
Power BIでウェブスクレイピング!サイトから欲しいデータをゲットする!

概要(目的・背景)
データ分析の重要性が増す中、ウェブ上の情報を効率的に収集・活用するニーズが高まっています。特に、最新の市場動向や競合情報など、ウェブ上で公開されているデータをタイムリーに取得することは、ビジネスの意思決定において大きな価値を持ちます。しかし、手動でのデータ収集は時間と労力がかかり、更新のたびに同じ作業を繰り返すのは非効率です。
そこで、Power BIを活用してウェブスクレイピングを行い、必要なデータを自動的に取得・更新する方法をくわしく説明します。これにより、データ収集の効率化と分析の精度向上を目指します。
読み手(誰に向けた記事か?)
この記事は、下記のような読者を想定しています。
・Power BIを日常的に使用している担当者
(データ分析に興味を持つ中級者以上のユーザー)
Power BIの機能をさらに深く理解し、業務の効率化を図りたいと考えている方にも適しています。
ブログの目標設定(具体的な目標)
前回の記事で触れなかったPower Queryエディターのコードについて解説します。本記事を通してPower BIのPower Queryを活用し、特定のウェブサイトから必要な情報を効率的に取得する方法を学ぶことを目指します。
前回の記事はこちら。
方法(アプローチ・使用技術)
前回の記事では、WebサイトのURLを入力した後、自動でデータ取得、テーブル作成まで行われていました。赤枠(下図)が自動生成されましたので、まずは、どのような処理が行われているのか、解説します。

適用したステップにおいて、「ソース」、「HTMLから抽出されたテーブル」、「変換された型」の3つを詳細なソースコードとして確認するには、以下の手順を実行してください。
・「表示」タブを選択して、「詳細エディター」ボタンを押下する。
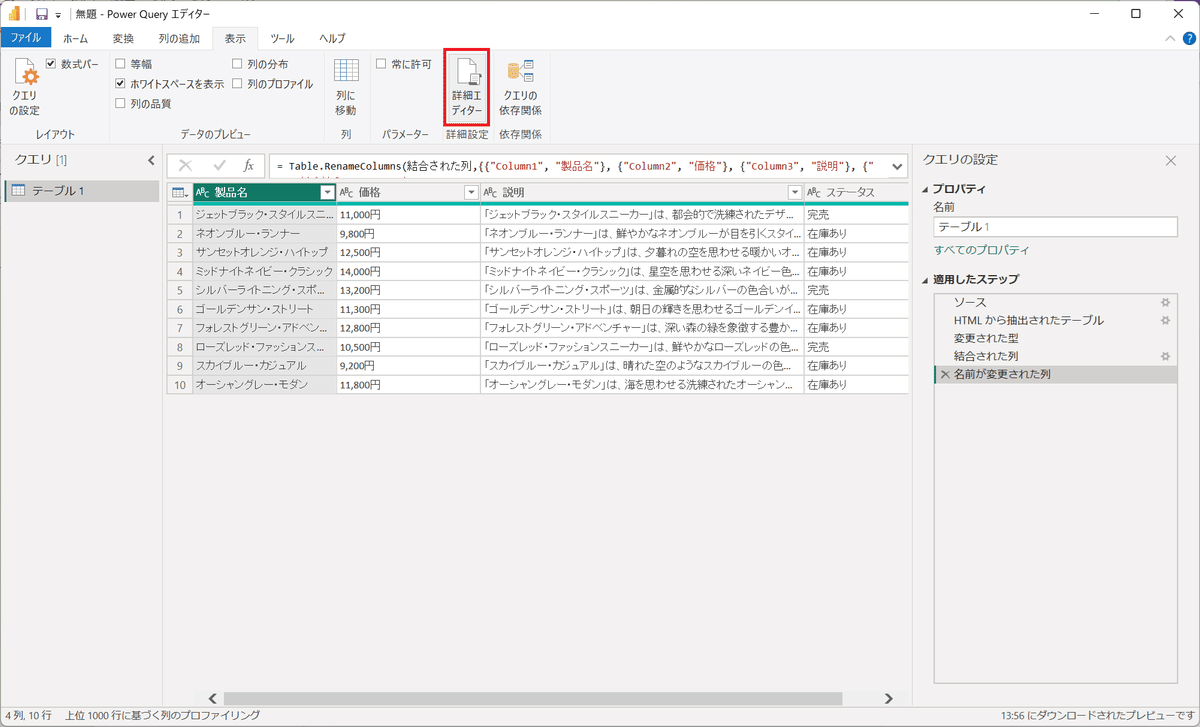

ソースコードの解説
各行について解説します。
1行目のコード
ソース = Web.BrowserContents("https://scraping.okinan.com/practice4?page=1"),Web.BrowserContents(…)関数
