【機械学習初心者】科学論文を自然言語処理で分析してみました

はじめまして!今回は、米国国立医学図書館(NLM)が作成するPubmedという医学・生物学文献データベースから抽出した科学論文を、機械学習の自然言語処理で分析してみました。論文をトピックごとに分類できるのか、時代ごとに内容が変化しているのか、論文同士がどう似通っているか、などを調べました。
開発環境
MacBook Air
Google Colaboratory
Python 3.6.9
ウェブスクレイピングで論文抽出
興味のある以下の二つのテーマに関する論文を、Pubmed上でキーワード検索で絞り、PythonのBeautifulSoupというスクレイピングライブラリを用いて、各論文の発行年、タイトル、アブストラクトを抽出しました。
1)生物の発生が重力によってどのような影響を受けているか(1920年から2021年8月11日まで。使用したキーワード:development AND gravity OR 発生、重力に関するキーワード多数。計3737報)
2)ノーベル賞受賞者の山中伸弥先生が作成したiPS細胞が再生医療の研究でどのような発展を遂げてきたのか(iPS細胞が発表された2016年から2021年8月7日まで。使用したキーワード:ips cells AND therapy。計9230報)
import requests
import csv
import pandas as pd
from bs4 import BeautifulSoup
# はじめに、ベースとなる1ページ目のURLを定義
# このURLはテーマ2用
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term="
target_word = "ips+cells+therapy&filter=simsearch1.fha&filter=dates.2006-2021"
end_url = "&format=abstract&size=200"
page = "&page="
def scraping(url):
# urlのデータを読み込み、BeautifulSoupによるパースを行う
response = requests.get(url)
soup = BeautifulSoup(response.text, "html5lib")
# データの入ったボックスを取得して変数boxesに代入
boxes = soup.find_all("article", class_="article-overview")
results = []
number = 0
for box in boxes:
number += 1
# 発行年の抽出
# Bookshelf IDの入っている<span class='identifier bookshelf'>タグのある論文の発行年の情報が他の論文と異なる部分にあるため、
# このタグが入っている場合のみ、yearに"add_year"を代入するように条件文を設定
bookshelf = box.find_all('span', class_='identifier bookshelf')
if len(bookshelf)==0:
year = box.find("span", class_="cit")
year = year.text
#以下の多様なフォーマットの情報から発行年だけを抽出
#1991;117:3-23. doi: 10.1111/j.1469-8137.1991.tb00940.x.
#2000;25(10):1985-95. doi: 10.1016/s0273-1177(99)01007-8
#1976;14:47-55.
#1998 Nov;28(1-2):44-51.
#1996 Dec;440:70-4. doi: 10.17660/actahortic.1996.440.13.
#2020 Oct 2;25(10):516-517. doi: 10.12968/bjcn.2020.25.10.516.
if year[0:4].isdigit() == True:
year = year[0:4]
#以下の多様なフォーマットの情報から発行年だけを抽出
#May-Jun 1993;27(3):15-8.
#Jun-Aug 2003;24(3-4):151-60.
#Aug-Nov 2001;49(3-10):345-63. doi: 10.1016/s0094-5765(01)00111-4.
else:
year = year[8:12]
else:
year = "add_year"
#タイトルの抽出
title = box.find("h1", class_="heading-title").find("a")
title = title.text
title = title.strip()
print(str(number) + ". " + title)
#アブストラクトの抽出
#アブストラクトのタブがない場合はabstに"add_abstract"を代入
abst = box.find("div", class_="abstract-content selected")
if abst==None:
abst = "add_abstract"
else:
abst = abst.find("p")
abst = abst.text
abst = abst.strip()
print(abst)
article = [year, title, abst]
results.append(article)
return results
#各ページのurlのリストを作成。iはページ番号
url_list = []
for i in range(1, 48): #9,230 報なので
url = base_url + target_word + end_url + page + str(i)
url_list.append(url)
print(url_list)
#発行年、タイトル、アブストラクトのデータをまとめてarticlesに格納
articles = []
page_num = 0
for each_url in url_list:
page_num += 1
print("page " + str(page_num))
scraped = scraping(each_url)
articles += scraped
#articlesのリストを出力して確認
num =0
for yr, ttl, abs in articles:
num += 1
print(str(num) + '. ' + "{} Title:{} Abstract:{}".format(yr, ttl, abs))
#リスト型からdataframe型に変更し、csvで保存
articles = pd.DataFrame(articles, columns=["year", "title", "abstract"])
print(articles.head())
articles.to_csv("./ips_therapy.csv", index=False)この作業により、一見一様に見える論文リストのフォーマットが実は結構バラバラであることに気づきました。目的の情報が入っているタブの中に余計なタブが入っていたことで、途中でプログラムが停止したりしたのですが、それを回避する条件文を設定するなど工夫が必要でした。
また、テーマ1に関しては論文の検索ワードの選定が甘かったと反省しました。gravityには「重大さ」などの意味もあったのですね。検索ワードを足して抽出し直す作業が必要でした。
ともあれ、論文の抽出には成功しました!後は一部情報が抜けてる部分を手動で入力したり、ギリシャ文字の文字化けを修正する程度で済みました。
論文データの前処理
次に、自然言語処理に使えるよう論文データの加工を行いました。
英語の自然言語処理のライブラリNLTK(Natural Language Toolkit)のインポート
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')NLTKによる以下の各自然言語処理のプロセスは、以下の記事を参考にさせていただきました。
英語の自然言語処理を学んだのでまとめてみた
テキストに含まれている記号の確認
import pandas as pd
#論文データの読み込み
data = pd.read_excel("./dev_g_08112021.xlsx")
