print()
# 保存されたHDF5形式の最小val_lossモデルを読み込み
ValidModel = keras.models.load_model(CheckPointPath)
# 最小val_lossモデルを評価
Result = ValidModel(ValidDataX)
# EagerTensorをDataFrame形式に変換
TmpResult = pd.DataFrame(Result)
# 最小val_lossモデルの評価結果をファイルに保存
TmpResult.to_csv(args.o, index = False)
print('Validation results: ', args.o)
# 損失をグラフ表示
plt.plot(range(1, Epochs + 1), History.history['loss'], label = 'Loss')
plt.plot(range(1, Epochs + 1), History.history['val_loss'], label = 'Val Los')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.yscale('log')
plt.ylim(None, 10**6)
plt.grid(axis = 'x', which = 'major')
plt.grid(axis = 'y', which = 'both')
plt.show()
if __name__ == '__main__':
main()上記のPythonプログラムにおいて、主な構成は下記の通りです。
Pythonプログラムの主な構成
ライブラリのインポート
DataFormatConv関数
Neural Network Console用の学習データおよび評価データをKerasを使用したAIモデル向けのデータフォーマットに変換
main関数
Pythonのエラー対応
Pythonプログラム実行時の引数処理
学習データおよび評価データの用意
2層Affine構造のAIモデルの構築
学習時間の計測準備
コールバック関数の設定
AIモデルの学習処理
学習時間の計測
最適なAIモデルのパラメータの読み込み
最適なAIモデルの評価
評価データのファイル出力
各種エラーのグラフ表示
Pythonプログラムの実行方法
上記のPythonプログラムをfilename.pyというファイルに保存した場合、実行方法は下記となります。
> python filename.py --t training.csv --v validation.csv上記において、training.csvはNeural Network Console用の学習データを、validation.csvはNeural Network Console用の評価データを指定します。
また、Pythonプログラム実行時のオプション一覧は、下記となります。
Pythonプログラム実行時のオプション一覧
--e: Epochを指定(デフォルト値: 10)
--b: バッチサイズを指定(デフォルト値: 64)
--t: 学習データを指定(指定必須のオプション)
--v: 評価データを指定(指定必須のオプション)
--m: 最適モデル保存ファイル名(デフォルト値: Best_model.h5)
--o: 最適モデルの評価結果保存ファイル名(デフォルト値: Result_model_validation.csv)
Pythonプログラムの詳細解説
上記の2層Affine構造のAIモデルで回帰を行うPythonプログラムにおいて、main関数内のポイントとなりそうな箇所を解説します。
学習データおよび評価データの用意
# csvファイルのデータをDataFrameに入力
TrainData = pd.read_csv(args.t, encoding = 'utf-8')
ValidData = pd.read_csv(args.v, encoding = 'utf-8')
# 学習データをKeras用に成形
TrainDataX = DataFormatConv('x', TrainData)
TrainDataY = DataFormatConv('y', TrainData)Neural Network Console用の学習データおよび評価データを保存したファイルからそれぞれのデータを読み込み、Kerasを使用したAIモデル用のデータフォーマットに変換しています。
2層Affine構造のAIモデルの構築
# 2層Affine構造のニューラルネットワークを構築
TestNN = keras.models.Sequential()
TestNN.add(Dense(100, input_dim = 4, activation = 'relu')) # 入力層(4) + Affine_1(100) + ReLU_1
TestNN.add(Dense(4, activation = 'linear')) # Affine_2(4)
TestNN.summary()
# 学習プロセスの設定
TestNN.compile(loss = 'mean_squared_error', optimizer = 'adam', metrics = ['mae']) # 損失関数上記の記述により、Neural Network Consoleでの下記の構造のAIモデルを構築しています。
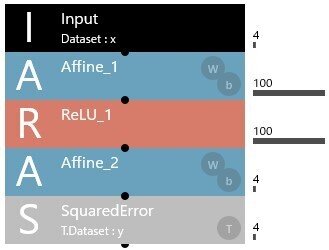
今回は、Kerasのシーケンシャルモデルと呼ばれるものを使用しています。
下記のソースコードがシーケンシャルモデルの変数を作成している箇所です。
TestNN = keras.models.Sequential()Kerasのシーケンシャルモデルは、必要なAIモデルのレイヤ(層)をaddにより追加することで、AIモデルを構築します。
上記のソースコードでは、Dense(Affine)を2つaddしています。
1つ目のDense(Affine_1に相当)では、活性化関数としてReLUをactivationで指定しています。
また、2つ目のDense(Affine_2に相当)では、活性化関数を使用しないのでactivation = 'linear'としています。
Neural Network ConsoleでのSquaredErrorは、Kerasではcompileの引数であるlossで指定します。
上記の例では、loss = 'mean_squared_error'としています。
また、optimizer = 'adam'は、AIモデルの学習時に使用される最適化アルゴリズムにAdaptive Moment Estimation(ADAM, 適応的モーメント推定)を指定しています。
ADAMの詳細については分かりませんが、Neural Network ConsoleでもADAMを最適化アルゴリズムに使用しています。