指定されたウェブページ(https://scraping.okinan.com/practice4?page=1)の内容を取得しています。これは、ウェブサイトのHTML(ページの裏側にある構造データ)を取得する作業です。
赤枠箇所が取得した結果のHTMLです。

2行目のコード
#"HTML から抽出されたテーブル" = Html.Table(
ソース,
{
{"Column1", ".css-uv97n3"},
{"Column2", ".css-1rzdeci"},
{"Column3", ".css-1hqkbmw"},
{"Column4", ".css-22e9hv"},
{"Column5", ".css-5r3d7o"}
},
[RowSelector=".MuiPaper-rounded"]
),Html.Table(…)関数
ウェブページのHTMLから、指定された情報を取り出してテーブル(表)にしています。
{"Column1", ".css-uv97n3"} ※一部抜粋
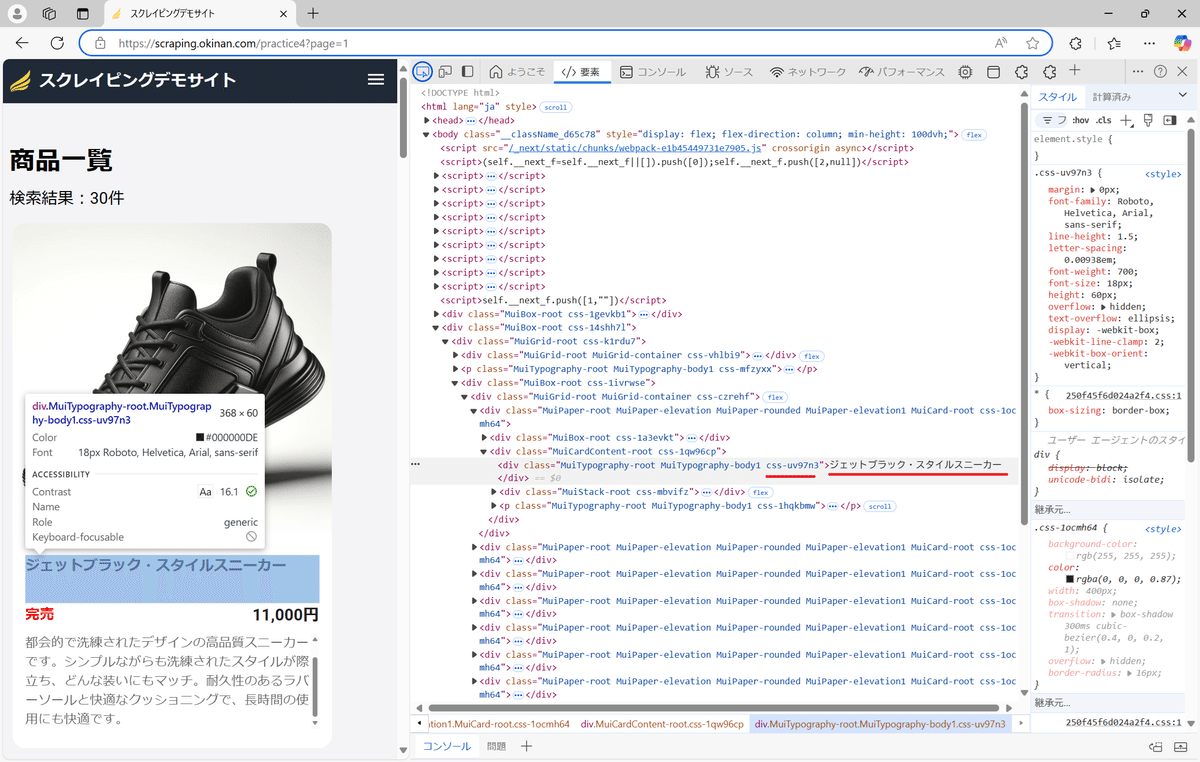
ウェブページ内で .css-uv97n3 という特定の部分(HTML要素)を探し、そのデータを Column1 という列に入れます。
下図のように、css-uv97n3の値である、「ジェットブラック・スタイルスニーカー」を取得しています。
他の列も同様に設定されています。
[RowSelector=".MuiPaper-rounded"]
HTML の中で、.MuiPaper-rounded という要素を含む部分を「行」として扱います。※下図の赤枠の単位で行を構成することを指します。

➊.詳細説明(css-uv97n3とは何か?)
ブラウザの開発者ツール(F12キー)を押下して、対象のCSSセレクターを確認します。「MuiTypography-root MuiTypography-body1 css-uv97n3」から情報を抽出していることがわかります。

➋.詳細説明(.css-uv97n3の先頭のドットは何か?)