# ',! - [] などの記号の入ったタイトルとその数の確認
display(data[data["title"].str.contains(r'[^\s\w]')]["title"].head())
display(data[data["title"].str.contains(r'[^\s\w]')]["title"].count().sum())
# ',! - [] などの記号の入ったアブストラクトとその数の確認
# fillna(False)を入れないとこのエラーが出る ValueError: Cannot mask with non-boolean array containing NA / NaN values
#https://stackoverflow.com/questions/68448583/valueerror-cannot-mask-with-non-boolean-array-containing-na-nan-values
display(data[data["abstract"].str.contains(r'[^\s\w]').fillna(False)]["abstract"].head())
display(data[data["abstract"].str.contains(r'[^\s\w]').fillna(False)]["abstract"].count().sum())
記号の削除および小文字に変換
import re
#x内の記号のある部分r'[^\w\s]'を'' に変換。つまり記号が削除される。
#タイトルの記号の削除および小文字に変換。新しいカラム'title_clean' に格納
data['title_clean'] = data["title"].apply(lambda x: re.sub(r'[^\w\s]','', x).lower().strip())
#アブストラクトの記号の削除および小文字に変換。新しいカラム'abstract_clean' に格納
#abstract データの一部がfloatsとみなされたのでstrを入れた。
data['abstract_clean'] = data["abstract"].apply(lambda x: re.sub(r'[^\w\s]','', str(x)).lower().strip())
display(data.head())

論文を4年ごとに分割
以降のLDAモデルを用いた分析で必要になります。
# 1964年以前の論文は1920年の論文一報だけだったので、この論文を省くことにしました。
data_a = data.query('year >= 1964 and year <= 1967')
data_b = data.query('year >= 1968 and year <= 1971')
data_c = data.query('year >= 1972 and year <= 1975')
data_d = data.query('year >= 1976 and year <= 1979')
data_e = data.query('year >= 1980 and year <= 1983')
data_f = data.query('year >= 1984 and year <= 1987')
data_g = data.query('year >= 1988 and year <= 1991')
data_h = data.query('year >= 1992 and year <= 1995')
data_i = data.query('year >= 1996 and year <= 1999')
data_j = data.query('year >= 2000 and year <= 2003')
data_k = data.query('year >= 2004 and year <= 2007')
data_l = data.query('year >= 2008 and year <= 2011')
data_m = data.query('year >= 2012 and year <= 2015')
data_n = data.query('year >= 2016 and year <= 2019')
data_o = data.query('year >= 2020 and year <= 2021')
#最初のグループを出力
print(data_a)
各年代のグループのリスト化
次のトークン化に必要になります。
# text_clean カラムの全データをリスト化
title_list = data["title_clean"].values.tolist()
# abstract_clean カラムの全データをリスト化
abstract_list = data["abstract_clean"].values.tolist()
#各年代のグループのリスト化。ここでは title_clean のデータを使用。
list_a = data_a["title_clean"].values.tolist()
list_b = data_b["title_clean"].values.tolist()
list_c = data_c["title_clean"].values.tolist()
list_d = data_d["title_clean"].values.tolist()
list_e = data_e["title_clean"].values.tolist()
list_f = data_f["title_clean"].values.tolist()
list_g = data_g["title_clean"].values.tolist()
list_h = data_h["title_clean"].values.tolist()
list_i = data_i["title_clean"].values.tolist()
list_j = data_j["title_clean"].values.tolist()
list_k = data_k["title_clean"].values.tolist()
list_l = data_l["title_clean"].values.tolist()
list_m = data_m["title_clean"].values.tolist()
list_n = data_n["title_clean"].values.tolist()
list_o = data_o["title_clean"].values.tolist()単語に分解してトークン化
# タイトルとアブストラクトのトークン化
title_list = [nltk.word_tokenize(x) for x in title_list]
abstract_list = [nltk.word_tokenize(x) for x in abstract_list]
# 各年代のリストのトークン化
list_a = [nltk.word_tokenize(x) for x in list_a]
list_b = [nltk.word_tokenize(x) for x in list_b]
list_c = [nltk.word_tokenize(x) for x in list_c]
list_d = [nltk.word_tokenize(x) for x in list_d]
list_e = [nltk.word_tokenize(x) for x in list_e]
list_f = [nltk.word_tokenize(x) for x in list_f]
list_g = [nltk.word_tokenize(x) for x in list_g]
list_h = [nltk.word_tokenize(x) for x in list_h]
list_i = [nltk.word_tokenize(x) for x in list_i]
list_j = [nltk.word_tokenize(x) for x in list_j]
list_k = [nltk.word_tokenize(x) for x in list_k]
list_l = [nltk.word_tokenize(x) for x in list_l]
list_m = [nltk.word_tokenize(x) for x in list_m]
list_n = [nltk.word_tokenize(x) for x in list_n]
list_o = [nltk.word_tokenize(x) for x in list_o]