そして、metrics = ['mae']ですが、学習したAIモデルの評価に使用する精度指標(Metrics)としてMean Absolute Error(MAE, 平均絶対誤差)を指定しています。
これについては、回帰を行う場合は、この設定にするのが良いそうです。
summaryは、Python実行時に下記のAIモデルの構造に関する情報を出力する関数です。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 100) 500
dense_1 (Dense) (None, 4) 404
=================================================================
Total params: 904
Trainable params: 904
Non-trainable params: 0従って、summaryは無くても動作に影響はありません。
コールバック関数の設定
コールバック関数とは、別の関数の実行中に、予め設定された条件が成立した場合に実行される関数です。
CallBack = ModelCheckpoint(filepath = CheckPointPath, monitor = 'val_loss', verbose = 1, save_best_only = True, mode = 'min', save_weights_only = False, save_freq = 'epoch')今回、コールバック関数を設定した目的は、AIモデルの学習中において、評価データを使用した場合の誤差が最小となる(つまり、最も性能の良い)AIモデルの内部パラメータを保存することです。
このAIモデルの内部パラメータは、後で呼び出して評価を行います。
コールバック関数で設定された各引数の意味は、以下の通りです。
filepath = CheckPointPath
AIモデルの内部パラメータを保存するファイルを指定します
monitor = 'val_loss'
監視する変数を指定します
今回は、評価データを使用した場合の誤差が最小となる条件を判定するためval_loss(評価データに対する誤差)を指定しています
verbose = 1
AIモデルの学習時に下記のログを出力します
Epoch ?: val_loss improved from ? to ?, saving model to ?
save_best_only = True
val_lossの値が最も小さい場合のAIモデルの内部パラメータを保存します
mode = 'min'
save_best_only = True かつ monitor = 'val_loss' の場合はminを設定するようです
save_weights_only = False
条件成立時はAIモデル全体(内部パラメータ含む)が保存されます
save_freq = 'epoch'
各Epoch毎に評価されます
ちなみに、上記に挙げたKerasの日本語ドキュメントでは、save_freqではなくperiodと記載されています。
しかし、periodを指定するとWarningが出力されますので、注意が必要です。
AIモデルの学習処理
History = TestNN.fit(x = TrainDataX, y = TrainDataY, batch_size = BatchSize, epochs = Epochs, validation_data = (ValidDataX, ValidDataY), shuffle = True, callbacks = [CallBack])fitの実行でAIモデルの学習を行います。
各引数の意味は、次の通りです。
x = TrainDataX
xには学習データを代入します
y = TrainDataY
yには学習データに対する教師データを代入します
batch_size = BatchSize
AIモデルの学習に使用するバッチサイズを指定します
epochs = Epochs
Epoch数を指定します
validation_data = (ValidDataX, ValidDataY)
AIモデルの評価に使用する評価データと評価データに対する教師データを指定します
shuffle = True
学習データのシャッフルを有効にします
callbacks = [CallBack]
事前に設定したコールバック関数を代入します
AIモデルの学習中は、コールバック関数で指定した通り、評価データに対する教師データと比べて誤差が最小となるAIモデルと内部パラメータを保存します。
最適なAIモデルのパラメータの読み込み
# 保存されたHDF5形式の最小val_lossモデルを読み込み
ValidModel = keras.models.load_model(CheckPointPath)AIモデルの学習中に保存された評価データに対する教師データと比べて誤差が最小となったAIモデルと内部パラメータを読み込みます。
最適なAIモデルの評価
# 最小val_lossモデルを評価
Result = ValidModel(ValidDataX)評価データに対する教師データと比べて誤差が最小となったAIモデルの再評価を行います。
評価データは、変数Resultに代入されます。
評価データのファイル出力
# EagerTensorをDataFrame形式に変換
TmpResult = pd.DataFrame(Result)
# 最小val_lossモデルの評価結果をファイルに保存
TmpResult.to_csv(args.o, index = False)AIモデルの評価データをcsvファイルに出力するため、一旦、DataFrame形式に変換した後、ファイルに出力します。
この評価データを使ってまとめた記事が、下記となります。
おまけ バッチサイズとEpochについて
AIモデルの学習方法にミニバッチ学習というものがあります。
ミニバッチ学習は、用意した学習データの一部を抜粋し、その抜粋した学習データを使用してAIモデルの学習を行う方法です。
例えば、学習データが30個、バッチサイズが10個である場合、ミニバッチ学習は下記のように実行されます。
学習データが30個、バッチサイズが10個である場合のミニバッチ学習
学習1回目: 学習データから10個を抜粋し、AIモデルの学習を実行
学習2回目: 残る20個の学習データから10個を抜粋し、AIモデルの学習を実行
学習3回目: 残る10個の学習データを使用し、AIモデルの学習を実行
上記の3回目が終了した時点で、1 Epochとなります。
Neural Network Consoleおよび今回作成したKerasを使用したAIモデルの学習は、ミニバッチ学習を使用しています。
ちなみに、学習データの個数がバッチサイズで割り切れない場合の動作については、良く分かりません。