右クリックして「コピー」>「selectorをコピー」を選択する。
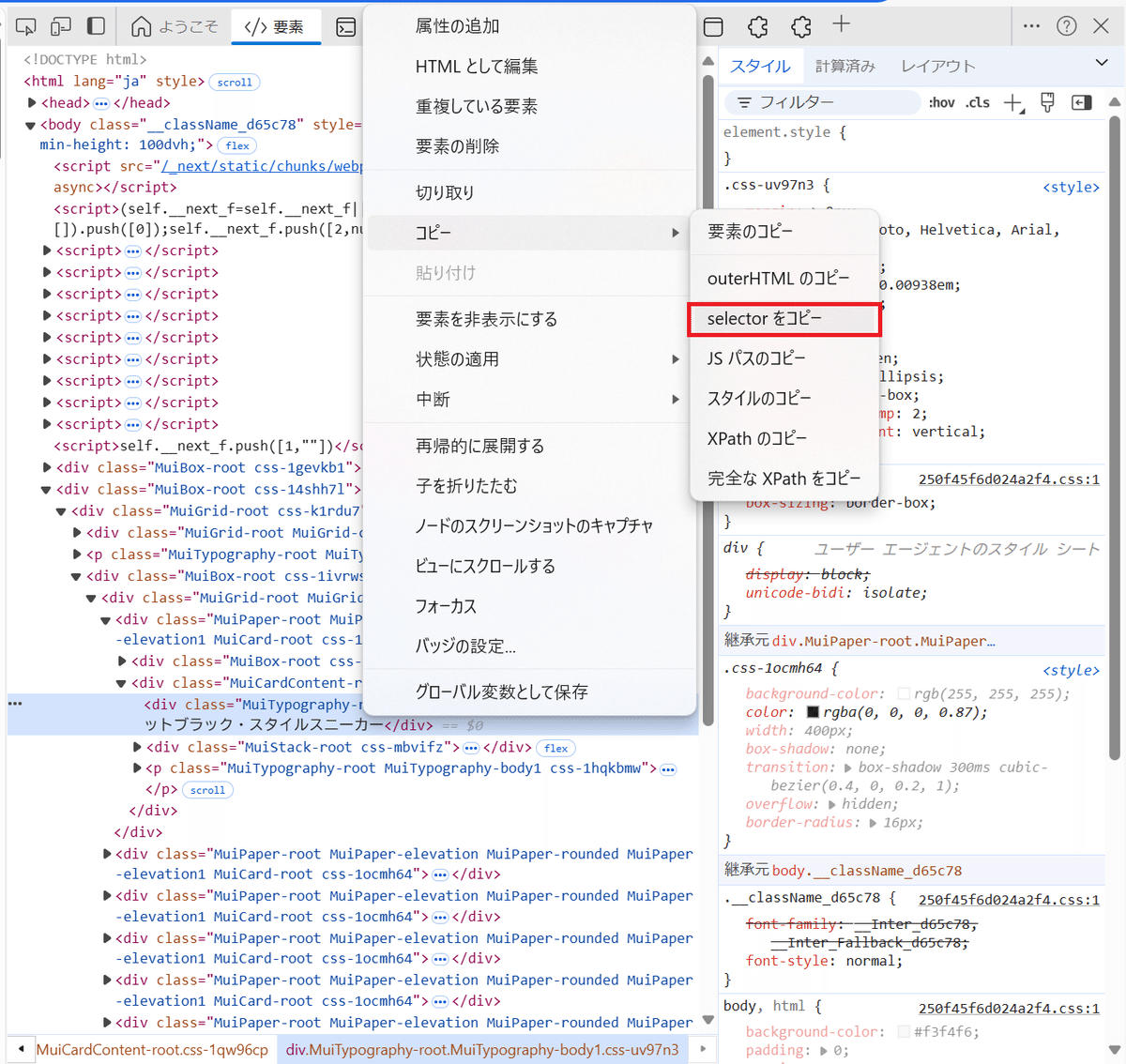
#コピー結果
body > div.MuiBox-root.css-14shh7l > div > div.MuiBox-root.css-1ivrwse > div > div:nth-child(1) > div.MuiCardContent-root.css-1qw96cp > div.MuiTypography-root.MuiTypography-body1.css-uv97n3コピーした結果より、上位からどこに適用するのかを表しています。PowerQueryは、「div.MuiTypography-root.MuiTypography-body1.css-uv97n3」末尾の「css-uv97n3」(クラス名)を指定しています。
「.(ドット)」は、「クラス名」を指定するためのプレフィックス(先頭記号)です。
※外観だけ理解していただければOKです。
3行目のコード
変更された型 = Table.TransformColumnTypes(
#"HTML から抽出されたテーブル",
{
{"Column1", type text},
{"Column2", type text},
{"Column3", type text},
{"Column4", type text},
{"Column5", type text}
}
),作成したテーブルの各列の「データ型」を設定しています。例えば、文字列として扱いたいデータには「type text」を指定します。データ型を指定することで、後で分析や計算を行うときにミスが起きにくくなります。
応用問題
商品画像のパス(URL)を取得したい場合どのようにコードを記述するか?