#list_aの最初の3つのデータを出力
print(list_a[:3])
単語を名詞と形容詞のみに限定
後のLDAモデルを用いた分析で、単語を名詞と形容詞に絞った方が論文を複数のトピックに分類しやすくなることが分かりました。
#品詞の限定: 形容詞、名詞のみ残す。
#JJ Adjective 形容詞
#JJR Adjective, comparative 形容詞 (比較級)
#JJS Adjective, superlative 形容詞 (最上級)
#NN Noun, singular or mass 名詞
#NNS Noun, plural 名詞 (複数形)
#NNP Proper noun, singular 固有名詞
#NNPS Proper noun, plural 固有名詞 (複数形)
#参考 https://qiita.com/m__k/items/ffd3b7774f2fde1083fa
#名詞と形容詞のリスト
part_of_speech = ["JJ", "JJR", "JJS", "NN", "NNS", "NNP", "NNPS"]
# 名詞と形容詞を抽出
# pos_tag で('great', 'JJ'), ('person', 'NN') のように ('単語', '品詞') のリストが作成される。
# 単語の品詞 word[1] が part_of_speech に存在すれば、単語 word[0] をリストに格納させる。
# 全タイトルと全アブストラクトのリストから名詞と形容詞を抽出
for i in range(len(title_list)):
title_list[i] = nltk.pos_tag(title_list[i])
title_list[i] = [word[0] for word in title_list[i] if word[1] in part_of_speech]
abstract_list[i] = nltk.pos_tag(abstract_list[i])
abstract_list[i] = [word[0] for word in abstract_list[i] if word[1] in part_of_speech]
# 各年代のリストから名詞と形容詞を抽出
for i in range(len(list_a)):
list_a[i] = nltk.pos_tag(list_a[i])
list_a[i] = [word[0] for word in list_a[i] if word[1] in part_of_speech]
for i in range(len(list_b)):
list_b[i] = nltk.pos_tag(list_b[i])
list_b[i] = [word[0] for word in list_b[i] if word[1] in part_of_speech]
for i in range(len(list_c)):
list_c[i] = nltk.pos_tag(list_c[i])
list_c[i] = [word[0] for word in list_c[i] if word[1] in part_of_speech]
。
。
。
。
for i in range(len(list_n)):
list_n[i] = nltk.pos_tag(list_n[i])
list_n[i] = [word[0] for word in list_n[i] if word[1] in part_of_speech]
for i in range(len(list_o)):
list_o[i] = nltk.pos_tag(list_o[i])
list_o[i] = [word[0] for word in list_o[i] if word[1] in part_of_speech]
#list_a の最初の3行を表示
display(list_a[:3])
名詞と形容詞以外の単語がしっかり除かれています。
['the', 'influence', 'of', 'simulated', 'lowgravity', 'environments', 'on', 'growth', 'development', 'and', 'metabolism', 'of', 'plants']
⬇️ 名詞と形容詞を抽出
[['influence', 'simulated', 'lowgravity', 'environments', 'growth', 'development', 'metabolism', 'plants'],
ストップワードの削除
ストップワード(不要語)とは、「the」「a」「for」「you」「of」などの一般的な語のことであり、名詞、形容詞も含まれていることから、先ほど作成したリストから除外してみます。また同時に、どの論文にも含まれているはずの論文検索ワードも除くことにします。
# ストップワードリストのダウンロード 179単語
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words("english")
# 論文検索に使った2語も除く
word_to_remove = ["gravity", "development"]
# stopwords に word_to_remove も追加
stopwords = stopwords + word_to_remove
#ストップワードの削除
# 全タイトルと全アブストラクトのリストからストップワードを削除
for i in range(len(title_list)):
title_list[i] = [word for word in title_list[i] if word not in stopwords]
abstract_list[i] = [word for word in abstract_list[i] if word not in stopwords]
# 各年代のリストからストップワードを削除
for i in range(len(list_a)):
list_a[i] = [word for word in list_a[i] if word not in stopwords]
for i in range(len(list_b)):
list_b[i] = [word for word in list_b[i] if word not in stopwords]
for i in range(len(list_c)):
list_c[i] = [word for word in list_c[i] if word not in stopwords]
.
.
.
for i in range(len(list_n)):
list_n[i] = [word for word in list_n[i] if word not in stopwords]
for i in range(len(list_o)):
list_o[i] = [word for word in list_o[i] if word not in stopwords]見出し語化
見出し語化 (lemmatization)とは、辞書に載っている語形に従って変換することを言います。複数形も単数形に変換されます。
lem = nltk.stem.wordnet.WordNetLemmatizer()
nltk.download('wordnet')
#全タイトル、全アブストラクトリストの単語を見出し語化
for i in range(len(title_list)):
title_list[i] = [lem.lemmatize(word) for word in title_list[i]]
abstract_list[i] = [lem.lemmatize(word) for word in abstract_list[i]]
#各年代のリストの単語を見出し語化
for i in range(len(list_a)):
list_a[i] = [lem.lemmatize(word) for word in list_a[i]]
for i in range(len(list_b)):
list_b[i] = [lem.lemmatize(word) for word in list_b[i]]
for i in range(len(list_c)):
list_c[i] = [lem.lemmatize(word) for word in list_c[i]]
.
.
