
AIを使って生放送を面白くする ~他のYoutube動画の生放送から、生放送用の話題リストを自動生成する~

はじめに
どんな人におすすめ?
・プログラミング初心者
・自身でYoutube生放送をしており、効率的に話題のネタを集めたい人
・AI tuberを作ろうとしている人
・風来のシレンの生放送を考えている人(増えろ!)
・意地でも有料サービスを使いたくない方(全部無料です)
生放送している人って大抵一人で話し続けてますが、あれ異常ですよね??
普通芸人でもテレビ番組側が話題を振ったうえでボケる人・突っ込む人が居て初めて面白くなるわけで、Youtuberは3人分の役割を1人でやってるんです。しかもそのうえでゲームとかまでプレイしている。どんだけマルチタスクの化け物なんでしょうね…。
そういった強化されたコミュ力お化けの一部の方々はさておき、我々コミュ障サイドの人間はそんなマルチタスクはこなせないわけです。そうなると事前に話題セットを用意して面白くなるように工夫しないといけない訳ですが、日常生活に追われて普通はそんな余裕はないですよね?
というわけで話題セットをAIに用意してもらおうという内容です。
初歩的なプログラミングがでてきますが、私も素人なので大丈夫です。
なんかエラーがでたら、エラーをchatGPTに突っ込んで何がおかしいか聞いてください。私よりもGPTの方がよっぽど詳しいので!!!(ウィルスとかAPI keyを掠め取るようなコードはないよ!その辺もGPTに聞いて!)
⓪ pythonスクリプトを実行する方法
pythonで組まれたスクリプトを実行するには.py形式で保存して、コマンドプロンプトで起動します。え?そんな当たり前の事解説要らない?…で、ですよね~…(素人)
当たり前ですが、pythonはインストールしてください。一応私のPCではPython 3.10.6で動作しています。
① Youtube動画を検索し、字幕を抽出してテキストファイルに格納する
<できること>
・キーワードから動画リストを検索
・チャンネルIDから動画リストを検索
↓
・見つけた動画リストから指定の条件で選別
・選別した動画リストからそれぞれ字幕を抽出(まぁまぁエラーを吐く)
↓
・テキストファイルに格納する
<出来ない事>
・チャンネル名から動画リストを検索
事前にYoutube DATE v3 APIを使えるようにしておきましょう。
Googleが提供しているもので、一日の利用上限があるものの無料で使えちゃいます。いい世の中だ。
必要なライブラリをインストールしておきましょう。コマンドプロンプトで下記を実行します。
pip install langchain_community google-api-python-client isodate実行プログラムは下記になります。適当なテキストファイルなどに下記を打ち込んで、「.py」形式で(できればユーザーフォルダに)保存。
コマンドプロンプトから実行します。
from langchain_community.document_loaders import YoutubeLoader
from googleapiclient.discovery import build
from datetime import datetime, timedelta
from isodate import parse_duration
import re
import time
import sys
import os
folder_path = "(テキストファイルを保存するフォルダを指定してください)"
# YouTubeデータAPIキーを設定
yt_api_key = "(YoutubeのAPIキーを指定してください)"
# 動画の検索上限
maxnum = 100
# 何週前までさかのぼるか
beforeweek = 1
# 何分~何分までの動画を抽出するか
mintime = 30
maxtime = 180
# 何個まで保存するか
max_save_count = 5
'''
# Windowsで保存できない文字を削除する正規表現パターン
'''
def sanitize_filename(filename):
pattern = r'[<>:"/\\|?*]'
return re.sub(pattern, '', filename)
'''
テキストファイルを保存するフォルダを指定してください
'''
for f in range(5):
if folder_path == "(テキストファイルを保存するフォルダを指定してください)":
folder_path = input("テキストファイルを保存するフォルダを指定してください(空欄の場合はcurrent directory):")
if folder_path == "":
import os
# カレントディレクトリを取得
folder_path = os.getcwd()
# フォルダの存在を確認
if os.path.exists(folder_path):
print(f"テキストファイルを保存するフォルダを確認:{folder_path}")
break
else:
print(f"エラー:テキストファイルを保存するフォルダがみつかりません:{folder_path}")
folder_path = "(テキストファイルを保存するフォルダを指定してください)"
else:
print("エラー:保存するフォルダが見つかりません")
sys.exit()
'''
genaiの読み込み
'''
for f in range(5):
try:
if yt_api_key == "(YoutubeのAPIキーを指定してください)":
yt_api_key = input("Youtube date v3のAPIを入力してください:")
# YouTubeデータAPIクライアントを作成
youtube = build("youtube", "v3", developerKey=yt_api_key)
print("Youtubeクライアントの読み込みに成功")
break
except:
print("Youtubeクライアントの読み込みに失敗")