※下図の「/images/sampleData/sample1.png」

考え方
「商品画像のパス(URL)を取得したい。」をプログラミングの言葉で置き換えると、「imgタグの src 属性(画像のパス)を取得したい」となります。
これまでとは異なり、imgタグのsrc属性に情報が格納されているので、「imgタグのscr属性から情報を取り出す」という作りこみが必要です。
➊.取得方法(コード)
{"ImageSrc", "img[src]", each [Attributes][src]}
➋.解説
コードを1つ1つ解説していきます。
"ImageSrc"・・・ Html.Table関数で設定するテーブルの列名です。
"img[src]"・・・imgタグで src 属性が設定されている部分を対象にします。つまり、src 属性を持つすべてのimgタグを対象にします。
"each [Attributes][src]"・・・Html.Table 関数では、選択したタグの属性を Attributes というフィールドに格納します。この部分で、src 属性を取り出すことができます。また、each [Attributes][src] の意味は、「Attributes フィールドから src 属性を取り出して、その値を返す」という意味になります。
➌.補足
サイトの作り次第では、Attributes フィールドから 複数のsrc属性が検出されることがあります。その場合、処理がエラーになるため、複数eachを設定して、Text.Combine()関数で結合する必要があります。
実際に前回作成したPower BIのファイルに商品画像のURLを取得するソースコードを追加します。
1.テーブル1より、「クエリの編集」を選択する。

2.「表示」タブから、「詳細エディター」ボタンを押下する。
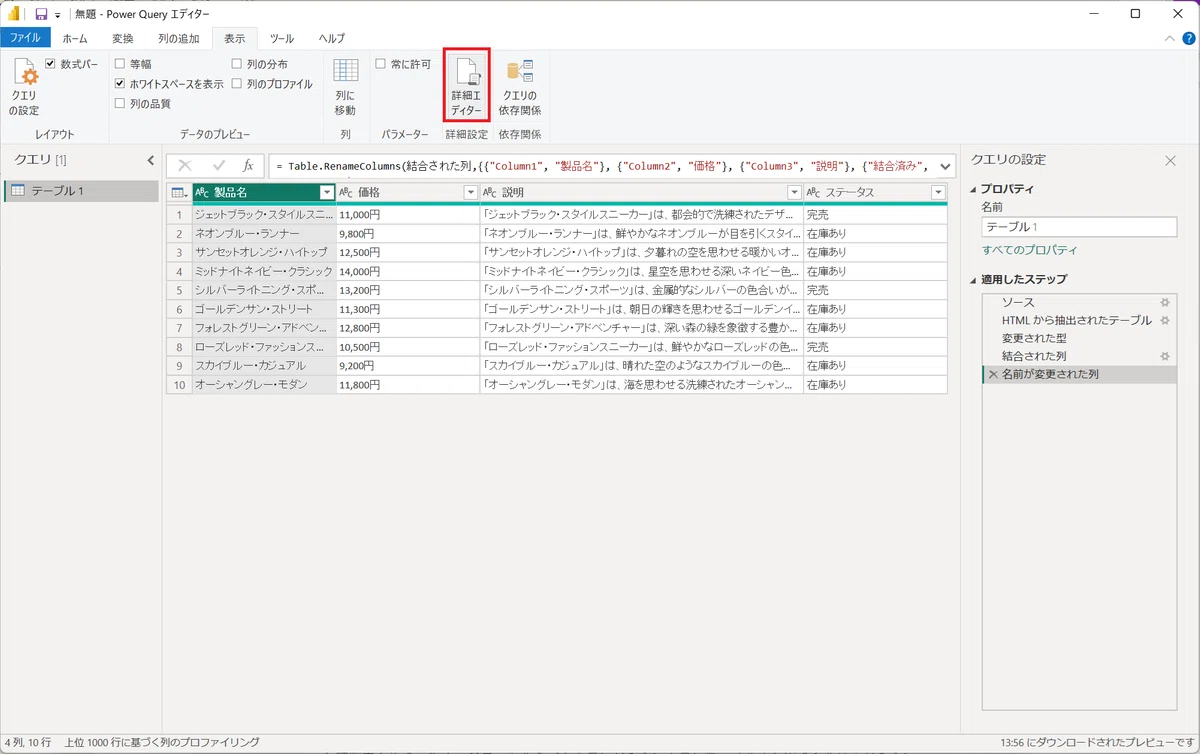
3.詳細エディターに画像URLを取り出すソースコードをコピーする。(以下のコードをすべてコピーしてください)
let
// Web ページの HTML ソースを取得
ソース = Web.BrowserContents("https://scraping.okinan.com/practice4?page=1"),
// 必要なデータをテーブルとして抽出
#"HTML から抽出されたテーブル" = Html.Table(
ソース,
{
{"Column1", ".css-uv97n3"},
{"Column2", ".css-1rzdeci"},