.
for i in range(len(list_n)):
list_n[i] = [lem.lemmatize(word) for word in list_n[i]]
for i in range(len(list_o)):
list_o[i] = [lem.lemmatize(word) for word in list_o[i]]
#list_a の最初の3つのリストを出力
display(list_a[:3])
複数形の "s" が除かれているのが分かります。
['influence', 'simulated', 'lowgravity', 'environments', 'growth', 'metabolism', 'plants']
⬇️ 見出し語化
['influence', 'simulated', 'lowgravity', 'environment', 'growth', 'metabolism',
'plant']
リストの一次元化
今まで作成した各リストは、二次元構造 [[a, b, c ], [d, e, f ], [ g, h],...] を取っているのですが、LDAモデルを使用するために一次元構造 [a, b, c, d, e, f, g, h, ...] に変換しました。
# タイトルとアブストラクトのリストを一次元構造にする
title_list_all = []
for i in range(len(title_list)):
title_list_all += title_list[i]
abstract_list_all = []
for i in range(len(abstract_list)):
abstract_list_all += abstract_list[i]
# 各年代のリストを一次元構造にする
list_a_all = []
for i in range(len(list_a)):
list_a_all += list_a[i]
list_b_all = []
for i in range(len(list_b)):
list_b_all += list_b[i]
list_c_all = []
for i in range(len(list_c)):
list_c_all += list_c[i]
.
.
.
list_n_all = []
for i in range(len(list_n)):
list_n_all += list_n[i]
list_o_all = []
for i in range(len(list_o)):
list_o_all += list_o[i]
# list_a_all を出力
print(list_a_all)
LDA モデルによるトピック分析
LDA (Latent Dirichlet Allocation) 、潜在的ディリクレ配分法とも呼ばれる言語モデルで、文書からLDAモデルの推測、およびトピックの分布の推定ができます。このモデルを用いて各年代の論文をトピックで分けられるか、各年代でその分類に変化がみられるかを調べることにしました。
単語の出現回数のカウント
まず、gensimというテキスト解析用のライブラリを用いて各単語の出現回数をカウントします。
from gensim import corpora
from gensim.models import ldamodel
# 一元化した全タイトルのリストの単語を2単語つづ繋げて、新しいリストtitle_gram_lsに格納。
## アブストラクトも同様のリストを作成(ここでは省略)。
title_gram_ls = []
title_grams = [" ".join(title_list_all[i:i + 2]) for i in range(0, len(title_list_all), 2)]
title_gram_ls.append(title_grams)
# 単語のリストから辞書を作成します。
title_id2word = corpora.Dictionary(title_gram_ls)
print(id2word)
# 各年代のリストにも同様に2単語のリストを作成し、辞書の形式にします。
gram_a_ls = []
grams_a = [" ".join(list_a_all[i:i + 2]) for i in range(0, len(list_a_all), 2)]
gram_a_ls.append(grams_a)
id2word_a = corpora.Dictionary(gram_a_ls)
gram_b_ls = []
grams_b = [" ".join(list_b_all[i:i + 2]) for i in range(0, len(list_b_all), 2)]
gram_b_ls.append(grams_b)
id2word_b = corpora.Dictionary(gram_b_ls)
.
.
.
gram_o_ls = []
grams_o = [" ".join(list_o_all[i:i + 2]) for i in range(0, len(list_o_all), 2)]
gram_o_ls.append(grams_o)
id2word_o = corpora.Dictionary(gram_o_ls)
# 各単語の出現回数をカウント (ID, 出現回数) bag-of-words
# 全タイトルの単語の出現回数
title_dic = [title_id2word.doc2bow(word) for word in title_gram_ls]
# 各年代のタイトルの単語の出現回数
dic_a = [id2word_a.doc2bow(word) for word in gram_a_ls]
dic_b = [id2word_b.doc2bow(word) for word in gram_b_ls]
dic_c = [id2word_c.doc2bow(word) for word in gram_c_ls]
.
.
.
dic_n = [id2word_n.doc2bow(word) for word in gram_n_ls]
dic_o = [id2word_o.doc2bow(word) for word in gram_o_ls]
# list_a_all から作成した各リストの出力
print(gram_a_ls)
print(id2word_a)
print(dic_a)gram_a_ls (2語のリスト)
![]()
id2word_a (辞書)
![]()
[["pen", "pineapple"], ["apple", "pen"]] を辞書にすると以下のように語の重複が無くなります。また出力には出てきませんが、IDも付けられているようです。 Dictionary(3 unique tokens: ['pen', 'pineapple', 'apple'])
dic_a(ID, 出現回数)
![]()
LDA モデル
論文の各年代のトピック分析を行います。トピック数を3に設定しました。
# トピック数の設定
num_topics = 3
# 全タイトル、全アブストラクトの単語をトピックに分類 (ここでは全タイトルの場合のみ示す)
title_lda_model = ldamodel.LdaModel(corpus=title_dic, id2word=title_id2word, num_topics=num_topics,
random_state=42, update_every=1, chunksize=100,
passes=10, alpha='auto', per_word_topics=True)
# 各年代の論文の単語をトピックに分類
lda_model_a = ldamodel.LdaModel(corpus=dic_a, id2word=id2word_a, num_topics=num_topics,
random_state=42, update_every=1, chunksize=100,
passes=10, alpha='auto', per_word_topics=True)
lda_model_b = ldamodel.LdaModel(corpus=dic_b, id2word=id2word_b, num_topics=num_topics,
random_state=42, update_every=1, chunksize=100,
passes=10, alpha='auto', per_word_topics=True)
.
.