yt_api_key = "(YoutubeのAPIキーを指定してください)"
else:
print("エラー:Youtubeクライアントの読み込みに成功")
sys.exit()
# チェンネル検索モード
searchChannel = False
# 検索するワードを設定
for f in range(5):
if searchChannel == False:
search_word = input("検索するワードを入力(nを入力するとチャンネル検索へ):")
if search_word == "n":
searchChannel = True
continue
elif search_word != "":
break
else:
print("エラー:もう一度入力してください")
elif searchChannel == True:
search_id = input("検索するチャンネルIDを入力(nを入力するとワード検索へ)(※ID検索のみ):")
if search_id == "n":
searchChannel = False
continue
elif search_id != "":
break
else:
print("エラー:もう一度入力してください")
else:
print("入力がなかったため終了します")
sys.exit()
# 1週間前の日付を計算
one_week_ago = (datetime.utcnow() - timedelta(weeks=beforeweek)).strftime("%Y-%m-%dT%H:%M:%SZ")
if searchChannel == False:
# 動画を検索
search_response = youtube.search().list(
q=search_word,
type="video",
part="id,snippet",
maxResults=maxnum,
publishedAfter=one_week_ago
).execute()
elif searchChannel == True:
# 動画を検索
search_response = youtube.search().list(
channelId=search_id,
type="video",
part="id,snippet",
maxResults=maxnum,
publishedAfter=one_week_ago
).execute()
# 動画IDのリストを取得
video_ids = [item["id"]["videoId"] for item in search_response["items"]]
# 動画の詳細情報を取得
video_response = youtube.videos().list(
id=",".join(video_ids),
part="snippet,statistics,contentDetails"
).execute()
# 動画情報をリストに格納
videos = []
for item in video_response["items"]:
duration_seconds = parse_duration(item["contentDetails"]["duration"]).total_seconds()
duration_minutes = int(duration_seconds // 60) # 秒を分に変換
video = {
"id": item["id"],
"title": item["snippet"]["title"],
"likeCount": int(item["statistics"].get("likeCount", 0)),
"duration": duration_minutes
}
videos.append(video)
# 評価数で並び替え
sorted_videos = sorted(videos, key=lambda x: x["likeCount"], reverse=True)
print(f"指定したYoutube動画が{len(video_ids)}個みつかりました")
# 動画時間が30分~180分のものを抜き出す
filtered_videos = [video for video in sorted_videos if (video["duration"] >= mintime)and((video["duration"] <= maxtime))]
print(f"指定した条件でフィルター:{len(filtered_videos)}個のYoutube動画が残りました")
# 結果を表示
print("ーーーーーーーーーーーーーーーーーーーーーー")
print("抽出したYoutube動画の字幕を所得していきます")
print("ーーーーーーーーーーーーーーーーーーーーーー")
# 保存が5個になったら消える
save_count = 0
for vds in filtered_videos:
try:
print(f"字幕を所得 Like:{vds['likeCount']} Duration:{vds['duration']}min Title:{vds['title'][:25]}")
YOUTUBE_URL = "https://youtube.com/watch?v=" + vds['id']
# youtube-transcript-apiで文字起こし ====================================
loader = YoutubeLoader.from_youtube_url(
YOUTUBE_URL, # 取得したいYouTube URL
add_video_info=False, # 動画情報を取得する場合はTrue
language=["ja"], # 取得する字幕の言語指定(複数指定は取得の優先順位づけ)
translation="ja", # 字幕を自動翻訳したい場合の言語指定
)
documents = loader.load()
if documents == []:
print("何でこのエラー起きるの??")