{"Column3", ".css-1hqkbmw"},
{"Column4", ".css-22e9hv"},
{"Column5", ".css-5r3d7o"},
// img タグの src 属性を取得
{"ImageSrc", "img[src]", each [Attributes][src]}
},
[RowSelector=".MuiPaper-rounded"]
),
// 絶対パスを生成
絶対パス追加 = Table.AddColumn(
#"HTML から抽出されたテーブル",
"ImageSrcAbsolute",
each "https://scraping.okinan.com/" & Text.TrimStart([ImageSrc], "/"),
type text
),
// 型変換
変更された型 = Table.TransformColumnTypes(
絶対パス追加,
{
{"Column1", type text},
{"Column2", type text},
{"Column3", type text},
{"Column4", type text},
{"Column5", type text},
{"ImageSrc", type text},
{"ImageSrcAbsolute", type text}
}
),
削除された列 = Table.RemoveColumns(変更された型,{"ImageSrc"}),
結合された列 = Table.CombineColumns(削除された列,{"Column4", "Column5"},Combiner.CombineTextByDelimiter("", QuoteStyle.None),"結合済み"),
#"名前が変更された列 " = Table.RenameColumns(結合された列,{{"Column1", "製品名"}, {"Column2", "価格"}, {"Column3", "説明"}, {"結合済み", "ステータス"}, {"ImageSrcAbsolute", "URL"}})
in
#"名前が変更された列 "4.詳細エディターにソースコードをすべて書き換えます。
書き換え後、「完了」ボタンを押下します。

5.PowerQueryエディターに表示される情報は以下の通りです。5行目に画像のURLが追加されています。
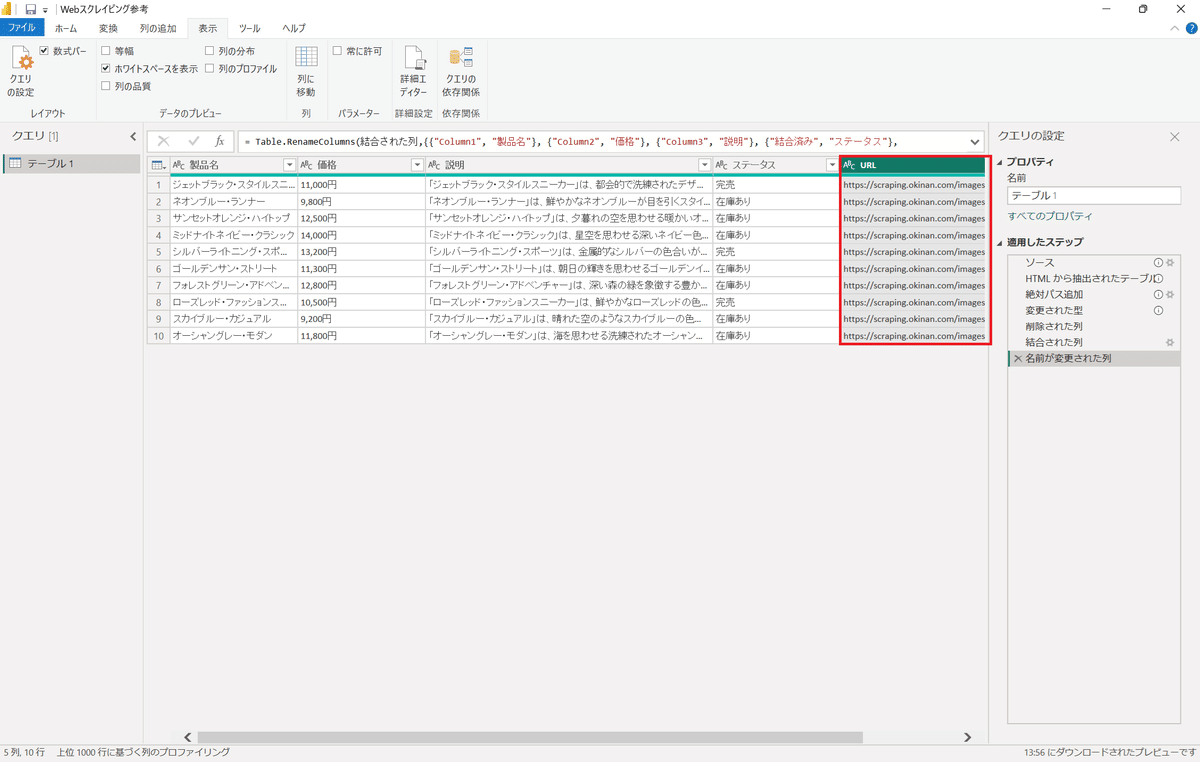
6.「ホーム」タブから、「閉じて適用」ボタンを押下する。