.
lda_model_n = ldamodel.LdaModel(corpus=dic_n, id2word=id2word_n, num_topics=num_topics,
random_state=42, update_every=1, chunksize=100,
passes=10, alpha='auto', per_word_topics=True)
lda_model_o = ldamodel.LdaModel(corpus=dic_o, id2word=id2word_o, num_topics=num_topics,
random_state=42, update_every=1, chunksize=100,
passes=10, alpha='auto', per_word_topics=True)トピック分布のグラフ化
#トピック番号、ID、語、weight(重み)の辞書を作成し、グラフ化
import matplotlib.pyplot as plt
import seaborn as sns
# 全タイトル、全アブストラクトで {トピック番号, ID, 語, weight} の辞書を作成。(ここでは全タイトルの場合のみ示す)
title_dics = []
for i in range(0,num_topics):
lst_tuples = title_lda_model.get_topic_terms(i) #[(トピック番号, weight), (トピック番号, weight), ・・・]
for tupla in lst_tuples:
title_dics.append({"topic":i, "id":tupla[0], "word":title_id2word[tupla[0]], "weight":tupla[1]})
# 各年代ごとに {トピック番号, ID, 語, weight} の辞書を作成
dics_a = []
for i in range(0,num_topics):
tuples_a = lda_model_a.get_topic_terms(i)
for tupla in tuples_a:
dics_a.append({"topic":i, "id":tupla[0], "word":id2word_a[tupla[0]], "weight":tupla[1]})
dics_b = []
for i in range(0,num_topics):
tuples_b = lda_model_b.get_topic_terms(i)
for tupla in tuples_b:
dics_b.append({"topic":i, "id":tupla[0], "word":id2word_b[tupla[0]], "weight":tupla[1]})
.
.
.
dics_n = []
for i in range(0,num_topics):
tuples_n = lda_model_n.get_topic_terms(i)
for tupla in tuples_n:
dics_n.append({"topic":i, "id":tupla[0], "word":id2word_n[tupla[0]], "weight":tupla[1]})
dics_o = []
for i in range(0,num_topics):
tuples_o = lda_model_o.get_topic_terms(i)
for tupla in tuples_o:
dics_o.append({"topic":i, "id":tupla[0], "word":id2word_o[tupla[0]], "weight":tupla[1]})
# 作成した辞書をデータフレーム型に変換
## 全タイトル
df_title_topics = pd.DataFrame(title_dics, columns=['topic','id','word','weight'])
## 各年代のタイトル
df_a_topics = pd.DataFrame(dics_a, columns=['topic','id','word','weight'])
df_b_topics = pd.DataFrame(dics_b, columns=['topic','id','word','weight'])
df_c_topics = pd.DataFrame(dics_c, columns=['topic','id','word','weight'])
df_d_topics = pd.DataFrame(dics_d, columns=['topic','id','word','weight'])
df_e_topics = pd.DataFrame(dics_e, columns=['topic','id','word','weight'])
df_f_topics = pd.DataFrame(dics_f, columns=['topic','id','word','weight'])
df_g_topics = pd.DataFrame(dics_g, columns=['topic','id','word','weight'])
df_h_topics = pd.DataFrame(dics_h, columns=['topic','id','word','weight'])
df_i_topics = pd.DataFrame(dics_i, columns=['topic','id','word','weight'])
df_j_topics = pd.DataFrame(dics_j, columns=['topic','id','word','weight'])
df_k_topics = pd.DataFrame(dics_k, columns=['topic','id','word','weight'])
df_l_topics = pd.DataFrame(dics_l, columns=['topic','id','word','weight'])
df_m_topics = pd.DataFrame(dics_m, columns=['topic','id','word','weight'])
df_n_topics = pd.DataFrame(dics_n, columns=['topic','id','word','weight'])
df_o_topics = pd.DataFrame(dics_o, columns=['topic','id','word','weight'])
## df_a_topics のデータフレームを出力
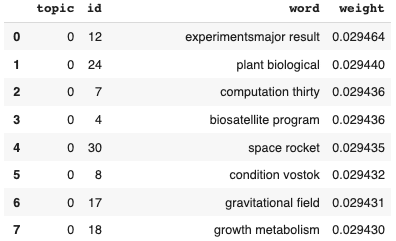
display(df_a_topics)
# グラフの作成
fig, ax = plt.subplots(figsize=(5, 10))
sns.barplot(y="word", x="weight", hue="topic", data=df_title_topics, dodge=False, ax=ax).set_title('Main Topics')
ax.set(ylabel="", xlabel="Word Importance")
plt.show()
fig, ax = plt.subplots(figsize=(5, 10))
sns.barplot(y="word", x="weight", hue="topic", data=df_a_topics, dodge=False, ax=ax).set_title('Main Topics')
ax.set(ylabel="", xlabel="Word Importance")
plt.show()
fig, ax = plt.subplots(figsize=(5, 10))
sns.barplot(y="word", x="weight", hue="topic", data=df_b_topics, dodge=False, ax=ax).set_title('Main Topics')
ax.set(ylabel="", xlabel="Word Importance")
plt.show()
.
.
.