time.sleep(3)
continue
else:
content = documents[0].page_content # 文字起こし出力
# print(content)
if content == "":
# 中身が空ならスルー
print("字幕なし")
time.sleep(3)
continue
else:
save_count += 1
# ファイル名
filename = folder_path + vds['title'][:20] + ".txt"
# ファイルを新規作成し、テキストを書き込む
with open(filename, "w", encoding="utf-8") as file:
file.write(content)
print(f"Text has been saved to {filename}.")
print("---")
if save_count >= max_save_count:
if input(f"{max_save_count}つ以上所得しています。継続しますか?(nなら終了)") == "n":
break
else:
continue
except:
print("なんかエラーだってー")
time.sleep(3)>folder_path = "(テキストファイルを保存するフォルダを指定してください)
>yt_api_key = "(YoutubeのAPIキーを指定してください)"
動画の検索上限
maxnum = 100
何週前までさかのぼるか
beforeweek = 1
何分~何分までの動画を抽出するか
mintime = 30
maxtime = 180
何個まで保存するか
max_save_count = 5
この部分は適当に書き換えてください。一応、書き換えなくても動くようにはしているはずですが…。
<実行結果>

字幕ファイルが生成されました。

中身見るとすごいことなってます。こんなの読んでられないのでAIに頼って解析しましょう。

※※番外編※※
ちなみに自力で出来ない人のためにnottaっていう自動文字おこし&要約サービスもあるようです。
試そうとしたら、1時間を超えたらプレミアムプランって言われたので利用はしてません。
➁ 先ほどの字幕集をGoogle Gemini APIで解析して、他の生放送で出てきた話題を抽出する
<できること>
・先ほどテキストファイルに格納した長文の字幕を1000文字(chunk_sizeで設定)ごとにgeminiで解析し、「【話題】〇〇【意見】××」の形式に変換する
↓
・新しいテキストファイル(wadai.txt)に格納する
解析するAIにはGoogleが提供するGeminiのAPIを使います。こいつはchatGPT 3.5程度の性能ではありますが、GeminiのAPIは年末からずっと無料期間が続いていて、2024年3月29日現在でもなぜか無料で使えてます。
事前にgoogle.generativeaiはインストールして、APIの登録も行って、geminiを使えるようにしておいてください。案外簡単です。
同じような安価のテキスト型AIでこれよりやや高性能のClaude3 haikuもあまりに安すぎてログインボーナスだけいくらでも使い倒せちゃうのでgeminiの無料セールが終わったらこちらに乗り換えてもいいでしょう。
やっぱり必要なライブラリをインストールしておきましょう。コマンドプロンプトで下記を実行します。
pip install google-generativeai実行プログラムは下記になります。適当なテキストファイルなどに下記を打ち込んで、「.py」形式で(できればユーザーフォルダに)保存。
コマンドプロンプトから実行します。
import sys
import os
import re
import google.generativeai as genai
folder_path = "(テキストファイルを保存したフォルダを指定してください)"
genai_api = "(geminiのapi_keyを入力してください)"
# 字幕を何文字ごとに分割するか
chunk_size = 1000
# 保存するテキストファイル名
save_filename = folder_path + "//wadai.txt"
'''
テキストファイルがあるフォルダの確認
'''
for f in range(5):
if folder_path == "(テキストファイルを保存したフォルダを指定してください)":
folder_path = input("テキストファイルを保存したフォルダを指定してください(空欄の場合はcurrent directory):")
if folder_path == "":
import os
# カレントディレクトリを取得
folder_path = os.getcwd()
# フォルダの存在を確認
if os.path.exists(folder_path):
print(f"テキストファイルを保存したフォルダを確認:{folder_path}")
break
else:
print(f"エラー:テキストファイルを保存したフォルダがみつかりません:{folder_path}")
folder_path = "(テキストファイルを保存したフォルダを指定してください)"
else:
print("エラー:保存するフォルダが見つかりません")
sys.exit()
# 保存するファイルの確認
try:
if os.path.isfile(filename):
print(f"保存するテキストファイルを確認:{filename}")
else:
filename = folder_path.rstrip("/\\") + "//wadai.txt"
print(f"保存するテキストファイルがみつからないので変更します:{filename}")
except:
filename = folder_path.rstrip("/\\") + "//wadai.txt"
print(f"保存するテキストファイルがみつからないので変更します:{filename}")
'''
genaiの読み込み
'''
for f in range(5):
try:
if genai_api == "(geminiのapi_keyを入力してください)":
genai_api = input("geminiのapi_keyを入力してください:")