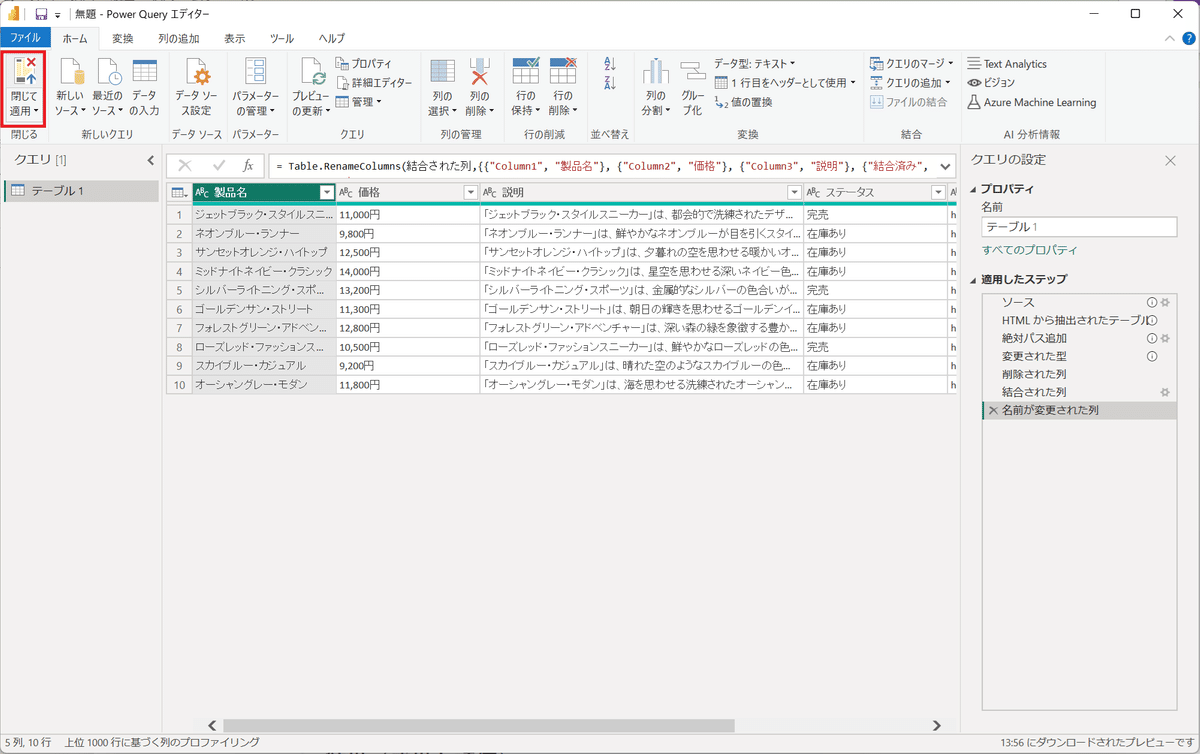
7.追加されたURLの列を選択した後、「列ツール」タブのプロパティを選択する。
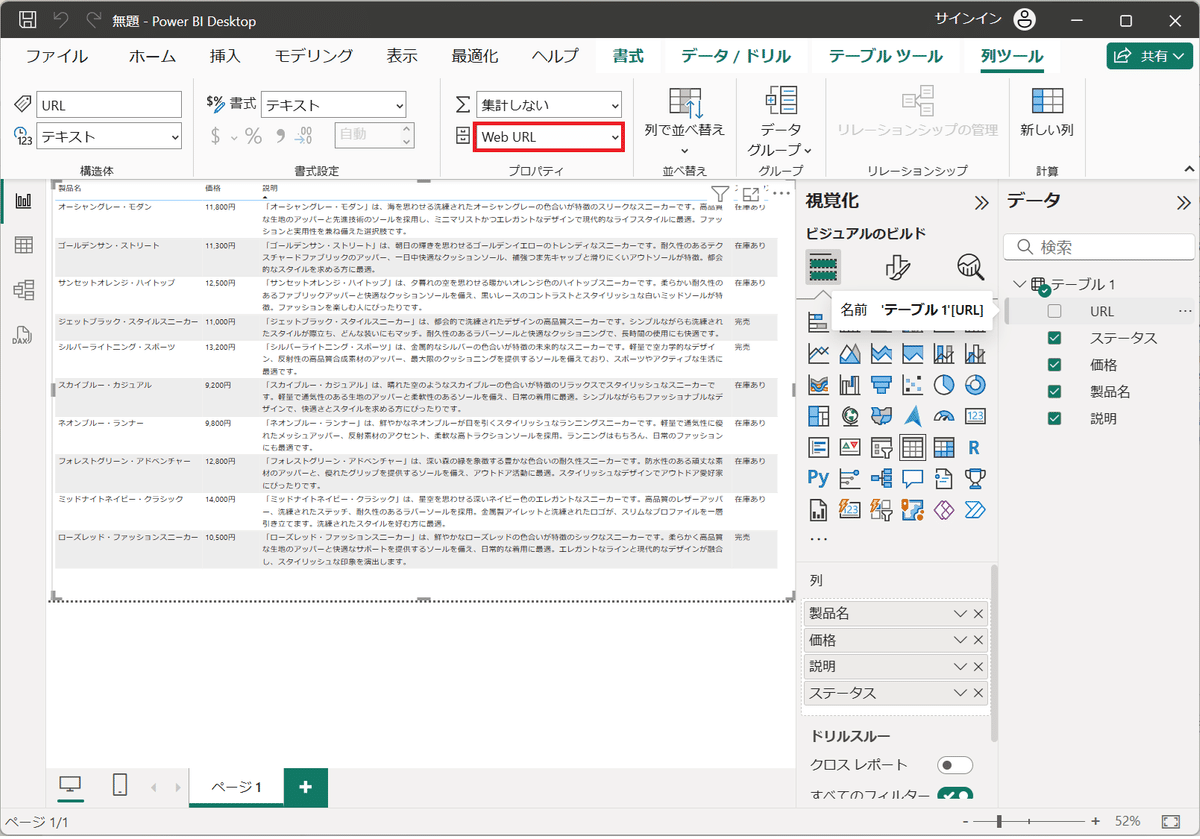
8.「画像のURL」を選択する。
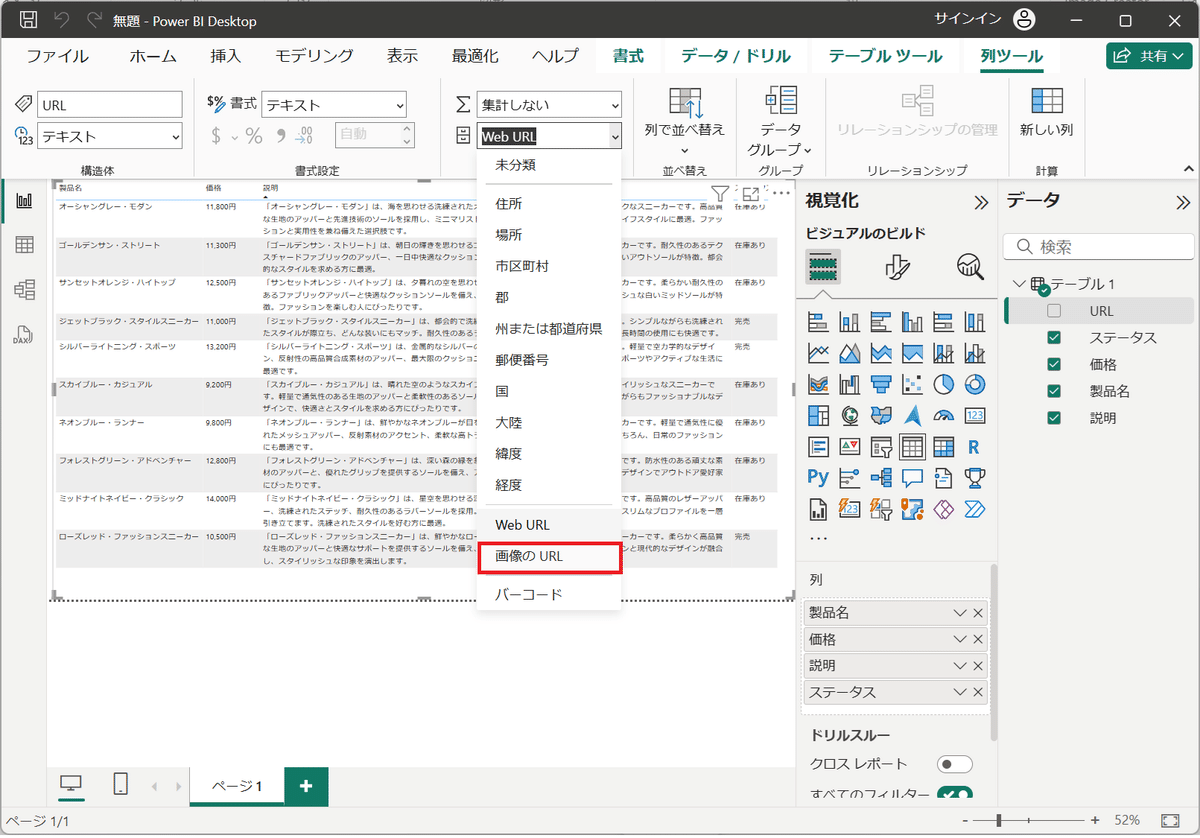
9.URLをテーブルに追加します。

10.画像が追加されたことを確認して完了です。
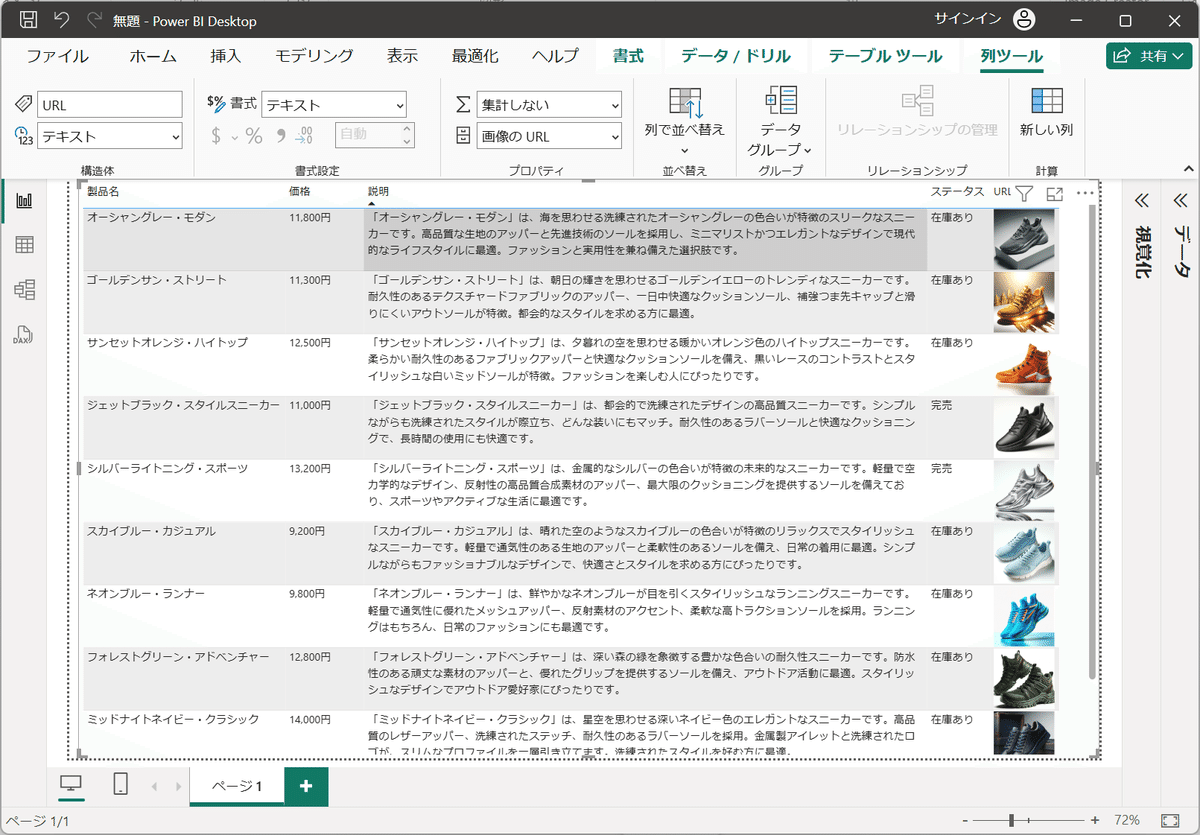
結果(成果と評価)
PowerQueryソースコードを理解して、新たにsrc属性の画像URLを取得することができました。取得した画像のURLは表の列へ画像の追加を行うことができました。
まとめ(結論と今後の展望)
Power BIを活用したWebスクレイピングは、プログラミングスキルがなくても比較的簡単に導入できます。しかし、ほしい情報を取得する場合、ソースコードの解析を行いプログラミングをする必要があります。そのため、Webスクレイピング以外にもWebAPIの検討も必要となります。
次回はWeb APIの実装を行います。お楽しみに!
いいなと思ったら応援しよう!