fig, ax = plt.subplots(figsize=(5, 10))
sns.barplot(y="word", x="weight", hue="topic", data=df_n_topics, dodge=False, ax=ax).set_title('Main Topics')
ax.set(ylabel="", xlabel="Word Importance")
plt.show()
fig, ax = plt.subplots(figsize=(5, 10))
sns.barplot(y="word", x="weight", hue="topic", data=df_o_topics, dodge=False, ax=ax).set_title('Main Topics')
ax.set(ylabel="", xlabel="Word Importance")
plt.show()df_a_topics のデータフレーム(テーマ1 1964-67年のタイトル)
トピックの分布(テーマ1)
全タイトル 全アブストラクト

各年代のタイトル







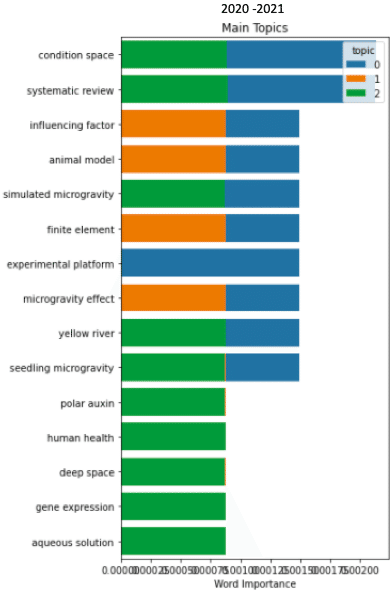
上のテーマ1の結果を見ると、タイトル及びアブストラクト全体で(特にアブストラクトで)トピックが一様に見えます。
4年ごとに区切ると2、3のトピックに分類できているのが分かります。ここではタイトルのデータのみを示しましたが、アブストラクトでも同様の結果になりました。ただタイトルの方がトピックに多様性がありました。
また年代を遡るほど、より多くのトピックによって綺麗に分類されている傾向が見えました。
タイトル(テーマ2)

テーマ2の iPS 細胞の方はデータの同質ぶりがより顕著でした。タイトルを各年ごとにみてやっとトピックの分類がはっきり見えてきたくらいです。(上の図は2016年と2021年のデータ)。
このことから、iPS 細胞を用いた再生医療の論文および研究内容が如何に互いに似通っているかが分かります。熾烈な競争が繰り広げられているのでしょう。
ただテーマ1と同様、年代を遡るほどトピックの分類がはっきり見える傾向がありました。どの分野でも時代を経るごとに研究内容が特定の領域に集中していくのかもしれません。
fastText のtrain_unsupervisedメソッドを用いた教師なし学習
次は、いよいよ教師なし学習でテーマ1のタイトルデータがクラスタリングされるか見ていくことにします!
fastTextとは、Facebookが開発した単語表現の学習と文章の分類を効果的に行うライブラリで、その名前の通り処理が高速で精度も高いようです。
この分析は以下のリンクを参考にしました。
fastTextがすごい!「Yahoo!ニュース」をクラスタリング
fastTextがかなりすごい!「Yahoo!ニュース」クラスタリング 〜教師なし学習編〜
fastText のインストール
#fasttest のインストール
# https://stackoverflow.com/questions/58186800/modulenotfounderror-no-module-named-fasttext
!git clone https://github.com/facebookresearch/fastText.git
!cd fastText
!pip install fastText教師なし学習
タイトルのデータを使って教師なし学習 train_unsupervisedを行います。モデル構築用のトレーニングデータ(train)とモデル検証用のテストデータ(valid)に 8:2 の割合で分割します。
#教師なし学習
import fasttext
from sklearn.model_selection import train_test_split
# 発行年とタイトルのリストを作成
year_list = data["year"] #しかしlistにすると上手くいかない。。
ttl_list = data["title_clean"].values.tolist()
#trainデータとvalidデータに分割
title_train, title_valid, year_train, year_valid = train_test_split(
ttl_list, year_list, test_size=0.2, random_state=0
)
#文章をファイルに保存
with open('./un_train', mode='w') as f:
for i in range(len(title_train)):
f.write(title_train[i]+'\n')
with open('./un_valid', mode='w') as f:
for i in range(len(title_valid)):
f.write(title_valid[i]+'\n')
#教師なし学習
model = fasttext.train_unsupervised('./un_train', epoch=200, lr=0.0125, minn=3, maxn=5, dim=100)学習済みのベクトルの次元削減
from sklearn import preprocessing
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 学習済モデルから文章ベクトルを生成
vectors = []
for t in title_train:
vectors.append(model.get_sentence_vector(t)
# ベクトルとラベルをそれぞれnumpy配列に変換
vectors = np.array(vectors)
labels = np.array(year_train.astype(str)) #astype(str)を追加しないとエラー出る。数字データと文字データが混じっていたかも。
# ベクトルの標準化
ss = preprocessing.StandardScaler()
vectors_std = ss.fit_transform(vectors)
# PCAを用いてベクトルを2次元に削減
pca = PCA(n_components=2)
pca.fit(vectors_std)
feature = pca.transform(vectors_std)
# 次元の確認
print(feature.shape)
# ベクトルの出力
print(feature)次元削減後のベクトル

二次元プロット
ベクトルのプロット結果をベクトルと発行年でプロットします。
x0, y0 = feature[labels=='1964', 0], feature[labels=='1964', 1]
x1, y1 = feature[labels=='1965', 0], feature[labels=='1965', 1]
x2, y2 = feature[labels=='1966', 0], feature[labels=='1966', 1]
.
.