genai.configure(api_key=genai_api)
model = genai.GenerativeModel('gemini-pro-vision')
modeltext = genai.GenerativeModel('gemini-pro')
print("genaiモデルの読み込みに成功")
break
except:
print("genaiモデルの読み込みに失敗")
genai_api = "(geminiのapi_keyを入力してください)"
else:
print("エラー:genaiモデルの読み込みに失敗")
sys.exit()
'''
genaiを使う
'''
def useGemini(prompt):
safety_settings=[
{ "category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE" },
{ "category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE" },
{ "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE" },
{ "category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
generation_config={
"temperature": 1,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 1024,
}
response = modeltext.generate_content(
[prompt],
safety_settings=safety_settings,
generation_config=generation_config
)
resultstr = response.text
return resultstr
'''
正規表現を用いて、話題と意見の形式を整える処理を行う
'''
def format_string(text):
# 正規表現パターン
pattern = r'(?:【話題】|話題[::])(.*?)(?:【意見】|/意見[::])(.*)'
# 正規表現で文字列を分割
match = re.search(pattern, text, re.DOTALL)
if match:
topic = match.group(1).strip()
opinion = match.group(2).strip()
if (topic == "") or(opinion == "") :
print("☆☆☆☆☆話題と意見が上手く返されていない☆☆☆☆☆")
return None
else:
return f"【話題】{topic}【意見】{opinion}"
else:
print("☆☆☆☆☆話題と意見が上手く返されていない☆☆☆☆☆")
return None
'''
ーーーーーーーーーーーーーーーーーーーーーーーー
ここからメイン処理
ーーーーーーーーーーーーーーーーーーーーーーーー
'''
# テキストファイルを格納するリスト
file_titles = []
text_files = []
# フォルダ内のファイルを走査
print(f"読み込んだテキストファイルを表示")
for filename in os.listdir(folder_path):
try:
# ファイルの拡張子が.txtの場合のみ処理
if filename.endswith(".txt"):
file_path = os.path.join(folder_path, filename)
print(file_path)
# テキストファイルを読み込む
with open(file_path, "r", encoding="utf-8") as file:
text = file.read()
# テキストファイルの内容をリストに追加
text_files.append(text)
file_titles.append(file_path)
except:
if input("余計なテキストファイルがあります。継続しますか(nで終了):") == "n":
sys.exit()
else:
continue
# 読み込んだテキストファイルの数を表示
print(f"合計{len(text_files)}個")
resultlist = []
for f, text2 in enumerate(text_files):
print(f"{f+1}目のテキスト")
print(f"タイトル:{file_titles[f]}")
print(f"文字数:{len(text2)}")
# テキストをchunk_size文字ごとに分割
text_chunks = [text2[i:i+chunk_size] for i in range(0, len(text2), chunk_size)]
# 分割されたテキストチャンクを処理
for ff, chunk in enumerate(text_chunks):
if chunk != "":
prompt="下記のセリフをもとに現在の話題とそれに対するあなたの意見を50文字以内でまとめてください。 /n 必ず、【話題】〇〇【意見】~~ の形式にして改行しないでください。/n-----------/n会話文:" + chunk
resultstr = useGemini(prompt)
# 改行を削除
resultstr = resultstr.replace("\n", "")
resultstr = format_string(resultstr)
if resultstr != None:
print(f" Chunk {ff+1}:{resultstr[:50]}")
resultlist.append(resultstr)
else:
print("中身が空欄")
# テキストファイルに追記する
with open(save_filename, "a", encoding="utf-8") as file:
for content in resultlist:
file.write(content + "\r\n")
print(f"Text has been saved to {filename}.")