.
x56, y56 = feature[labels=='2020', 0], feature[labels=='2020', 1]
x57, y57 = feature[labels=='2021', 0], feature[labels=='2021', 1]
plt.figure(figsize=(14, 10))
# 四年ごとに異なる色を設定
plt.scatter(x0, y0, label="1964", s=20, c="indigo")
plt.scatter(x1, y1, label="1965", s=20, c="indigo")
plt.scatter(x2, y2, label="1966", s=20, c="indigo")
plt.scatter(x3, y3, label="1967", s=20, c="indigo")
plt.scatter(x4, y4, label="1968", s=20, c="purple")
plt.scatter(x5, y5, label="1969", s=20, c="purple")
plt.scatter(x6, y6, label="1970", s=20, c="purple")
plt.scatter(x7, y7, label="1971", s=20, c="purple")
plt.scatter(x8, y8, label="1972", s=20, c="blueviolet")
plt.scatter(x9, y9, label="1973", s=20, c="blueviolet")
plt.scatter(x10, y10, label="1974", s=20, c="blueviolet")
plt.scatter(x11, y11, label="1975", s=20, c="blueviolet")
plt.scatter(x12, y12, label="1976", s=20, c="blue")
plt.scatter(x13, y13, label="1977", s=20, c="blue")
plt.scatter(x14, y14, label="1978", s=20, c="blue")
plt.scatter(x15, y15, label="1979", s=20, c="blue")
plt.scatter(x16, y16, label="1980", s=20, c="darkcyan")
plt.scatter(x17, y17, label="1981", s=20, c="darkcyan")
plt.scatter(x18, y18, label="1982", s=20, c="darkcyan")
plt.scatter(x19, y19, label="1983", s=20, c="darkcyan")
plt.scatter(x20, y20, label="1984", s=20, c="green")
plt.scatter(x21, y21, label="1985", s=20, c="green")
plt.scatter(x22, y22, label="1986", s=20, c="green")
plt.scatter(x23, y23, label="1987", s=20, c="green")
plt.scatter(x24, y24, label="1988", s=20, c="limegreen")
plt.scatter(x25, y25, label="1989", s=20, c="limegreen")
plt.scatter(x26, y26, label="1990", s=20, c="limegreen")
plt.scatter(x27, y27, label="1991", s=20, c="limegreen")
plt.scatter(x28, y28, label="1992", s=20, c="lime")
plt.scatter(x29, y29, label="1993", s=20, c="lime")
plt.scatter(x30, y30, label="1994", s=20, c="lime")
plt.scatter(x31, y31, label="1995", s=20, c="lime")
plt.scatter(x32, y32, label="1996", s=20, c="yellowgreen")
plt.scatter(x33, y33, label="1997", s=20, c="yellowgreen")
plt.scatter(x34, y34, label="1998", s=20, c="yellowgreen")
plt.scatter(x35, y35, label="1999", s=20, c="yellowgreen")
plt.scatter(x36, y36, label="2000", s=20, c="gold")
plt.scatter(x37, y37, label="2001", s=20, c="gold")
plt.scatter(x38, y38, label="2002", s=20, c="gold")
plt.scatter(x39, y39, label="2003", s=20, c="gold")
plt.scatter(x40, y40, label="2004", s=20, c="orange")
plt.scatter(x41, y41, label="2005", s=20, c="orange")
plt.scatter(x42, y42, label="2006", s=20, c="orange")
plt.scatter(x43, y43, label="2007", s=20, c="orange")
plt.scatter(x44, y44, label="2008", s=20, c="orangered")
plt.scatter(x45, y45, label="2009", s=20, c="orangered")
plt.scatter(x46, y46, label="2010", s=20, c="orangered")
plt.scatter(x47, y47, label="2011", s=20, c="orangered")
plt.scatter(x48, y48, label="2012", s=20, c="red")
plt.scatter(x49, y49, label="2013", s=20, c="red")
plt.scatter(x50, y50, label="2014", s=20, c="red")
plt.scatter(x51, y51, label="2015", s=20, c="red")
plt.scatter(x52, y52, label="2016", s=20, c="deeppink")
plt.scatter(x53, y53, label="2017", s=20, c="deeppink")
plt.scatter(x54, y54, label="2018", s=20, c="deeppink")
plt.scatter(x55, y55, label="2019", s=20, c="deeppink")
plt.scatter(x56, y56, label="2020", s=20, c="violet")
plt.scatter(x57, y57, label="2021", s=20, c="violet")
plt.title("Vectorized paper titles", fontsize=20)
plt.xlabel('1st dimension', fontsize=20)
plt.ylabel('2nd dimension', fontsize=20)
plt.legend(title="year", fontsize=6)
plt.show()Train data

はっきりとしたクラスターとまでは言えませんが、最近の論文(赤系色)が右側に集中しているのが分かります。時代を経るごとにタイトルの内容が特定の領域に集中していっているように見えます。LDAのデータと矛盾しませんね。
次は、テストデータを使って学習済みモデルを検証してみます。コードは上述の「学習済みのベクトルの次元削減」の title_train の部分を title_valid に、year_train の部分を year_valid に置き換えるだけで済み、また「二次元プロット」の部分はそのまま変更なしで使用できるので(以下の図ではプロットのサイズをs=50に設定)省略させていただきました。
Valid data

トレーニングデータと同様、テストデータ(valid)のベクトルでも最近の論文が特定の箇所に集まっている傾向が見れました。学習済モデルとしてはなかなかの出来ですね!
文章同士の類似度の比較
上の「学習済みのベクトルの次元削減」で算出したベクトル値(vectors)を用いて、論文のタイトル同士のコサイン類似度を求めてみます。コサイン類似度とは、二次元のベクトルが向いている方向がどのくらい近いかを示す値で、値が1に近づくほど類似度が高くなります。
トレーニングデータ、テストデータの各グループにおいて古い年代、及び最近の論文タイトルのベクトルをランダムに2つずつ選択し、1)古い論文 vs 最近の論文、2)古い論文同士、3)新しい論文同士のコサイン類似度を算出します。
#コサイン類似度の関数
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
# トレインデータの year の情報をファイルに保存
year_train.to_csv("./yr_train.csv")
# yearとtitleを表示
print("<{}年の論文>".format(year_train[233]))
print(title_train[233], end="\n\n")
print("<{}年の論文>".format(year_train[319]))
print(title_train[319], end="\n\n")
print("<{}年の論文>".format(year_train[42]))
print(title_train[42], end="\n\n")
print("<{}年の論文>".format(year_train[2]))
print(title_train[2], end="\n\n")
# cos_sim関数を用いてコサイン類似度を算出
print("{}年と{}年のコサイン類似度:".format(year_train[233], year_train[42]), cos_sim(vectors[233], vectors[42]))
print("{}年と{}年のコサイン類似度:".format(year_train[233], year_train[2]), cos_sim(vectors[233], vectors[2]))
print("{}年と{}年のコサイン類似度:".format(year_train[319], year_train[42]), cos_sim(vectors[319], vectors[42]))
print("{}年と{}年のコサイン類似度:".format(year_train[319], year_train[2]), cos_sim(vectors[319], vectors[2]))
print("{}年と{}年のコサイン類似度:".format(year_train[233], year_train[319]), cos_sim(vectors[233], vectors[319]))
print("{}年と{}年のコサイン類似度:".format(year_train[42], year_train[2]), cos_sim(vectors[42], vectors[2]))
###以下の処理は「学習済みのベクトルの次元削減」のコードをtrain_valid と year_valid を用いて実行した後に行います。###
# テストデータの year の情報をファイルに保存
year_valid.to_csv("./yr_valid.csv")
# yearとtitleを表示
print("<{}年の論文>".format(year_valid[306]))
print(title_valid[306], end="\n\n")
print("<{}年の論文>".format(year_valid[117]))
print(title_valid[117], end="\n\n")
print("<{}年の論文>".format(year_valid[1]))
print(title_valid[1], end="\n\n")
print("<{}年の論文>".format(year_valid[14]))
print(title_valid[14], end="\n\n")
# cos_sim関数を用いてコサイン類似度を算出
print("{}年と{}年のコサイン類似度:".format(year_valid[117], year_valid[1]), cos_sim(vectors[117], vectors[1]))
print("{}年と{}年のコサイン類似度:".format(year_valid[306], year_valid[1]), cos_sim(vectors[306], vectors[1]))
print("{}年と{}年のコサイン類似度:".format(year_valid[117], year_valid[14]), cos_sim(vectors[117], vectors[14]))
print("{}年と{}年のコサイン類似度:".format(year_valid[306], year_valid[14]), cos_sim(vectors[306], vectors[14]))
print("{}年と{}年のコサイン類似度:".format(year_valid[117], year_valid[306]), cos_sim(vectors[117], vectors[306]))
print("{}年と{}年のコサイン類似度:".format(year_valid[1], year_valid[14]), cos_sim(vectors[1], vectors[14]))トレーニングデータ

テストデータ

トレインデータ、テストデータの何れにおいても、期待通り同時代間の論文でコサイン類似度が高く、異なる時代間では低い結果もあれば、そうでない結果もありました。論文数報を見ただけなので、全体の傾向を見るには論文の全ての組み合わせを試して統計を取る必要がありそうです。
教師あり学習 (おまけ)
無理ゲーとは思いながらも、試しに発行年 year をラベルとして各論文のタイトルを発行年で分類できるかを教師あり学習で見てみました。
詳細は省略しますが、トレーニングデータのテストデータの精度/再現率はほぼ1ととても高い値でしたが、テストデータ(valid)は予想通りの低い値 0.06 でした。
(データ数, 精度, 再現率)
TrainData: (2989, 0.9986617597858816, 0.9986617597858816)
Valid (746, 0.06032171581769437, 0.06032171581769437)
全58年分から成るデータを年で分類となると当たる確率が1/58 ≒ 0.017ととても低く、ほとんどの論文が外れということになり偏りが非常に大きくなるので当然の結果といえますね。時代ごとにせめて2、3グループ程度に分類して予測してみるともっと高い値が得られそうです。
まとめと考察
LDAの結果について
テーマ1、2共に古い年代ほどトピックがより多様である傾向があったので、時を経るにつれ研究内容が特定の領域に絞られてきているといえる。
アブストラクトとタイトルでは、タイトルを用いた方がより多くのトピックに分かれる傾向がある。タイトルの方が論文内容のエッセンスをより端的に表していて、アブストラクト特有の言い回しや余計な説明などが無いからだろう。
教師なし学習の結果について
トレインデータとテストデータの結果が類似していたので、学習済モデルをうまく構築できたといえる。
クラスターと言えるほどではないが、古い時代の論文と最近の論文とでベクトルの分布に差がみられたので、時代によって研究内容が変化してきていると言える。➡️ LDAの結果と矛盾しない。
今回は結果を二次元で見てみたが、t-SNEなどを使って三次元で見ると新たな発見があるかもしれない。
データに科学論文を使用したことについて
他の新聞記事などのテキストを用いた場合と比較すると、はっきりとは分類されていなかった。その理由として以下のことが考えられる。
1)そもそも科学論文というものは、特有の表現方法、共通の専門用語を使って書かれている。
2)データをスクレイピングで抽出する前に、検索ワードを用いて論文を絞ったことでさらに同質化した。
初めての試みでしたが、大変ながらもやりがいがあり楽しめました。
至らぬ所が多々ありそうですが、目を通していただきありがとうございました🙇♀️!
謝辞
この分析は、アイデミーのデータ分析講座の成果物作成で行いました。スタッフの皆様のサポートを心より御礼申し上げます。