print("ーーーーーーーーーーーーーーーーーーー")この辺の設定はパソコンごとに変えてください。
folder_path = "(テキストファイルを保存したフォルダを指定してください)" genai_api = "(geminiのapi_keyを入力してください)"
# 字幕を何文字ごとに分割するか
chunk_size = 1000
# 保存するテキストファイル名
save_filename = folder_path + "//wadai.txt"
あとプロンプトもそれぞれに合った形式で変えてみてください。下の方にあります。
prompt="下記のセリフをもとに現在の話題とそれに対するあなたの意見を50文字以内でまとめてください。 /n 必ず、【話題】〇〇【意見】~~ の形式にして改行しないでください。/n-----------/n会話文:" + chunk
使用した字幕のテキストファイルを削除したりはしないので適当に捨ててください。
<実行結果>

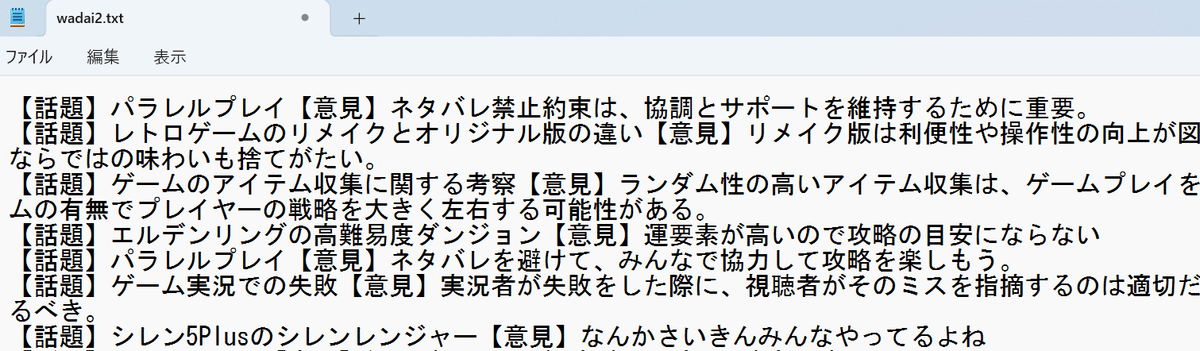
字幕を何文字ごとに分割するかの設定であるchunk_sizeや要約の仕方であるプロンプトを変えればもっと細かく抽出できるとは思います。
大事なこととして、あくまでこの結果は、ほかの生放送で出た話題を効率的に抽出したにすぎません。
興味ない話題が出ても嫌ですし、最終的にはヒトの目で取捨選択した方がいいでしょう。
①'➁' X(旧Twitter)から力技で話題リストを作成する
似たような内容ですがこちらの記事をどうぞ
③ 生放送中にAIに話題を振らせる
話題リストを用意してカンペ形式で読み上げていってもいいですが、生放送中にAIが話題降ってくれたらもっとやりやすいですよね。
やはり日本人たるもの大衆に向けて発信するのは苦手で、会話形式じゃないとろくにしゃべれないんですよ…!! ゆっくりしていってね…!!!!
そのシステムも作っていますが、この記事で解説するにはあまりに膨大なので他の記事で一緒に書きます。
何の意味もない画像を最後に置いておきます。
うちの新キャラふわふわちゃんです。
